
Today we have the launch of the Ampere Altra Arm CPUs. This is a completely new design built specifically for cloud providers. It has up to 80 cores and is designed to go head-to-head with AMD EPYC 7002 “Rome” series processors as well as 2nd Gen Intel Xeon Scalable Refresh parts. Ampere is launching today but we do not have a test system as we have had for all of the other major server chip launches recently. It sounds like Ampere is shipping mass production units soon, but not at the time we were briefed. Hopefully, we can get more hands-on insights in the near future.
The Ampere Altra has shed the eMAG naming and development cadence. Instead, Ampere is already developing its 2021 generation Mystique as well as starting work on its 2022 Siryn processors. This is important because one area Arm vendors, or perhaps better said, non-Intel vendors need to continually show customers. There is a roadmap and new generations are coming. Perhaps the standard in a year may end up being AMD’s roadmap while Intel needing to prove its cadence if Ice Lake Xeons are delayed into 2021.

In this article, we are going to discuss the architecture based on the documents we have and our discussion with the company. We are going to check performance claims and help our readers critically analyze what they are being shown. We are then going to discuss systems disclosed with the chips before getting to our final thoughts.
Introducing the Ampere Altra Architecture
Here are the highlights for the Ampere Altra including the 80 core maximum and a cache-coherent mesh interconnect. One will also notice that this is a monolithic 7nm die. This is still the norm while most companies are talking about multi-die approaches going forward.

Perhaps the biggest feature aside from the core counts is that it uses a cache-coherent multi-socket design. In other words, while eMAG was a single-socket part, this is a dual-socket capable part. That has enormous implications. Dual socket servers amortize shared costs across more sockets which has made them the de-facto standard in the industry. This is a feature Ampere needed to have and they delivered.
The Ampere Altra can have up to 80 64-bit Arm v8.2+ cores and feature out-of-order execution. It was not long ago when the Arm chips trying to compete with mainstream Xeon were still in-order. The v8.2+ is there because Ampere pulled in features from future feature sets to make a better processor today. If you take 80x 1MB per core caches plus 32MB as the last level cache, one gets 112MB. This continues the trend of much higher cache levels than current Xeon Scalable mainstream CPUs that top out at around half that figure. AMD for its part has 256MB in L3 cache for its 64-core parts in this generation.

Not on these slides, however important, is that Ampere is citing up to a 210W TDP for the 80 core parts. We also asked and they are socketed parts, not BGA like we saw some other Arm server offerings. The market prefers flexibility of socketed processors even with extra cost and space requirements so this is an important feature for Ampere to have.
Perhaps the most interesting feature is that this is a single-threaded core. Intel and AMD offer SMT cores (Hyper-Threading for Intel) with two threads per core on current generations of mainstream Xeon and EPYC CPUs (excluding the Xeon Bronze from the discussion.) Ampere contends that by removing SMT, it can increase QoS by lowering resource contention, leading to predictable performance.

Ampere is billing this as a cloud provider feature by saying it reduces noisy neighbor effects. Intel has had to do a lot of work on this since Xeon E5 and Xeon Scalable chips tend to throttle when some of the cores move to AVX2/ AVX-512 execution. Other examples are when the processors thrash caches and memory/ I/O access. For a cloud provider, you want a product that is as uniform as possible, so this makes sense from that standpoint.
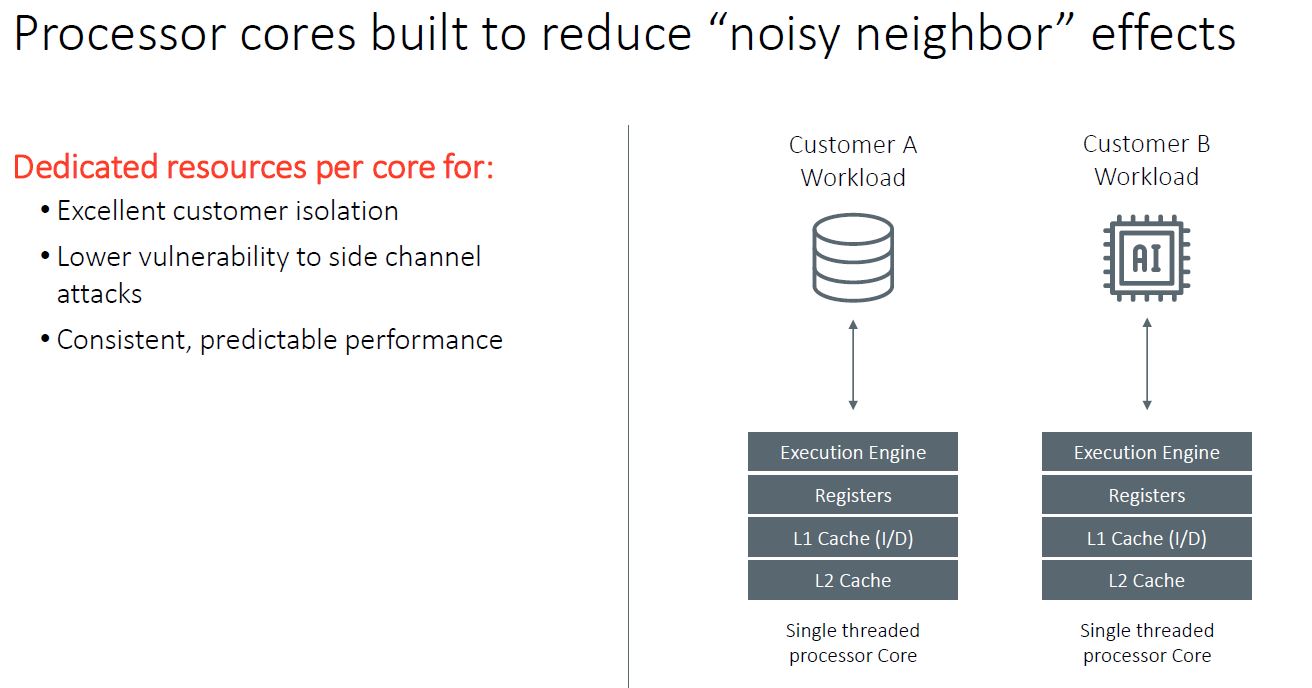
Another benefit is that without SMT, it provides better isolation and potentially a lower vulnerability footprint as we saw with Foreshadow / L1TF on Intel Xeons. As a quick aside here, the Marvell ThunderX2 can utilize SMT=1, SMT=2, SMT=3, and SMT=4.
In terms of memory, the Altra supports DDR4-3200 with up to 8 channels of memory in 2 DPC mode for up to 4TB of memory. This is analogous to the AMD EPYC 7002 series. Compared to Intel Xeon Scalable “Cascade Lake” it is 33% more DIMM slots per CPU and higher clock speeds (3200 v. 2933.) While Intel’s mainstream SKUs support up to 1TB of memory, it also has “L” SKUs that support up to 4.5TB using Optane DCPMM. There was a mid-2TB level SKU but those 2nd Gen Intel Xeon Scalable M SKUs are discontinued.

Ampere also has another very AMD EPYC 7002 series-like feature. It has 128 PCIe lanes per CPU. It then utilizes 32 of those lanes for a 2P system using CCIX for the cache coherent interconnect. AMD EPYC 7002 technically can support this 192x PCIe lane 2P configuration but AMD only officially supports 160 PCIe lane (48x Infinity Fabric lane socket-to-socket) or 128 PCIe Gen4 lane (64 IF lane socket-to-socket) configurations. If a large customer such as Google, Amazon, Facebook, or Microsoft requested a 192x PCIe Gen4 lane configuration, AMD could support this (we have seen that it works), but apparently that request has not arrived so AMD is still at 160x PCIe Gen4 lane configurations. It is interesting that Ampere is only utilizing 32 lanes for socket-to-socket communication since it seems that cloud providers have not pushed AMD for something similar.

Ampere is using CCIX here. Once Arm joined CXL it seems as though the PCIe Gen5 path is going to involve a lot of CXL. Still, Arm said it would continue to support CCIX and this is a good reason why.
Ampere supports SBSA level 4 along with many other important management features for the cloud and general-purpose server markets.

Overall, it is hard not to get excited about this new design. It is truly something different than what we are seeing in the x86 world. That is what Ampere needs to do if it wants to compete since offering something similar is not going to be good enough to force change.
The next question is how this chip performs and how that drives TCO.
Ampere Altra Performance Estimates
We want to talk about the Ampere Altra performance estimates because they are important. Ampere is releasing some relative performance numbers. As with any competitive performance disclosure, it is important to read the endnotes to provide context. If you are reading an article on Altra and it is showing the performance without discussing the baseline conditions and assumptions, then you are not getting the whole story. For marketing purposes, important information is put on slides outside of the main presentation because many publications do not care to glance at them.
First, Ampere is claiming performance from its parts in excess of the dual AMD EPYC 7742 by a small margin. That is AMD’s second-highest performing EPYC part behind the HPC focused AMD EPYC 7H12 but it is also AMD’s highest-end mainstream SKU. Ampere Altra is also claiming a massive estimated Specrate2017_int_base figure over the dual Intel Xeon Platinum 8280 configuration. As we discussed in our Big 2nd Gen Intel Xeon Scalable Refresh piece, Intel has a new Xeon Gold 6258R which is a better comparison point now. While we expect the Xeon Gold 6258R to perform like the Xeon Platinum 8280, comparable numbers have not been published. Ampere, to its credit, is not using the Platinum 8280 list price so this is well done.
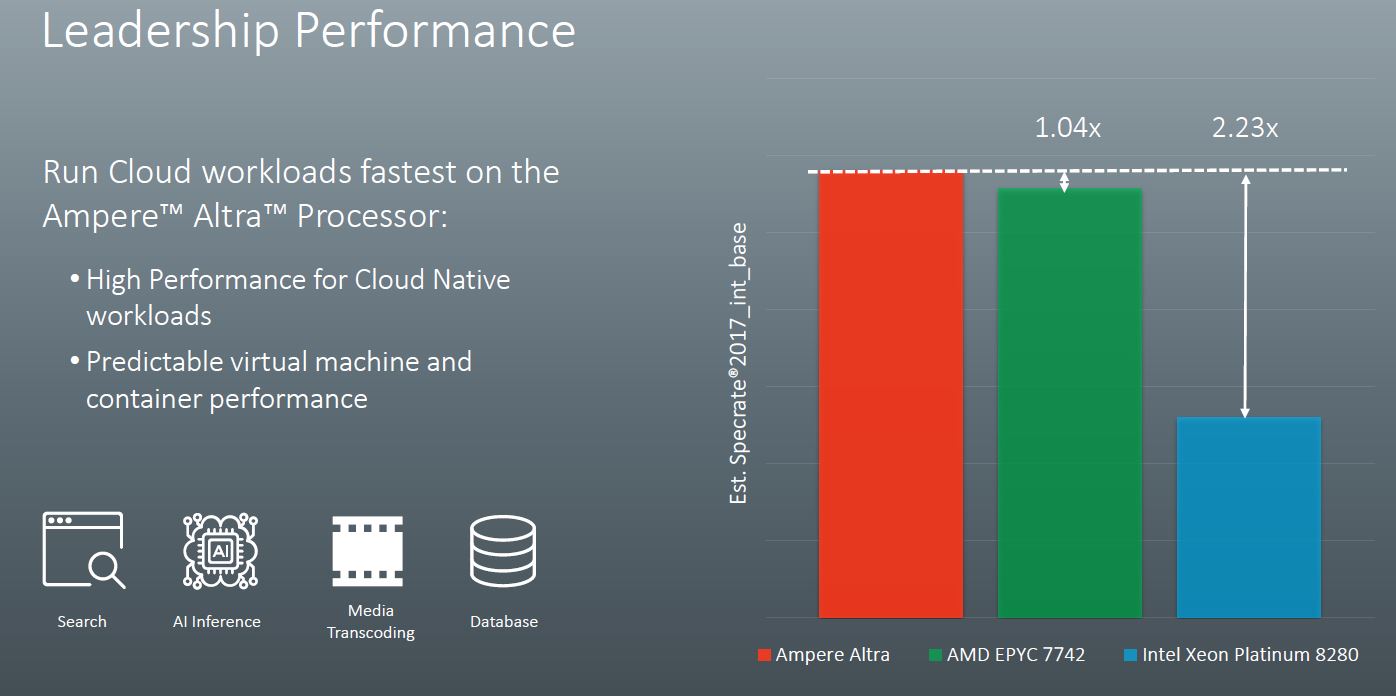
When we get to the endnotes, we see how Ampere got to these figures. The Altra part is a dual-socket 3.3GHz platform using GCC 8.2. Ampere did not disclose the TDP here but that is OK at this point. What we will note is that Ampere de-rated both the AMD EPYC 7742 and Xeon Platinum 8280 results by 16.5% and 24% respectively. This was done to adjust for using GCC versus AOCC2.0 and ICC 19.0.1.144. Ampere disclosed this, and it is a big impact. Arm servers tend to use GCC as the compiler while there are more optimized compilers out there for AMD and Intel. For some reference point that is why we showed both optimized and GCC numbers in our large launch-day ThunderX2 Review and Benchmarks piece.

This de-rate practice for ICC and AOCC is common in the industry and Ampere disclosed it clearly. We will note that while it is not enough to tip the balance on the Xeon side, it does mean that the 2019-era AMD EPYC 7742 can provide more performance than the future 2020-era Ampere Altra 3.3GHz.
Ampere in the slides above states that the Altra has a 3.0GHz maximum turbo. It is interesting that they are using a part here that is running at 10% higher clock speeds, especially with a 4% lead over AMD.
When looking at TCO, Ampere uses lower-power parts which are the AMD EPYC 7702 and the Intel Xeon Gold 6238R / Xeon Platinum 8276. When we did our briefing it was just before the “Refresh” was announced. Great job here by the Ampere team to update its presentation. The Platinum 8276 is now positioned as a 4-socket and 8-socket solution so it is no longer a practical competitor to the Altra.
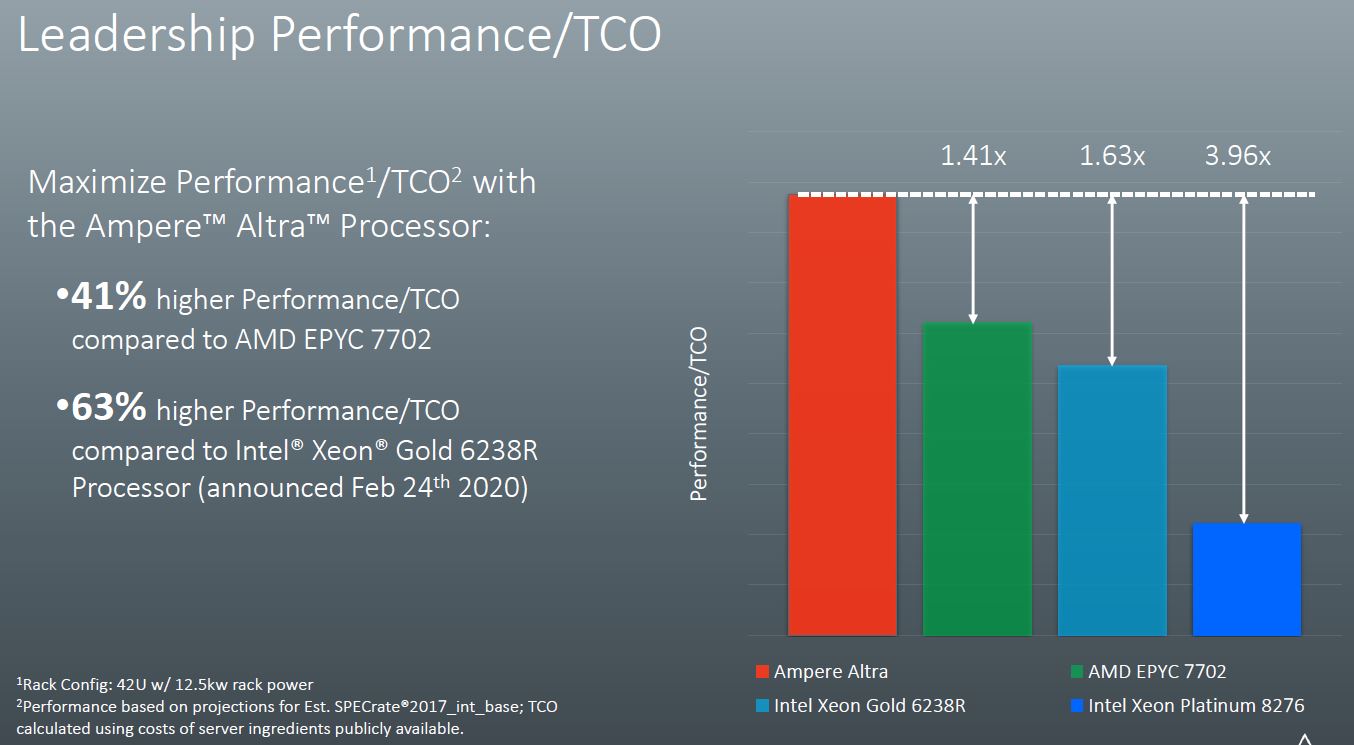
Ampere then uses the TDP and a 12.5kW rack to show scalability. TDP is off so far compared to actual power consumption between AMD EPYC and Intel Xeon that this is probably not the best way to compare. We would have rather seen Ampere use actual power as it would change the results quite a bit.
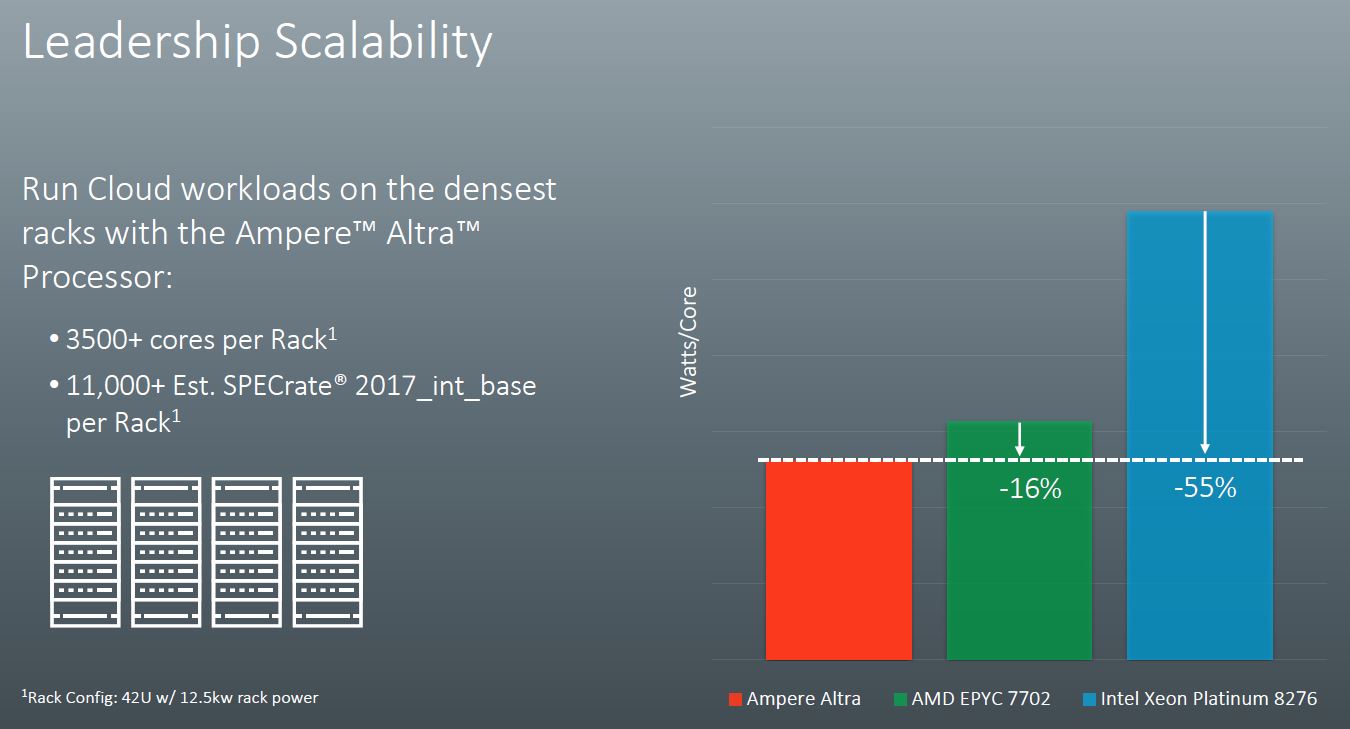
Looking at the endnotes, again Ampere is using the GCC conversion factor. Again, this is an industry practice, and there are good reasons for it. We just want our readers to be aware.

Ampere then says that this leads to better density per rack.

What is completely missing from all of the performance numbers is floating-point performance. One can rightfully argue that most cloud workloads rely upon integer performance more than floating-point performance. Still, there are workloads that are mixed so that seems like an important piece of the puzzle with both AMD and Intel pushing performance in those areas. Ampere is being forthcoming with the disclosures, but not including any FP performance figures makes one wonder if the performance claims are similar in mixed and FP-heavy workloads.
Launch Systems
Ampere has two systems, a 2U dual-socket platform, and a 2U single-socket platform. The dual-socket platform does not have a vendor name on it, although Lenovo has a quote in the press release. You can see it looks quite a bit different from the Lenovo ThinkSystem SR650 we reviewed. Ampere declined to name the vendor, but we would expect that if this is not a Lenovo system that Lenovo will have one at some point. We also heard of a Wiwynn SV328 server that supports 2P Ampere Altra with up to 192 PCIe Gen4 lanes and up to 8TB of DDR4-3200 memory in 32 DIMM slots. For those unfamiliar with Wiwynn, see The $5B Server Vendor You Probably Have Never Heard Of Wiwynn, and Where Cloud Servers Come From Visiting Wiwynn in Taipei.

The other platform is a Gigabyte single-socket platform that looks similar in many ways to the Gigabyte R272-Z32 we reviewed. Gigabyte has been extremely aggressive with their Arm systems. Years ago we saw a Gigabyte Annapurna Labs ARM storage server. We also have used Gigabyte servers in the ThunderX(1) and ThunderX2 eras.
These seem to be earlier systems. Some of our readers will note that if those are the only two current platforms, then they are not achieving the rack density numbers stated above. We would caution against this line of thought since there are many hyper-scale customers that do not discuss their designs openly.
Final Words
Let us be clear, this is a huge step forward from eMAG. It is also an important milestone for the Arm server market. This is a much more competitive part than previous iterations. If Arm is going to take sockets from Intel and AMD as primary server CPUs, this is a step in the right direction.
Looking ahead, AMD says that its next-gen “Milan” architecture is due out later this year. Since AMD has EPYC 7002 “Rome” systems already shipping and greater system diversity, and Ampere Altra is not shipping in the same quantity yet, the real competitor to Altra from AMD will be Milan.
On the Intel side, things are more complicated. Intel has committed to releasing Ice Lake Xeons with 10nm technology, PCIe Gen4, and new features in 2020. It also has Cooper Lake coming in the interim. Most likely we will see Ampere compete with 2nd Gen Xeon Scalable, Cooper Lake Xeons, and Ice Lake Xeons over the next 12 months. Ampere with its 8-channel DDR4-3200 memory controller and 128x (1P) or 192x (2P) PCIe Gen4 lanes per CPU, along with 80-cores should be well-positioned with a competitive offering.
We certainly applaud the Ampere team on this milestone. Bringing a new Arm server chip to market has proven to be a difficult task in the past. Showing that it can innovate bringing new features to market and that it has a roadmap going forward is important.



{kind=link}
If STH doesn’t have it it’s vaporware.
Patrick, i’m surprised you didnt call out some of their marketing bullshit. They didnt implement SMT so they could achieve “predictable performance”, yet they also implemented turbo boost which would cause this performance to become wildly unpredictable as the chip speeds up and then throttles itself.
@Muh Fugen – even with varying clock, performance is still perfectly predictable as an IPC metric
How do you define predictability (which to me is not only impacted by SMT, especially in multi-tenancy environment).
They didn’t get you guys one? I mean you’re like 1 of 2 sites in the world people look to for server CPU launches lately. They’re hiding terrible performance.
@DGO, Trying to say that the lack of SMT provides predictable IPC is absolutely absurd. The thread scheduling performed by SMT is analogous to the process and thread scheduling provided by a kernel. Its the same as saying that by doing everything in the kernel and having no user space applications, that you are delivering predictable performance, you’re not. When the number of cycles vary wildly over time, it is impossible to predict performance, especially in the way their infographics imply. They’re marketing is talking about being predictable in the range of a few clock cycles.
@am, it isnt how I define it, it is how their marketing graphics define it. absolute time spent performing a calculation, from start to completion.
@Muh Fugen – not really, SMT is a hardware black box that “just works” and you have no control over it other than enable or disable, whereas thread scheduling is software controlled, where you can either go cooperative or preemptive, and there are certainly many reasons to need finer control and predictability in the market space this product is aimed at.
I am not saying they aren’t marketing hyping it out of proportion, people do have a tendency to present certain weaknesses of their as strengths.
I am just saying both of your comments are factually wrong and indicate insufficient knowledge in the area you are rushing to comment on, putting your motivation to do so in question. I already explained how SMT is different from kernel level multitasking, and nobody makes performance prediction based on absolute time, the time unit of digital machines is their clock cycle, which also allows to trivially translate that into absolute time for any desired cycles per second target.
I’m guessing SBSA stand for Secure Boot System Architecture(?)
@DGO: A more valid criticism is that thread isolation is impossible when L3 cache and beyond are being shared. Arguably, the effect of L3 evictions due to noisy neighbors or DRAM bandwidth/latency degradation is a stronger effect than SMT which only hurts a compute-bound pair of threads (both have useful work and complete for same resources). When both are stalled on L3 or beyond, SMT only helps. Obviously, marketing is making a virtue out of a necessity.
Simpler cores are intrinsically better for time-critical performance. That’s why 8bit MCUs are still being made, and sell at around the same price as Arm MCUs that can run circles around them in terms of performance and features. 8bit MCUs are king of general purpose real-time control, due to their simplicity and resulting predictability, as long as you can go with the low computational throughput.
So their Spec comparison numbers are bogus, they are not using correct numbers of Xeon and EPYC but instead decreased those numbers by some constant taken from hat.
And then claiming to have “leadership peformance”.
When they have worse compiler that gives them worse performance in Spec, then they should either show the correct numbers where they lose, or now use SPEC at all. Posting “leadership performance” slide based on false numbers is really dishonest.
@Heikki Kultala: I agree.
Whilst discounting compiler efficiency is valid in academic circles to compare pure hardware merit, in practice you need a compiler to run anything so no customer would ever see the advertised performance benefits. In a ‘marketing release’ targeting users and buyers, academic performance has virtually no value and is just misleading. I think the furthest you could push that without being underhand would be to show both sets of result.
Its like saying the engine in a Range Rover is awesome, and if it was as aerodynamic as a sports car it’d go really fast, so we’ll compare that mythical beast to other sports cars and show you that a Range Rover is a really good sports car….
Kudos to Ampere for releasing a significant part streets ahead of the eMAG. But I don’t think their marketing is doing them any favors… they’re trying too hard and raising too many suspicions – performance metrics, high PCIe lanes but strangely low lanes for socket-socket communication, no base clock given and performance based on a boost clock that’s 10% higher than they say the part can do, a rather convoluted explanation on why SMT is not supported that tries to show that SMT is simply not a good idea (agreed SMT is not always a benefit, so turn it off if that’s how your use case likes it….) rather than admit they deliberately excluded it in favor of higher single-tread core count or whatever the REAL reason is they left it out, TDP not actual power for a rack analysis……
Either marketing needed to do this to make the part look at all interesting – in which case it’ll stir up some hype, waste a load of time and energy across the industry and ultimately go nowhere till the next generation maybe lives up to the hype. Or, its unnecessary and the part really is pretty exciting – in which case the marketing is just pointlessly covering it all in a shroud of suspicion right out the gate.
Everyone knows marketing has a big chunk of exaggeration as key requirement, and is used to filtering that, but this seems to be sliding just a little bit over the line into ‘dishonest’ and to me just leaves an air of suspicion rather than excitement.
How is this chip as a monolithic die supposed to be competitive?
Comments are closed.