
This is becoming a pattern. Today, the US Department of Energy announced the infrastructure for El Capitan. El Capitan will be installed at Lawrence Livermore National Lab only a few hours drive from Yosemite National Park and the famous El Capitan granite rock formation famous with rock climbers. HPE and its recently acquired Cray HPC shop have now completed a clean sweep of all three initial exascale systems including Aurora and Frontier. Keeping score, while Summit used IBM Power and NVIDIA Tesla to power the #1 system at about 0.2 exaflops, they have been shut out of the first three exascale systems that are all 5-10x that speed. Intel has one system with its future Intel Xe HPC GPU. AMD now has two systems where they are providing CPUs and GPUs. HPE’s Cray Shasta platform underpins all three systems.
El Capitan Rises with Next-Gen Gear
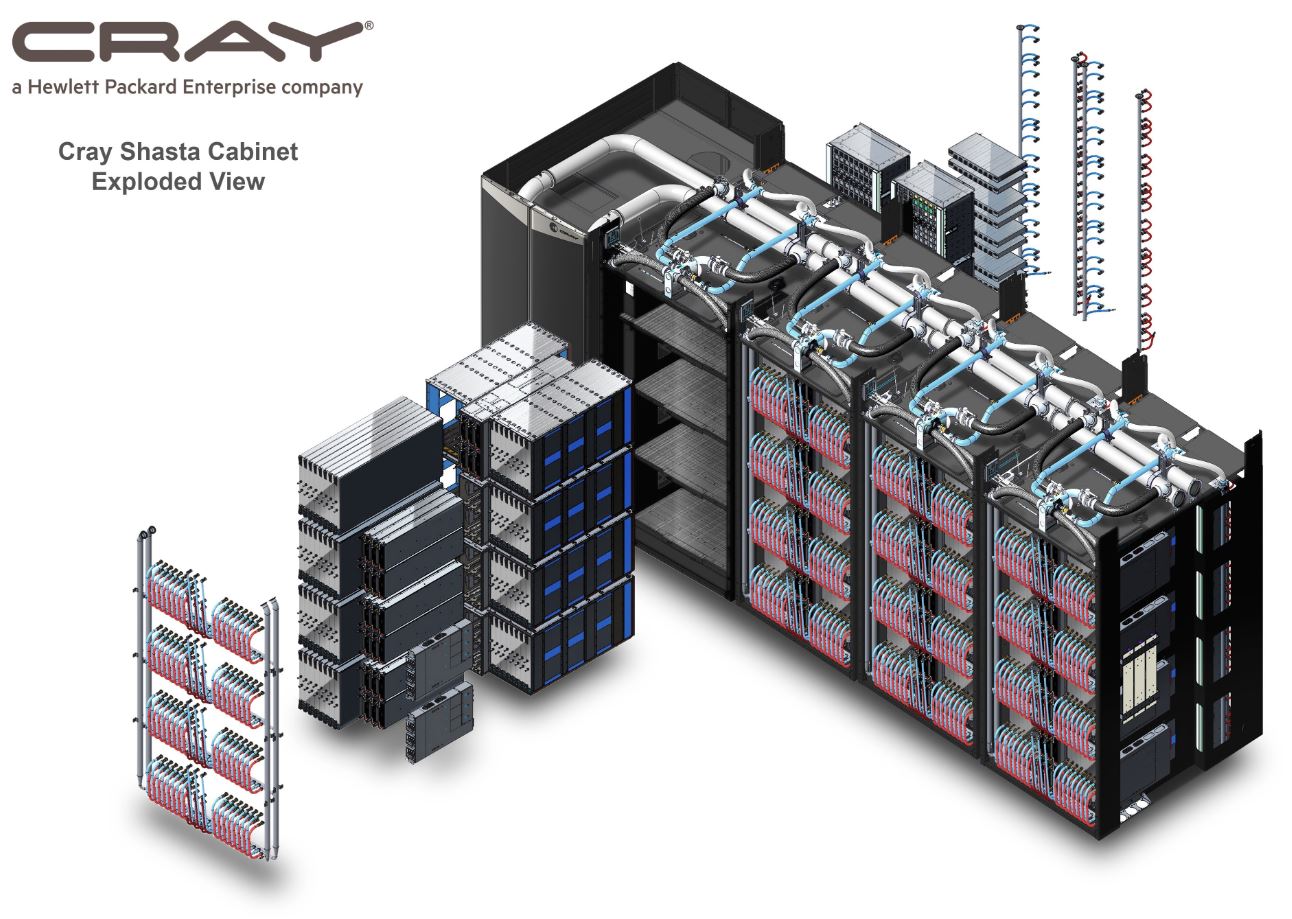
Not to be outdone by the El Capitan Yosemite reference, the Cray Shasta platform has a northern California climbing landmark with its namesake, Mount Shasta. The HPE-Cray Shasta platform is designed to be a high-density, liquid-cooled, platform that can tackle the operational needs of a system this scale. By scale, the announcement is at the 2 exaflop performance range or about 10x what the current #1 system Summit offers. The current #2 is Sierra a 0.125 exaflop system.
This system will go into an existing data center floor space at LLNL. The facility will add power moving from 45 megawatts to 80 megawatts of power capacity and additional cooling for the system.
The US DOE’s El Capitan will use next-generation AMD EPYC processors, codenamed “Genoa” featuring an upcoming “Zen 4” processor core.

It will also utilize next-generation AMD Radeon Instinct GPUs with a new compute-optimized architecture.

The HPE-Cray Shasta platform will utilize compute blades with 4:1 GPU to CPU ratios. We saw these compute blades for the last two years at Supercomputing 18 and 19. One can see the cooled memory and CPUs. The PCBs on top of some of the CPU blocks are Slingshot NICs.

HPE’s Pete Ungaro said that if all of the El Capitan compute blades were laid atop one another, the stack would be three times larger than the El Capitan in Yosemite.
AMD’s coherent Infinity Architecture for communication in each Shasta node.

Shasta nodes are being tied together with Cray Slingshot technology which has supplanted Mellanox Infiniband and Intel Omni-Path efforts to gain share in exascale systems.

There is a lot going on here and by the future, the companies mean that this system is expected to be delivered in around three years and the early 2023 timeframe. By then, we expect technologies such as PCIe Gen4 will go from their early adoption period today to previous-generation technology as systems move to faster and newer I/O.
Final Words
This is clearly big news for HPE and its Cray acquisition. Assuming they deliver, they now have, by far, the best HPC credentials in the industry. For NVIDIA, this is a huge loss. After touting HPC credentials they went 0 for 3 in their next exascale platform bids. For AMD, this is a big win as many had speculated El Capitan would be an IBM POWER/ NVIDIA Tesla machine to give all three vendors some work. Instead, AMD comes away with two enormous system wins.

For HPE, it is looking like the Cray acquisition provided something unique. The new Slingshot architecture seems to be the key differentiator in the market which is winning deals. Dell EMC’s HPC side, for example, typically uses Mellanox, which NVIDIA hopes to acquire. Mellanox now has gone 0 for 3 as well after being the defacto standard in the last few generations of large machines including Summit. NVIDIA is likely going to face a lot of questions about their strategic direction if their next-generation GPUs and their proposed interconnect solution have all gone 0 for 3. HPE clearly saw the value in the Shasta architecture and Slingshot interconnect and is racking up wins as a result.
Perhaps the bigger impact aside from the commercial and technical aspects is that this system as being billed as a way to simulate experiments so that nuclear testing can occur without having to do real-world testing. That is a somewhat morbid reason for such a large machine, but on the other hand, if the work is going to happen, it is probably better that it happens in a computer rather than as a live experiment. El Capitan will be specifically targeted for classified work and will not be available to the broader scientific community. There will be a “smaller clone” of El Capitan that does not have a name that will be available for the broader scientific community. This smaller system should be faster than the current #1 Summit supercomputer. At the press conference, we did not get the name of this smaller machine.



{kind=link}
Dear Patrick, thanks for the great article!
Great win for AMD, as a HPC user I am highly intrigued to see their software support evolve & mature with the software component of the Frontier & El Capitan contract. Can it catch up to CUDA?
Hi Patrick and thanks for your report ??
Am I missing something to think it’s natural for a solitary winner to emerge from any competition involving a small number of trials in which in every case advantage and disadvantage is multiplied by the duration of the race and the duration is being constantly increased and all races are scheduled for the interval between generations and so no runner is expected to race with different performance during the competition?
Furthermore there is accumulating benefit in analogue to stamina maybe for the metaphorical language in the economics of gaining additional wins which is naturally a factor of favourable bias for the winning team who passes through the field with a clean sweep, even before the final race,
I’m afraid my colloquium with game theory is really insufficient to make a eloquent disposition of the matter, but I think there’s quite a understandable natural falling of the dice, but by no means do I demean intentionally the capability of the winning team, very much the opposite since the kind of effects I’m referring to aren’t available to any second team, only the preexisting natural outstanders.
L. P.,
I don’t think CUDA “catch up” will be the factor if you mean the equivalent of the CUDA ecosystem. I don’t see that happening. But the tooling exists to eliminate the difference for anyone willing to invest in their performance. Super users are usually inclined to so invest. National laboratory teams are. Academics time sharing under grants application process for access are a wholly different customer
Momentar recollection : it was in record time Sun was dispossessed of the Cray topology technology, after purchasing Cray Research. They got the Sunfire10k out of it so the future new homeland defence director who forged her degre could try to install one in the dep of labor library to avert a buddy’s bill for sanitisation of their punch card attendance system yep a Cray to punch works gate cards. Dot boom was like this most days..
I can’t be alone in craving details of Slingshot, surely?
When my lp is available next week I will be there with my request to formally clarify the limit of details that further inquiry may result in permission to share. Has to be a careful process, please allow, because I’m not for the obvious reasons at any liberty to throw around the very information my company needs, if HPE are disinclined themselves to disseminate. But often the holdup is not legal or trade secrets but simply PR = Marketing bandwidth and latency, which is my professional remit, or historically that’s so but now no more a distinction of my job than a MCU or electric motor is the validation point for a clothes washer dryer.
@NSJM: your AI-based(?) text generator needs some serious tuning :-)
Comments are closed.