
Today Oak Ridge National Laboratory (ORNL) and the US Department of Energy (US DoE) are making a big announcement. In 2021 we will see the Frontier supercomputer reaching levels of performance that are well beyond anything we have today. Frontier is set to be a 1.5 exaflop supercomputer. For some context, the Summit supercomputer, today’s fastest, is around 0.2 exaflops. While Summit was based on IBM Power and NVIDIA, Frontier will go in a different direction. At today’s announcement, the company says that the new Cray supercomputer will be powered by a future AMD EPYC generation as well as a future AMD Radeon Instinct. STH attended a pre-briefing call on the new supercomputer.
Cray and AMD Power Frontier Supercomputer
The first major announcement is that the new US DoE supercomputer housed at ORNL will be powered by Cray. Cray said that it will be using a future revision of its Shasta platform. At STH, we saw the Cray Shasta blade based on AMD EPYC at SC18. This particular platform we are told is for AMD EPYC “Rome” CPUs. This is very interesting since we recently covered that Cray Confirms Intel Xeon Platinum 9200 Support. It seems that the promise of such as setup, and more accurately such a setup as it will evolve in two years or so, was not enough to win this contract.

Cray had some staggering figures for the new machine, ORNL’s third generation of supercomputing architecture.
- Frontier will achieve 1.5 exaflops in compute power
- It will be composed of 100 Shasta supercomputer cabinets
- Each cabinet is rated for 300kW
- Cray’s Slingshot interconnect will be used
- The total system size is over 7300 square feet (more than two basketball courts) and will weigh over 1 million pounds
- Frontier will use around 90 miles of cables
- The system build contract is for $500M
- There is another approximately $100M development contract for the programming environment
There is a lot to break down there before we get to the AMD portion.
First, 100 cabinets * 300kW yields 30000kW or 30MW and there are likely other power costs not included in there.
Cray’s new Slingshot interconnect is fascinating. While InfiniBand and Omni-Path have become popular in the HPC space, Slingshot is able to handle low latency adaptive routing for different traffic on the fabric while maintaining compatibility with Ethernet.

Shasta and Slingshot are a big deal. If you believe that enterprises are about to boom, and cloud providers will want to offer HPC systems, Slingshot compatibility with Ethernet means that it aligns more closely to public/ private cloud standards rather than more niche interconnects. Cray stated its goal to deliver the technology in Frontier to organizations starting in a single 19″ rack. The company says the architecture is purpose-built for Exascale, but it is clear Cray has HPC and AI ambitions outside of Frontier.
$600M (or more) for the new system is also a big figure. When it is complete, it will likely be the most costly system in existence and is designed to do HPC and AI workloads at a scale that has never been done before. This is a big check being written to do big science.
New AMD Technology in 2021 Powering Frontier
During the pre-brief, Dr. Lisa Su, AMD’s CEO outlined a number of advancements AMD will make for the 2021 system. First, the CPUs will be a future generation AMD EPYC product. Second, the GPUs will be a future Radeon Instinct product. Neither of these two announcements is completely surprising. What they do show in the context of Frontier, is that AMD has convinced Cray and the US DoE that in 2021 it will have the CPU and GPU platforms that are worth investment. With a $100M development contract and the fact that the largest supercomputer in the world will be using AMD in two years, this will do a lot to bolster AMD’s market perception and support.
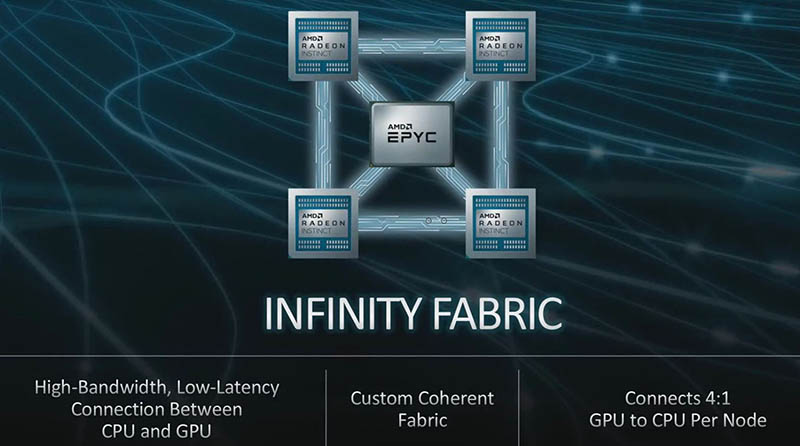
The actual architecture we are told will involve a single AMD EPYC CPU mated to four AMD Radeon Instinct GPUs. On the pre-brief, we were told the ratio, not the topology, but were told that a future, coherent Infinity Fabric will tie CPUs and GPUs together. If you saw our recent Gen-Z in Dell EMC PowerEdge MX and CXL Implications article and were wondering if coherency is going to be a big topic in the next few years, this is further proof that it will be.
The CPUs themselves AMD says are based on a future “Zen” core design. This future AMD EPYC processor we were told will be customized and optimized for HPC and AI. We were told that these future EPYC CPUs will add additional instructions and have an optimized architecture for AI and supercomputing.
Final Words
For the US DoE, Frontier will be a big system that will enable big science. Beyond traditional HPC, the focus on bringing cloud-like management and AI capabilities to the system gives the broader ecosystem direction. For Cray, this is probably the company’s largest single contract ever, or at least publicly disclosed contract. Shasta and Frontier can be the way that Cray pushes into the higher-end enterprise market. For AMD, this is a great proof point and validation of the company’s strategy on both the CPU and GPU side. Perhaps the most intriguing aspect of Frontier and the technologies that comprise the system is that it is not a theoretical exercise in the future. Instead, it is something we could see in the next major hardware cycle or two.
Here is the live stream announcement recording:
https://youtu.be/0etwfvG3x2g



{kind=link}
Nice boost to ROCm foundation too
So now the US DoE is doomed big time… Nobody in the computer industry can do anything without CUDA, “the more you buy, the more you save”.
I think people are forgetting that if ORNL is getting a new super computer, there are probably one or two more of the same thing being built for the CIA and NSA. I’d triple that $600 million figure.
I’m more interested in the Infinity Fabric and that graphic that shows CPU to GPU Infinity Fabric coherent connectivity and how that will play out in the regular Server/Workstation market. Even looking at first generation Zen/Naples there was xGMI(Infinity Fabric based) functional blocks available on the Zen/Zeppelin die and current Vega 20 based Radeon Instinct supports xGMI. So for Epyc/Nalpes that was pretty much for the Infinity Fabric InterSocket (IFIS) for inter-socket communication only. Now Epyc/Rome will support the Infinity Fabric Ver 2 and its 2.3 times the per link bandwidth and who knows what that Frontier Supercomputer/Infinity Fabric IP will support on a per pin/per trace data transfer rate metric.
I’m very interested in finding out if Epyc/Rome and its Motherboard Platform will support options for a similar xGMI/IF protocol based CPU cores to GPU DIE/DIEs direct attatched GPU/Other accelerator xGMI/Infinity Fabric-2 capability also as that’s what Nvidia’s NVLink/NVlink-2 IP supports on Power9 systems. I’m assuming that it will be the same sorts of Infinity Fabric/xGMI siginaling over the PCIe traces and PHY with the PCIe protocal/signaling disabled and Infinity Fabric-2 protocol/signaling used instead. PCIe 4.0 is fast but compared to Infinity Fabric Ver 1 and Ver 2 there is not as advanced of a coherency signaling that the PCIe standards support compared to the Infinity Fabric 1/2 IP that is much more fully integrated into AMD’s CPU and GPU hardware than PCIe.
I’m really hoping to see some Radeon Pro WX Professional Graphics GPU support for xGMI for some Vega 20 based Radeon WX branded Pro Graphics workloads where up to 4 GPUs can be linked via a bridge connector for better scaling across multiple GPUs. Currently Vega 20 is being used for Radeon Instinct with xGMI fully enabled and for Radeon VII(Consumer Gaming) with xGMI disabled and not used currently. But AMD really needs to get some Radeon Pro WX branded professional graphics cards(Vega 20 based) to market that offer full xGMI support and maybe some future consumer variants that support xGMI also and/or has that xGMI fully enabled. AMD’s next generation Navi will probably have the same or newer xGMI/Infinity Fabric-2 or newer sorts of integration and that’s another question for AMD as there will probably be some “Navi 20” GPU Tapeout with loads of AI/Compute capability also in 2020 after consumer Navi launches Q3 2019.
Nvidia is not standing still and Power 10 will be coming in 2020 and Intel has GPU aspirations of its own and also some FPGA IP that can enable Intel to offer Tensor Core based accelerators implemented via FPGAs in advance of any Tensor Cores in ASIC form. Intel is still behind in Discrete GPUs compared to AMD/Nvidia but that will not always remain that way. AMD will have to partner with Xilinx for FPGA inferencing and maybe some matchmaker could get those 2 closer in the future. Nvidia is wooing Mellanox and has already set a date for the nuptials pending any objections from the pews.
I’d love to see an analysis of AMD, Intel, and Nvidia just to see which one currently has more In House IP that could be used to create a whole supercomputer system and which one will have to partner the most on any third party IP while trying to get the entire job fully done with in-house IP as much possible. Nvidia has to partner with IBM/OpenPower while Intel currently is working towards its own discrete GPU ASIC solutions but has FPGA IP of its own compared to AMD which has very mature CPU and GPU IP but has to partner for FPGA IP currently. Along with the usual Ethernet and other HPC communication related IP that wires up all the cabinets and cabinets stuffed with more than just CPUs and GPUs there will be third party vendors also. So the third party partner requirements for some will be more than for others.
AMD’s CPU/GPU package pricing probably helped a great deal with winning that contract for Crey/AMD along with AMD’s ability to get more CPU cores on an MCM at the right cost/performance metrics. That and the ROCm software/API being open source and fully auditable by the larger scientific programming community without much in the way of restrictions or NDAs required. AMD’s ROCm ecosystem could not have been given a better boost towards a larger adoption rate than this DOE contract with Crey/AMD for the Exaflop systems market and that’s going to work its way down to more than just the research related markets in very short order, even before the actual full system is in place and performing production workloads.
Also, AMD still has more of that SeaMicro IP that it can share/license with its partners to some degree or another and that would be interesting to see put to productive use even if through some third party server OEMs as AMD is no longer a server OEM on its own save for some of SeaMicro’s legacy contracts that AMD still has to support.
Very interesting.
Infinity Fabric is cache and memory coherent, which only by itself facilitatates the programming of the thing like never seen before.. not even the Power with 25Gio and NVLink which is only memory coherent (for sure more easy to port all the CUDA code).
Yet to be in Exaflop range I don’t see the Radeons having the 4096 sp limit… it hás to be much more… or perhaps this 4096 thing is not to worry at all, the Radeons Will be on sockets and use all the “magic” of EPYC for the interconnet and scalability… at least 4 Radeons per Socket..
It would be easier on slots I think, but the practical results would be the same… something real monster and scalable… which BTW, if there Will be a “central HUGE I/O Hub”, can only make me think of other “magic”, that can turn everything even more scalable, but also composable
https://genzconsortium.org/educational-materials/
Funny Cray is on it to!… perhaps AMD was chosen, not by its actual pure raw performance, and perspectives for 2021… which is very high nonetheless… but for other reasons of upgradablity, scalability, and composability, more far in the future.
At least the processor-memory paradigma beying ‘ decoupled’ for a machine of this size, that is, being possible to upgrade the DIMMS to NVDIMMs or NVDDIMMs whitout any hassle on the processador side, for me would be already a huge point in favor (Gen-Z again).
finally novideo and intelbribe will get punch in the face.
100 million for software development is nice. One may assume some portion of that can be reused to improve their gpu compute environment and tools for mass consumption.
I would like to see a much better flop/watt ratio for when this computer scales to 150 exaflop, will require a 3GW nuke plant and for our nation would suggest the largest that we have at ~3.9GW near Wintersburg AZ.
Since the power grid near DC is already very burdened, along with having a large concentration of data and supercomputing centers, perhaps a place other than ORNL is better, reducing density related vulnerabilities.
Park McGraw
I work at ORNL. It is very much in Oak Ridge, TN and not in Washington D.C. There is also no shortage of power. Oak Ridge used to consume 1% of the nation’s power. There is plenty of installed capacity.
Comments are closed.