
A big point of news today, NVIDIA announced it will acquire Mellanox for $6.9 billion. When it was rumored that Intel was shopping for Mellanox, we had A Product Perspective on an Intel Bid for Mellanox. The $6.9 billion price tag is high, but through cost synergies and potentially raising prices or getting higher attach rates, this is a case that NVIDIA can make. We will let others do the financial breakdown, but I wanted to give a quick perspective from the product side.
Mellanox Acquisition a Prelude to NVIDIA Servers?
Here is the wildcard that I wanted to start with. What if NVIDIA is making servers? Taking a moment to see the key parts to today’s GPU servers:
- CPU for the OS, data preparation and PCIe connectivity
- GPU-to-GPU connectivity via the CPU PCIe lanes, PCIe switches, and/or NVLink
- Network fabric to cluster larger HPC and deep learning training systems
- Local cache storage and network storage
- Chassis, packaging, and cooling
- Software and framework support
If we go down this list, with Mellanox, NVIDIA now has everything.
CPU for NVIDIA GPU Severs
CPU wise, NVIDIA still heavily uses Intel CPUs. We are seeing alternatives in POWER9 and AMD EPYC, notably, we just reviewed a single socket AMD EPYC server, the Gigabyte W291-Z00 with 4x NVIDIA Tesla V100 32GB GPUs. That configuration would not be possible on an Intel Xeon Scalable system since it would need a PCIe switch due to a lack of PCIe lanes for Intel. We just covered the Journey to Next-Gen Arm Neoverse N1 and E1 Cores where NVIDIA could be making its own Arm server CPUs which it already has some experience in with the NVIDIA Jetson TX2 series.

NVIDIA already has some IP to do this, and Arm’s vision with the Neoverse N1 and subsequent generations is that it will be easier for NVIDIA to make bigger chips going forward.
GPU-to-GPU Connectivity
On the GPU-to-GPU connectivity, Mellanox is interesting. When we did the Mellanox BlueField BF1600 and BF1700 4 Million IOPS NVMeoF Controllers piece, we showed how Mellanox has an Arm CPU powered device with its network IP and its PCIe switch IP integrated. We even asked at Flash Memory Summit 2018 if indeed this was their own PCIe switch IP or Broadcom/ Avago’s and we were told it was Mellanox’s.
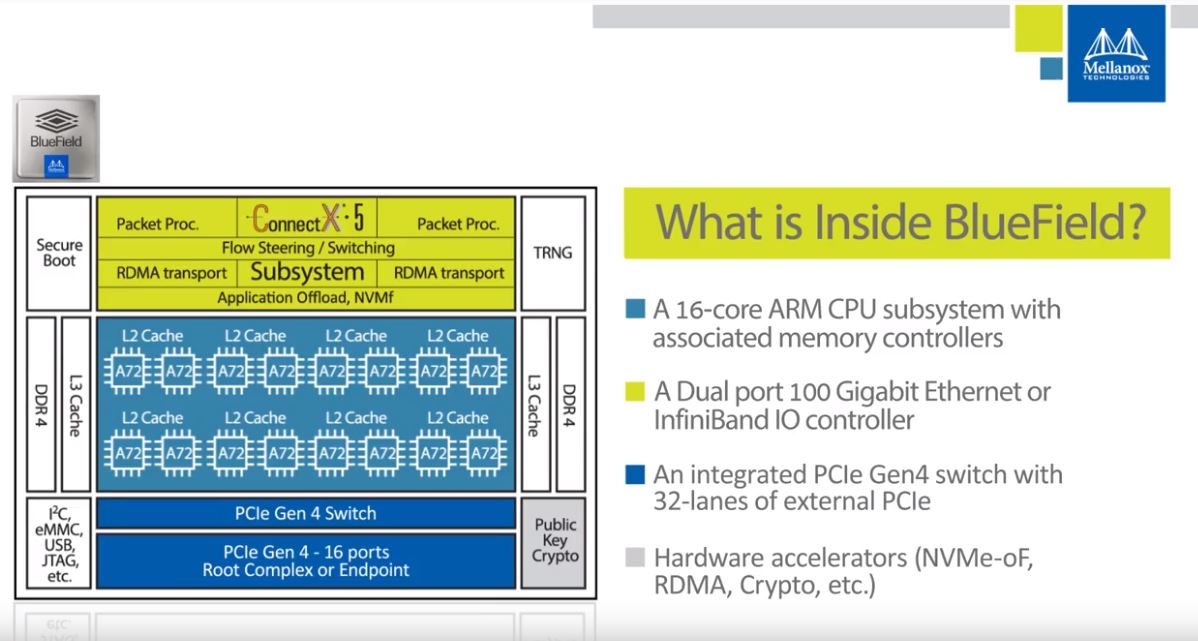
If one takes a step back, BlueField is not just a potential HPC/ deep learning training NVMeoF storage building block. Instead, it is a device with Arm CPU cores, Mellanox Networking IP, and PCIe 4.0 connectivity, including a PCIe switch. There are also accelerators for NVMeoF and RDMA duties. It does not require a leap of logic for someone sitting at NVIDIA to think about its GPUs working on the platform. Further, Mellanox has PCIe Gen4 support on their NICs as well as in Bluefield, and NVIDIA has the SerDes support on its Tesla cards. BlueField is a model for NVIDIA to get faster connectivity without waiting years for Intel to catch up.
The flip side is that if NVIDIA took this model, and made the Arm SoC plus high-speed I/O a part of its future GPUs, we could be seeing a new generation of fabric attached GPUs without servers. Imagine a datacenter full of NVMeoF and GPUoF. If you think architecture is moving towards a more disaggregated model, this is a way to get there. Of course, to do this, NVIDIA would need to solve the scale out v. scale up advantages problem.
Network Fabric
The networking side makes perfect sense. We highlighted the trend again in our piece: Top500 November 2018 Our New Systems Analysis and What Must Stop. Here is one chart from that:
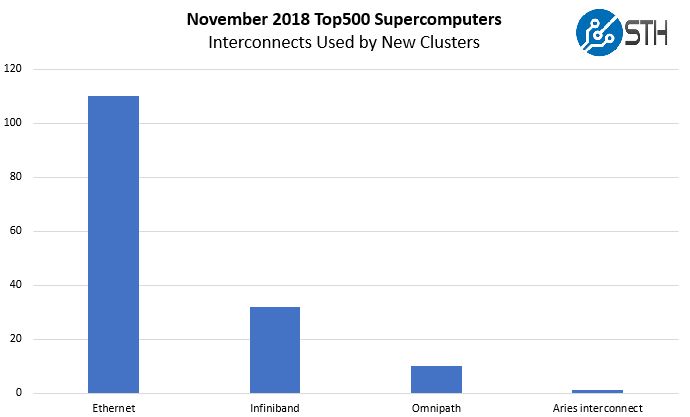
Here, Ethernet is winning and InfiniBand is #2. Mellanox dominates InfiniBand and it has significantly better high-speed Ethernet implementations than Intel, especially from the 40GbE Mellanox ConnectX-3 generation and beyond.
Intel practically gave Omni-Path (OPA100) away to get its foot in the door. Although Intel Skylake Omni-Path fabric does not work on every motherboard, we saw in our Intel Xeon Gold 6148 Benchmarks and Review why at under a $200 premium, OPA was inexpensive and compelling to add to Skylake-SP HPC systems. Even with prices several times higher, Mellanox was still winning with Infiniband and Ethernet was beating both.
We covered this in our A Product Perspective on an Intel Bid for Mellanox piece, but while we use Intel heavily at 1GbE and 10GbE generations, we have slowed using Intel for high-speed networking. Intel Fortville may have used less power and heat, but Mellanox pulled ahead with offloads. In the 25GbE / 100GbE generation, we are almost all Mellanox ConnectX-4 Lx and Mellanox ConnectX-5 in the STH DemoEval lab. As an aside, our recent Inspur Systems NF5468M5 review system was configured for a large Chinese CSP and came with dual Mellanox ConnectX-4 Lx cards which shows Mellanox penetration into CSP GPU systems.

Beyond the internal NICs, Mellanox also makes high-performance Ethernet and InfiniBand switches. We actually had Intel switches in our Supermicro SuperBlade GPU System Review and Supermicro MicroBlade Review, but eventually, Broadcom based switches supplanted their Intel counterparts in those chassis. We have an Intel OPA100 switch in the lab, but that is relatively unused due to a smaller ecosystem than InfiniBand.
Local and Network Storage
For storage, BlueField had local NVMe accelerator support, as well as NVMeoF support for networked storage. Mellanox NICs have offloads for high-performance network storage. This one seems easy and is something that NVIDIA did not have expertise in prior to the Mellanox announcement.
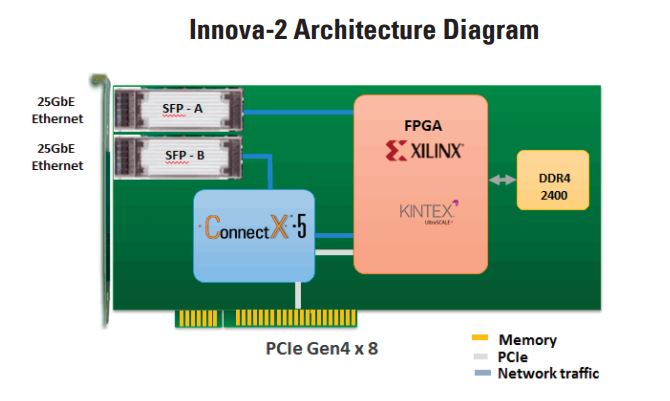
The company was even pushing into FPGA offloads for networking, network storage, and inferencing with its Mellanox Innova-2 with 25GbE and Xilinx FPGA product.
For NVIDIA, it has the ability to leverage the NVMe and NVMeoF ecosystems to feed its GPU servers, and Mellanox has been a leader in this space beyond just simple NICs and switches.
Chassis, Packaging, and Cooling
On the chassis, packaging, and cooling sides, NVIDIA has been pioneering topologies with systems such as its NVIDIA DGX-2.

It has then been using a model to enable partners with platforms like the NVIDIA HGX-2. Of course, NVIDIA relies upon Mellanox NICs like the Mellanox ConnectX-5 VPI 100GbE and EDR InfiniBand cards to provide networking fabric.
Whenever we configure and build platforms based on these HGX designs, such as the Gigabyte G481-S80 we called the DGX1.5, we always configure them with Mellanox NICs.

While Intel still has not shipped its 100GbE generation of Ethernet NICs, and its OPA100 support is stalling, Mellanox ConnectX-6 is bringing 200GbE and HDR Infiniband fabric to HPC. With Mellanox, NVIDIA is getting the best PCIe Gen3 and PCIe Gen4 network fabrics before others do.
If you want to sell high-margin servers, selling the best GPUs and the best scale-out fabric is the way to go. NVIDIA has already been selling this package and the cooling required to keep everything running including high-speed PHYs.
Software Support
When it comes to software support, Mellanox support in NVIDIA systems is excellent.
We recommend our readers who want the easiest scale-out experience to use Mellanox networking in their NVIDIA Tesla servers because the out-of-box functionality is generally good.
Summing Up NVIDIA Products with Mellanox
With Mellanox, NVIDIA will have a broader portfolio to sell to CSPs and server vendors. For the vast majority of the market, that is a good sign. AMD may not like NVIDIA-branded Mellanox NICs in its AMD EPYC or GPU servers, but it will be the best option out there. Current AMD EPYC servers use Intel NICs as we saw in our Gigabyte MZ01-CE0 review as an example.
On the Intel side, there should be a $900M fund aimed at networking starting today. Intel does not have a competitive high-speed network fabric portfolio today. Omni-Path is still at 100Gbps while InfiniBand and Ethernet are now at 200Gbps. Intel’s fastest publicly available NICs only service 25GbE/ 40GbE networking. Intel has not had a competitive switch product released in years. The fact that NVIDIA outbid Intel for Mellanox by perhaps $900M means one of two scenarios:
- Intel is exiting the high-performance networking market. Perhaps only playing with low-end NICs like the Intel XXV710 with inferior offload capabilities.
- Intel decided it can invest the incremental Mellanox bid differential and revamp its networking portfolio through acquisition (e.g. Chelsio/ SolarFlare) or through internal R&D.
Beyond Intel, the benefits to consumers for tighter fabric and GPUs can make sense, although Mellanox already invested heavily on this. A worry in the market can be the “Broadcomification” of another segment. We covered this in a very related segment years ago in our piece Business side of PLX acquisition: Impediment to NVMe everywhere. Broadcom’s aggressive bundling and sales practices are still cited as a pain point by server vendors.
Final Words
These types of acquisitions are fun. With GTC 2019 happening next week, the company may be rolling out a more complete vision for the combined company soon.
Personally, I am hoping for GPUoF. Think of the NVIDIA Tesla T4 attached to an ultra-lightweight system all connected via network fabric. That would absolutely change the economics of inferencing at the edge as well as NVIDIA’s deep learning to inferencing value proposition.



{kind=link}
This is a freaking news repost. I thought STH wasn’t just going to copy and paste press releases????????
@holdencau I think this is about as far as you can get from a PR repost. There’s a link at the top then this is all analysis I haven’t seen anywhere else.
I’ve been reading and simply mesmerized by the idea of sticking a QSFP28 cable directly to the GPU. GPUoF you may have coined too which will be a nice to know if it happens.
It looks more like a ploy to maintain or increase nVidia’s control in the cluster & super market. All the other high speed interconnects are dead, all that’s left is Infiniband and AFAIK Mellanox is the last standing IB vendor.
Where will AMD turn to for cluster interconnect when pitch an Instinct based design – nVidia?!
** All that’s left is Infiniband and Intel’s Omnipath interconnect… same question applies.
This is why I read STH. Patrick is a visionary. GPUoF and BlueField great. I’m more worried NVIDIA buys Patrick as a CTO
I never thought about this but Patrick’s right. If NVIDIA-Mellanox can scale the fabric faster than Intel can, and they can adopt CCIX or OpenCAPI, maybe the better model is attach one or two GPUs directly to the network. That’s what the DGX-1 architecture is since there’s a PCIe switch with NVMe storage a Mellanox NIC and two GPUs. Add an Arm CPU to feed and control and you can get rid of the rest of the system.
Possibilities are endless if we stop having to create a PCIe switch fabric to go to Xeons, a NVLINK fabric between GPUs, and a InfiniBand or Ethernet fabric to other machines. Just put everything on the fabric, then charge a lot for switches and cables!!!!
Brilliant move for nvidia.
Gives additional ways to force people to use Tesla gpus instead of cheaper geforce gpus.
Also, imagine supporting a 400gbe port on each Tesla gpu. Instead of 32 pcie4 lanes for a gpu and then 32 more lanes for a nic (required for supporting 400gbps of network traffic for one gpu), the gpu and nic are integrated on the same pcb, so inter-gpu traffic doesn’t need pcie at all. 16 lanes of pcie4 will only do 256gbps, so this can provide more inter-gpu bandwidth than pcie, and can scale out like ethernet.
On the slower side of things, the gpu could have anywhere from 25 to 200gbps connectivity instead of 400gbps. At 100gbps, you already provide nearly the same bandwidth as the x16 pcie gen3 connection normally used for gpu-gpu data transfer. At that speed or above, system pcie performance is largely irrelevant, as gpu->gpu transfers over the network can be the same speed as the pcie 3 bus offers today, and 200gbps offers nearly the same performance as 16 lanes of pcie gen 4.
This type of configuration increases the total available bandwidth, as the pcie link can be used when data needs to go to or from the cpu, while the network provides all gpu->gpu bandwidth.
Obviously geforce gpus would not have any reason for an onboard nic, so to benefit from this topology a customer can’t use geforce cards.
This would limit use of geforce to the type of small scale environments that nvidia condones its use in — small scale tests and end-user desktop style environments. If gpus include high speed network, and if this is seen as a critical way to scale up and out, users would be severely limiting performance by choosing to use geforce rather than Tesla. This is another way for nvidia to encourage this type of user to pay more for Tesla gpus, beyond the legal threat of violating the driver EULA.
Meanwhile, Arista and Mellanox (now nvidia) would greatly increase shipments of switches, so nvidia wins there too, to the extent that customers choose Mellanox switches instead of Arista or other vendors.
In my opinion nvidia is a very customer-hostile company, so the end result of this merger may be bad for customers even if ultimately it’s good for nvidia. Mellanox is dominant in high speed nics, but I think that, unlike with gpus, for nics the gap can be caught up by competitors if nvidia decides to behave in a very customer-hostile way for the nic portion of their business. Intel and others are behind but I don’t think it is an insurmountable lead. In my opinion, Mellanox needs to continue offering a solid value proposition and regularly improving their product line (as they have been for some time now) in order to maintain their dominance.
Disclosure: I own nvidia stock (even though I think they’re a bunch of D***s)
P.S. auto-refresh on the STH website killed my reply twice! Really annoying.
All the financial and most industry analysts just talk about existing products and missed BlueField in the discussion.
I read this analysis, saw that diagram and was taken aback. If NVIDIA figured out how do directly fabric attach a next-gen Tesla to InfiniBand we’d be interested for our clusters. You missed how much power can be saved by skipping PCIe to the host or switch and then back to the adapter.
How is Nvidia “a very customer-hostile company” ??
CUDA is an amazing piece of software and works as defined!!!
That is the most customer friendly way you can be: your product actually works.
Nvidia GPU cards are nothing without CUDA…
Comments are closed.