
The AMD EPYC 7742 has 64 cores and 128 threads per socket. As such, it is peerless in today’s market. The Intel Xeon Scalable LGA3647 lineup in the market during the second half of 2019 and much of 2020 has a maximum of 28 cores. For general purpose workloads that do not take advantage of some of the bleeding edge Xeon features, AMD is matching and sometimes beating Intel’s per-core performance. If you want a general-purpose x86 server today that can offer huge consolidation ratios over Intel Xeon E5 V1-V4 and even Xeon Scalable servers, the AMD EPYC 7742 is simply the way to go.
Key stats for the AMD EPYC 7742: 64 cores / 128 threads with a 2.25GHz base clock and 3.4GHz turbo boost. There is 256MB of onboard L3 cache. The CPU features a 225W TDP. One can configure the cTDP up to 240W. These are $6,950 list price parts.
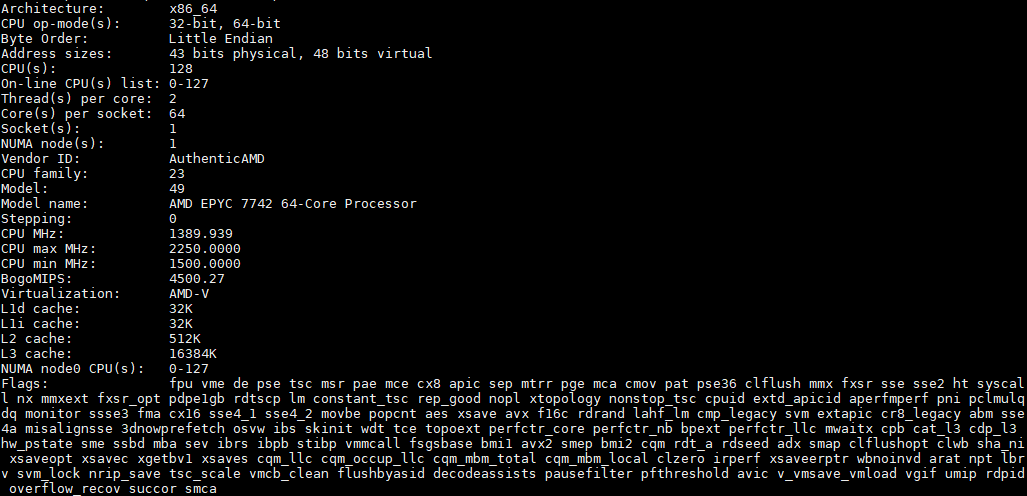
Here is what the lscpu output looks like for an AMD EPYC 7742:
Cores are easy to point to as being more. We wanted to focus on the cache and NUMA advantages of these 64 core chips for a moment.
AMD EPYC 7742 Cache Advantage
256MB of L3 cache is an enormous number in the current x86 ecosystem. The 28 core Intel Xeon Platinum 8280 has 66.5MB of L2 plus L3 cache. L2 plus L3 on the AMD EPYC 7742 is 288MB. With that, the AMD EPYC 7742 has about 4.5MB of L2 + L3 cache per core. Intel Xeon Platinum 8280, 2.375MB of L2 + L3 cache. Having almost double the cache is a big deal.
Another way to look at this is is that if you have 8GB of RAM per core, much like a cloud provider, you would target 512GB per EPYC 7742 and have about 0.5MB of L3 cache per GB of RAM. For Intel, even adding L2 cache, one still has less than 0.13MB of L2+L3 cache per GB of RAM at 512GB per CPU. A big part of AMD’s design is putting massive high-speed caches near compute to minimize requests off-chip. This is an exact parallel to how accelerators like the NVIDIA Tesla V100S, Intel’s next-gen Xe HPC GPU, Intel’s Nervana NNP-T, Intel’s new Agilex FPGAs, Xilinx Versal AI Core ACAP, Habana Labs Gaudi AI training accelerator, the Graphcore C2 IPU, and even the Cerebras Wafer Scale Engine AI chip are designed. Big fast caches, close to the compute resources. Intel’s non-Xeon silicon products are already doing this. The rest of the industry is focused on minimizing DDR4 (or GDDR6 access) using caches.
Moving to chiplets and 7nm allows AMD to do this with yields that Intel cannot get with its current monolithic die designs. In a single die, it is too hard for Intel to yield a 28 core chip with 256MB of L3 cache on 14nm. In future generations, Intel will address this, and AMD will have future iterations as well. AMD is just selling you a more modern processor design today. In 2021, that may change, but the AMD EPYC 7742 has been shipping now for months as we covered in our AMD EPYC 7002 Series Rome Delivers a Knockout piece. Aside from the enormous caches, AMD made improvements to how it fills caches with the new generation as we covered in that article.
Intel is getting some limited traction with the Xeon Platinum 9200 series at up to 56 cores, but that is not socketed meaning Intel supplies both chips and the motherboard. The Xeon Platinum 9200 series systems will not have features such as iDRAC and HPE iLO. One cannot specify one server model and run from a single socket low-end SKU to a dual-socket high core count SKU. Also, the Platinum 9200 uses significantly more power making it a less eco-friendly solution for general-purpose workloads. If you want a socketed platform, you are limited to the Platinum 8200 series today.
AMD EPYC 7742 NUMA Advantage
That has an important impact on another area: NUMA domains. Here is a look at a dual AMD EPYC 7742 server’s topology:

In the EPYC 7601 days (2017), we would see eight NUMA nodes for 64 cores. Now we see one domain for 64 cores or two for 128 cores. With Intel Xeon, technically to get to 64 cores, the only way to do it is with 4x 16 core CPUs in a four-socket server. I did not see a 4x 16 core Intel Xeon topology map in our CMS, but here is a 4x 12 Intel Xeon Scalable topology map from our Supermicro SYS-2049U-TR4 Review:
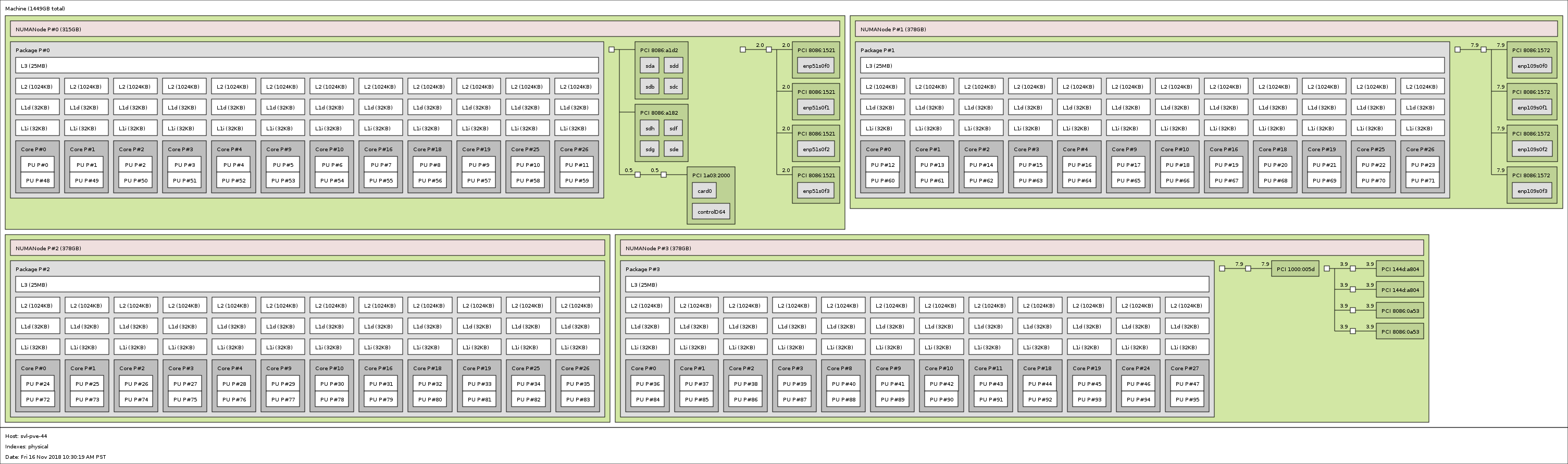
As you can see, there are more NUMA domains and PCIe devices sit on different sockets which can hammer inter-socket bandwidth over UPI. Quad Xeon servers currently have lower inter-socket bandwidth which adds to that stress. The key takeaway is that to scale cores, we essentially need twice the number of chips and NUMA nodes and a less efficient architecture on the Intel Xeon side than with the AMD EPYC 7742. Even the Platinum 9200 series enumerates each die in a CPU package separately more similar to how the AMD EPYC 7001 series did than the EPYC 7002 series.
In terms of memory capacity, the AMD EPYC 7742 is limited to 4TB of memory in 8 channels or 16 DIMMs per CPU (16x 256GB.) Technically, the Xeon “L” SKUs can handle up to 4.5TB of memory in 6 channels and 12 DIMMs using Optane DCPMM. AMD is pricing to compete with standard Xeon Scalable SKUs that have 1TB of memory support. Intel also offers a premium “M” series that can support 2TB of memory in this generation.
Not everyone needs or wants 64 cores per socket. Some will want Intel’s unique AVX-512 / VNNI features, DCPMM. Most in the market will continue buying what they bought before. AMD has other SKUs in its stack which may work better for organizations (e.g. the AMD EPYC 7702P single-socket part.) Intel has a lot of pricing levers it can use. Still, at the end of the day, if you want 64 x86 cores in a socket, the AMD EPYC 7742 is peerless.
Test Configuration
For most of our charts (except the dual-socket virtualization testing) we are using the Tyan Transport SX TS65A-B8036.
- Platform: Tyan Transport SX TS65A-B8036
- CPU: AMD EPYC 7742
- RAM: 8x 32GB Micron DDR4-3200 RDIMMs
- OS SSD: 400GB Intel DC S3700
- Data SSD: 960GB Intel Optane 905P
You are going to see more about this platform, but this is a PCIe Gen4 single-socket platform from Tyan that has 16x front U.2 NVMe bays, 10x front SATA/ SAS bays, two rear 2.5″ SATA OS SSD bays, six expansion slots on risers and an OCP mezzanine slot. All this is achieved using a single AMD EPYC 7002 series CPU.

If you count the PCIe lanes and bandwidth in the platform, Tyan is offering more PCIe I/O than a dual-socket Xeon server in a single socket AMD EPYC 7002 server. We were going to use a dual AMD EPYC 7002 series platform for this review, but the single AMD EPYC 7742 is closer to two Xeons and we have an acceptable, at best, quad Xeon 6200/ 8200 data set.
Also, one may read that you cannot use Optane with AMD EPYC. While it is true that you cannot use the Intel Optane DCPMMs with AMD EPYC, you can use their standard NVMe form factor. Intel Optane NVMe SSDs are excellent for database applications as an example when paired with EPYC.
A Word on Power Consumption
We tested these in a number of configurations. Here is what we found using the AMD EPYC 7742 in this configuration when we pushed the sliders all the way to performance mode and a 225W cTDP:
- Idle Power (Performance Mode): 117W
- STH 70% Load: 299W
- STH 100% Load: 323W
- Maximum Observed Power (Performance Mode): 351W
Note there is a 240W cTDP mode that we are not using here since we are running this series at default cTDP. Depending on the chip, you can get a bin or two of additional performance by running at 240W, just ensure your platform can handle the additional heat.
Next, let us look at our performance benchmarks before getting to market positioning and our final words.



{kind=link}
So basically the only reason you should even consider Intel is if they discount you 60% or you need AVX-512? What a fascinating time to be alive.
Really, a 60-70% Intel discount isn’t a good enough reason to stay with them. Absolutely needing AVX-512 or optane dimms is about the only reason.
Even if you get a 60-70% Intel discount you’re still getting it basically at what AMD charges, but you’re not getting the lower NUMA node count, lower TDP (hence lower electric/cooling costs), rack space savings, PCI gen4, etc, etc.
Thanks for not getting bogged in the weeds. Unlike your launch article, this is actually just right explain + data + editorial. You’ve gotten better.
“Most in the market will continue buying what they bought before.”
This is what we’ll be doing, for sure. Part of it is we just replaced ~half of our VM hosts 18 months ago with Intel (from HPE.) And since we would more likely than not be piecemeal replacing/adding additional servers in the future versus a forklift replacement, the pain involved from running VMware on split AMD/Intel isn’t work the headaches (no live vMotion.)
The other thing is that the person who makes the purchasing decisions isn’t interested in even looking at AMD’s cost/performance. In their mind, Intel is king and AMD is nothing but compatibility trouble. Since we aren’t currently up against a wall as far as colo power or space usage goes, the consolidation factor doesn’t do much for us.
How much longer before Micron launches a competitor to Intel’s NVM/3D-XPoint DIMMs and Micron has already announced its X100 NVMe SSD 3D-XPoint(QuantX branding) competition back in Oct of this year. AMD partners with Micron for GDDR6 along with others so maybe AMD and Micron can work up some Open Standards way of using XPoint based DIMMs on the Epyc/SP3, newer, platform and hopefully that development is already ongoing so that will remove one more reason to choose Intel.
However long it takes AMD to move up from Rome’s AVX256 to AVX512 AMD still has its GPU accelerator products for massive DP FP workloads but is that AVX512 market large enough to go after at this point in time for AMD on CPUs. Epyc/Milan is sure to improve performance once that CCX Unit construct is supplanted by just the 8 core CCD-DIE that shares among its 8 CPU cores the CCD-DIE’s total allotment of L3. And with the only question remaining to be answered is concerning the Zen-3 CCD-DIE’s actual Fabric Topology and will that be a Ring BUS(CCD Die Only) with inter CCD-DIE Infinity Fabric On Package interfacing or some more complicated topology with lower latency as well.
Epyc/Rome really marks the return of wider server/HPC market support for AMD with Epyc/Naples getting AMD’s foot back in the door in the mainstream server market. While AMD is getting some more HPC design wins with Epyc/Rome there are some larger supercomputer/exascale design wins that will be using custom Zen-3 Epyc/Milan offerings specifically targeting Direct Attached Radeon GPU accelerator interfacing via xGMI(Infinity Fabric) Links. So that’s similar to what Nvidia’s NVLink/NVLink2 is doing to interface the Tesla GPU accelerators to OpenPower Power9/Power10 on some HPC design wins.
AMD’s yearly Zen based CPU hardware/micro-architectural update cadence is now in full swing with no signs of any rough patches currently and TSMC’s 5nm apparently progressing faster than was expected. TSMC entered high volume production of its 7nm+ node in Oct 2019 and maybe some of that 20% density improvement claim will go into larger 8 core CCD-Die shared L3 or even AVX512 on some Epyc/Milan offerings.
Guy I think that’s the exact audience behavior he’s talkin’ about.
“The other thing is that the person who makes the purchasing decisions isn’t interested in even looking at AMD’s cost/performance. In their mind, Intel is king and AMD is nothing but compatibility trouble.”
Nobody ever got fired for buying Intel eh? …
When we will see the updated NAMD scores…? I’m really interested to see the uplift if any…
Support for Intel Optane NVMe SSDs is not a substitute for the Optane DIMMs in the new in-memory database applications that are taking advantage of Optane. Oracle is an example.
https://www.oracle.com/corporate/pressrelease/oow19-oracle-intel-partner-optane-exadata-091619.html
According to this article, Cooper Lake has been sampling since May. I presume big customers like FB are already using it. It would have 8 memory channels, avx512, bfloat16 and socketed 56 cores, according to the second link.
https://www.anandtech.com/show/14314/intel-xeon-update-ice-lake-and-cooper-lake-sampling
https://www.anandtech.com/show/14713/intel-to-offer-socketed-56core-cooper-lake-xeon-scalable-in-new-socket-compatible-with-ice-lake
Glad to see Tyan on the bench. They have a great AMD EPYC Rome story.
I’m looking at some DL325’s to replace an aging UCS environment from 2014. Was quite surprised at the lack of choice in HW vendors I had (out of the big players HP seemed to be the only ones that had something ready to go). My MSP seemed a little surprised I was asking about EPYC, too.
While on-prem hardware is no longer the flavour of the month where I am (and hasn’t been for some time) it’s still exciting for me to see how well AMD is doing.
Cooper Lake is still on 14nm, making TCO similar to 92xx Xeons. AVX 512 is no necessity in todays workloads (except AI HPC and other niches of course) Then you’re left with bfloat16, which is probably not utilized by anyone exept the HPC and AI guys, and Intel is left with the position AMD had when they launched Bulldozer for Server – funny how things changed
EPYC 7742 is definitely peerless in 2-CPU servers (comparable to quad 8280 which cost $$$$$).
For 1-CPU servers EPYC 7702P and/or dual 7452 are likely to have significantly better price-performance for most workloads.
@JayN, did you know that electricity is not free?
Also, am I the only one wondering why nobody says to these 99% intel discount arguments that giving discounted prices for high volume orders is not illegal for AMD either?
Just doing a refresh here and moving to all 7702P’s for virtualization hosts. When looking at Intel discounts it doesn’t even come close let alone the per-socket licensing savings. The only outside cost increase is with the WS DC farms which I’m sure Microsoft will be happy when renewals come.
Would AVX512 be nice to have? sure, but for the few workloads that really benefit a couple of GPU’s can handle the bulk of the use cases better for less $$$.
are the updated gromacs or other AVX512/256 results going to be posted in the end? We see them “promised” with the updated gromacs code for many reviews now, but nothing so far, or am I overlooking something? Thank you!
Stan – it took a while to get it stabilized. Now having to re-run everything which means swapping processors. Each swap means a trip to the data center. Slow going. We have been debating in the team whether to just move to a 2020 version and use a larger model as our standard going forward.
Please, *always* provide single core benchmarks even for server CPUs. There a lot of *very* expensive commercial software providers which sell licences per CPU core / per month, and so to pay less for those licencing fees one has strong incentive to buy servers with as fast single cores as possible. However, often all the benchmarks published focus on multi-core performance only.
We have been doing some network latency testing via sockperf using low latency NICs (from Exablaze). Sadly the latency is rather 3000ns instead of 700ns. Does anyone know of a special configuration to get these Dell/AMD boxes into a low latency mode ? We did use the right pcie slots… run cpus at full speed. have set kernel optimizations.
Comments are closed.