
As Xilinx Versal, the company’s newest product it calls an Adaptive Compute Acceleration Processor, took the stage at XDF 2018, the company emphasized the AI inferencing capabilities of the new chip. One of the key aspects of Xilinx’s design philosophy is that AI inferencing is going to be a fact of processors in the near future. Whether these are 5W windshield devices for autonomous driving or high-power radar signal processing machines. As a result, the company is introducing its new, custom developed, AI engine alongside its ACAP products. The Xilinx Versal AI family incorporates the company’s AI engine and the first product available is called the Xilinx Versal AI Core.
Xilinx Versal AI Core Incorporates an AI Engine Array
With the building block of heterogeneous compute, the Xilinx Versal AI Core has a key feature: the AI Engine array. We are going to go into the Xilinx AI Engine in the next section, however the important aspect of this engine is that it is part of the larger ACAP infrastructure.
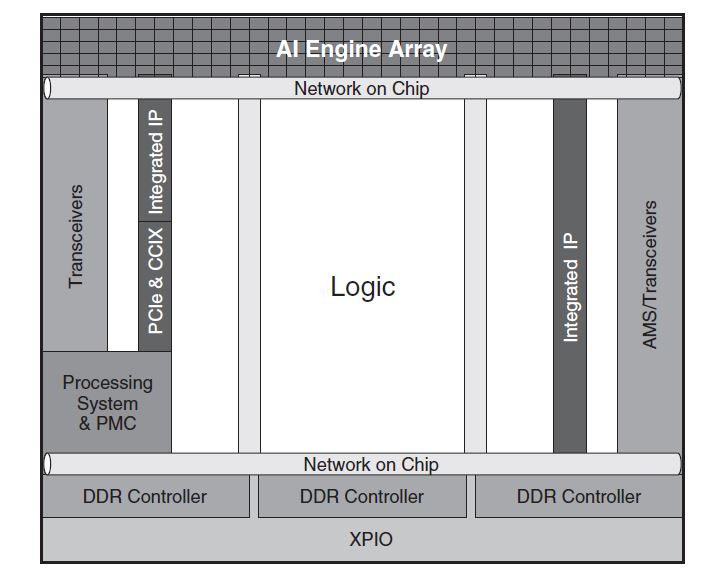
While there are some AI inferencing processors that are good at fast inferencing, the Xilinx ACAP has a broader focus. It has Arm-based application and real-time processors. It has high-speed network-on-chip that connects all of the different heterogeneous compute blocks along with high-speed memory and I/O.
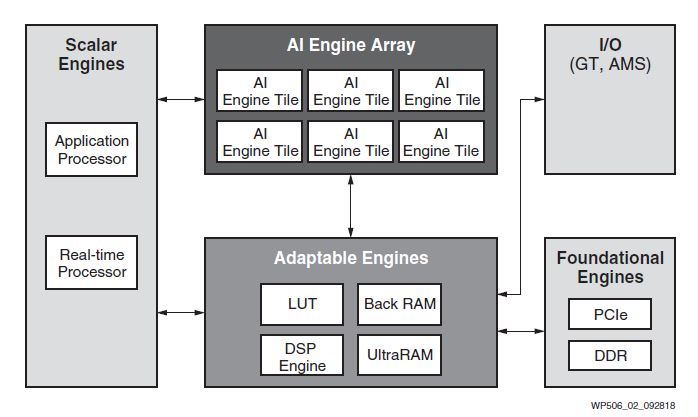
Key here is that Xilinx FPGAs, for years, have had some industry-leading I/O connectivity and memory connectivity. As a result, the Xilinx Versal AI Core is able to deliver fast AI inferencing processing within the same architecture as other parts of applications take place. Those other parts can be running application code on Arm cores, running custom signal processing logic on the FPGA, enhancing that with AI inference, then pushing it over 100GbE or faster next-generation networks. Traditional servers would have to do this in many different devices, often pushing data over a PCIe bus.
Xilinx Versal AI Core ACAP AI Engines
The Xilinx Versal AI Core ACAP has an array of Xilinx AI Engine tiles. The Xilinx AI Engine is a vector processing engine that has local memory, fast vector processing logic, and the ability to offload parts of an application to the rest of the ACAP.
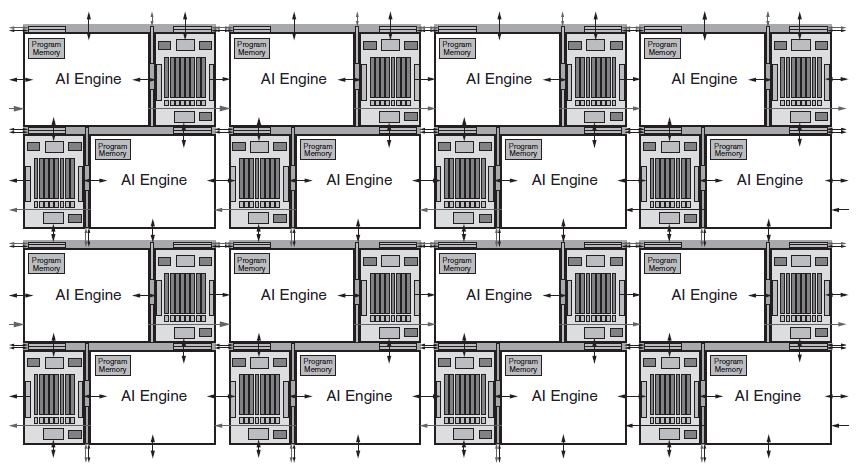
Xilinx AI Enginers are arranged in a 2D array of vector processing units. Xilinx calls these Tiles which are then connected via an interconnect to other AI Engines and other parts of the ACAP.
Each AI Engine tile has its own memory along with compute features like the 512b SIMD vector unit. Utilizing a large number of these tiles, the Xilinx Versal AI Core and future AI products are able to achieve high inferencing performance with low latency.
Xilinx Versal AI VLIW Support
One of the key ways to get more parallelism is increasing the instruction throughput per clock cycle. The Xilinx Versal ACAP supports 6-way Very Long Instruction Word (VLIW) processing.
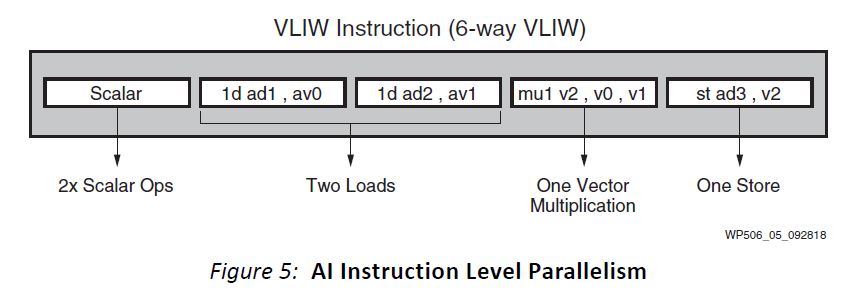
For each clock cycle, the Xilinx Versal can execute two scalar instructions, two vector reads, a single vector write, and a single vector instruction. Exploiting instruction-level parallelism allows the Xilinx Versal AI ACAP to achieve higher throughput.
Xilinx Versal AI Precision Support
The Xilinx AI Engine vector precision support is a bit more complicated. We were going to write a large amount, however, the company provided a table which does this much better than a wall of words.
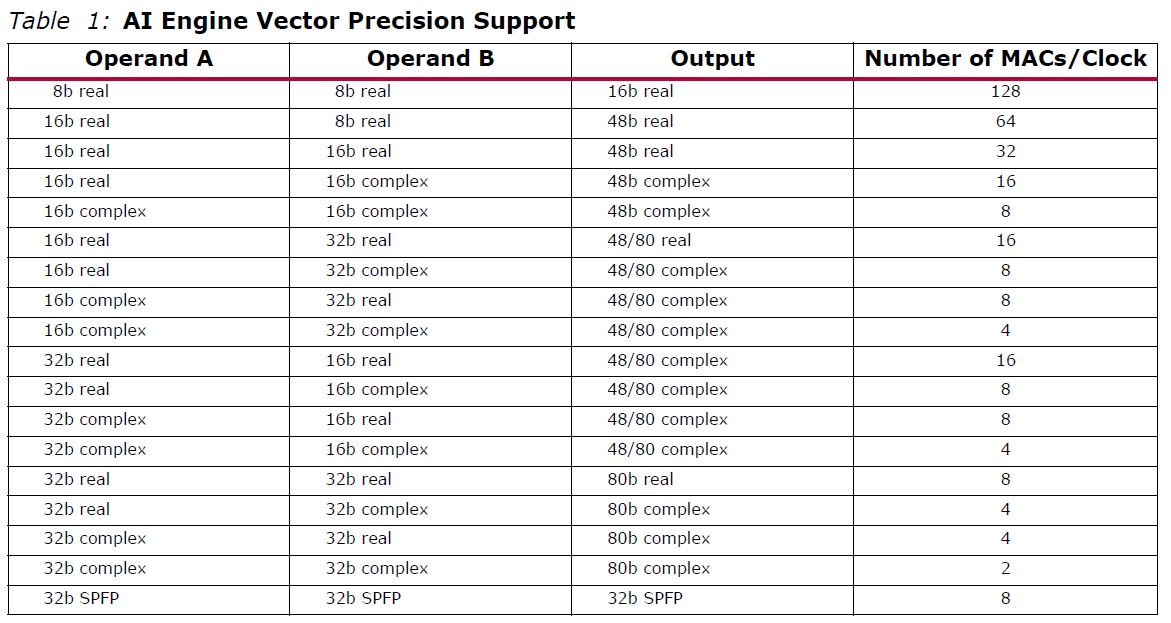
Again, while Xilinx has its AI Engine, its heterogeneous compute platform, including traditional programmable logic, can be used to accelerate other types of calculations.
Xilinx Versal AI Core Performance Claims
Xilinx has a number of performance figures. There are also a lot of different compute resources which makes it, in a way, akin to something like NVIDIA’s Turing or Xavier where it is harder to quantify performance because of the different types of compute. Here is what Xilinx is quoting for the Versal AI Core series:
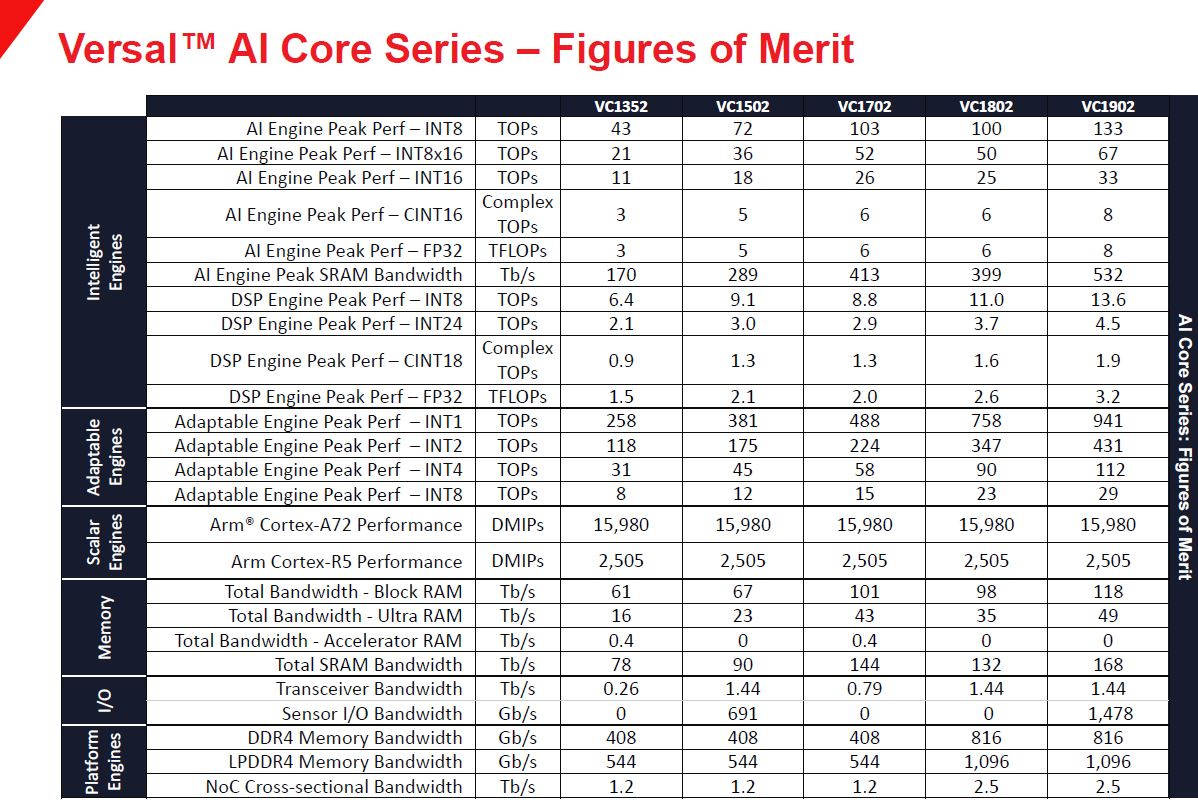
The different SKU levels have more details on the following slide.
Xilinx Versal AI Core Launch SKUs
Here is the product matrix for the launch Xilinx Versal AI Core solution. You can click to expand the view.
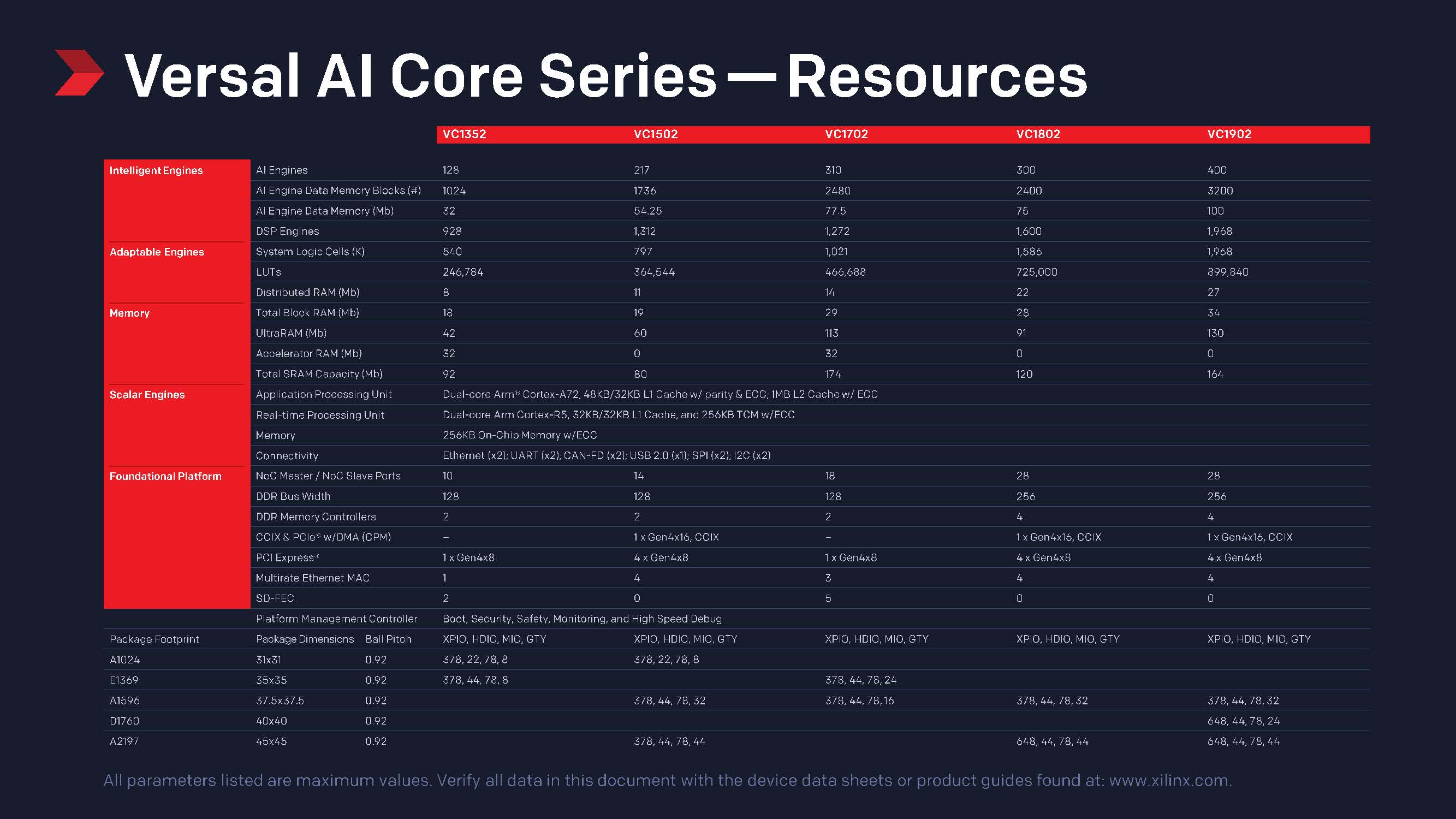
These five products will be based on 7nm TSMC FinFET and will be among the first available ACAPs on the market.
Final Words
Listening to Xilinx at XDF 2018 there is a common theme. The company sees AI inferencing as being an integral part of its customers’ workloads. While these are not necessarily the structures one would want for high-end training, they are designed to provide a large amount of low latency compute and to do so in conjunction with the rest of the ACAP’s heterogeneous compute. Unlike GPUs where applications will offload from main program to the parallel GPU, going back to PCIe before pushing data to the network, Xilinx’s solution keeps everything within its ACAP which is an interesting proposition.



{kind=link}