
At Hot Chips 31 (2019) in Palo Alto, California, Intel disclosed more details on its upcoming training platform called the Intel Nervana NNP-T. At STH, we covered earlier disclosures including this year’s Intel Nervana NNP L-1000 OAM and System Topology a Threat to NVIDIA. The Nervana team at Intel has had a very loose product naming system as we have seen names change over time. At the conference, Intel showed off a number of new aspects about the parts.
Intel Nervana NNP-T
The Intel Nervana NNP-T is codenamed “Spring Crest”. Key here is that this is a PCIe Gen4 solution even though Intel does not publicly sell PCIe Gen4 CPUs. With its upcoming chips, the company will have this capability in the public market in 2020, although AMD is there today with the EPYC 7002 series.
The NNP-T has four stacks of 8GB HBM2-2400 memory attached to the main die. That gives the solution 1.22TBps of raw ECC memory bandwidth across the 32GB onboard HBM2. The main die has an array of 24 tensor processors plus all of the memory controllers and links for connections to hosts and to other NNP-4 modules.
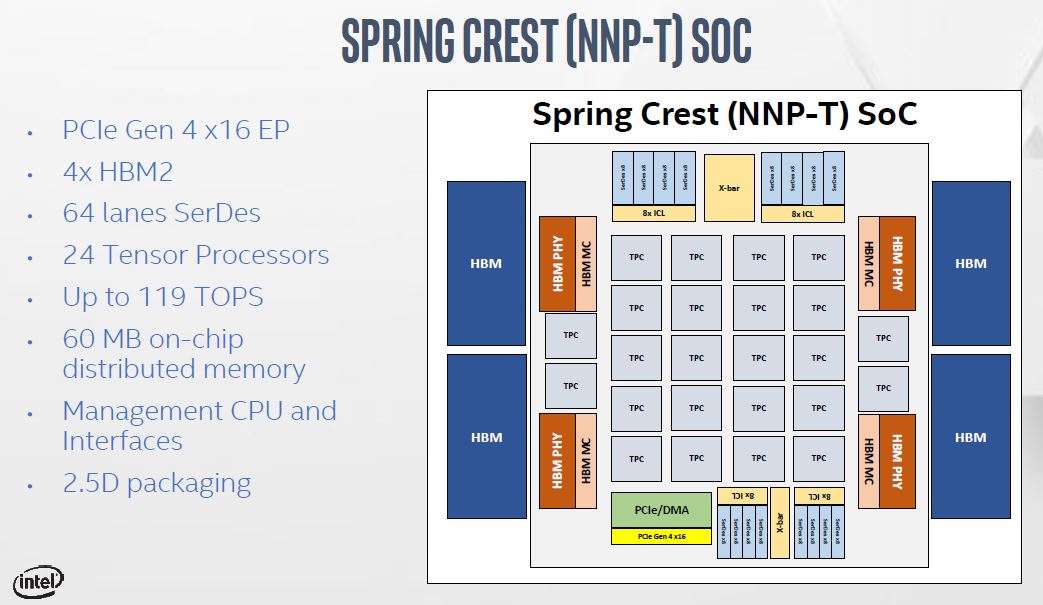
Intel is building the NNP-T on the TSMC 16FF+ process. That is a bit surprising given Intel’s fab capabilities. The total transistor count is high at 27 billion, just shy of the new Xilinx Virtex UltraScale+ VU19P FPGA.

Here are the Nervana NNP module specs from the company’s OCP Summit 2019 presentation:

There, the company said 2nd generation Spring Crest would start production in 2019.
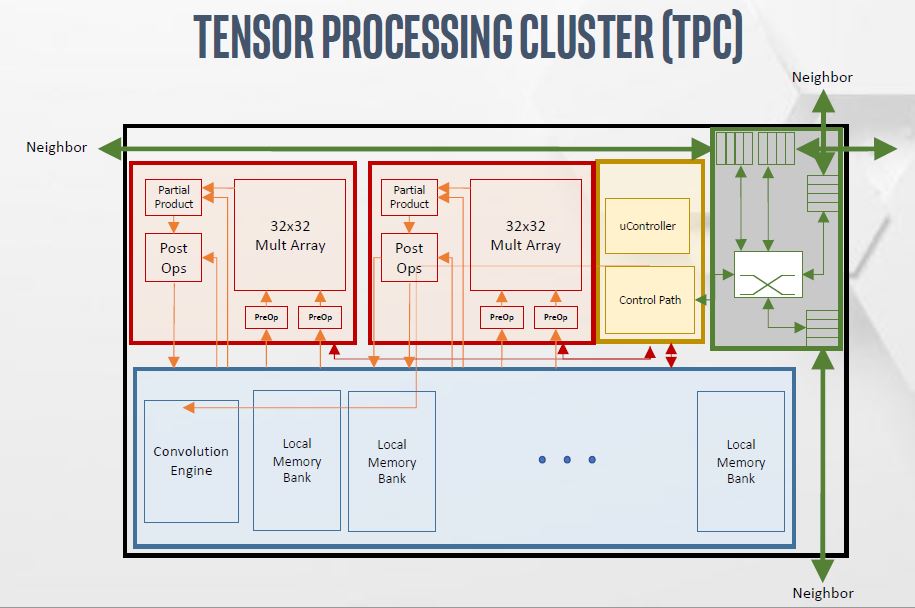
Each Tensor Processing Cluster or TPC, performs the primary compute for deep learning training. We are going to discuss the compute portion shortly, but there is a 2D mesh to neighboring clusters and 2.5MB of local memory that is also ECC backed.
Intel is using Bfloat16 as its primary data type for its Matrix Multiply Core. Bfloat16 will also be integrated into 2020 Cooper Lake Socketed with 56 Cores and bfloat16 that will go along with Spring Crest. Facebook, as an example, is using 8-way Cooper Lake with OAM Intel Spring Crest in its Zion Accelerator Platform for OAM.

One of the key aspects is re-using data once it is in the TPC 2.5MB of scratchpad memory as much as possible. Doing so greatly increases performance by avoiding stalls waiting for remote memory data access.
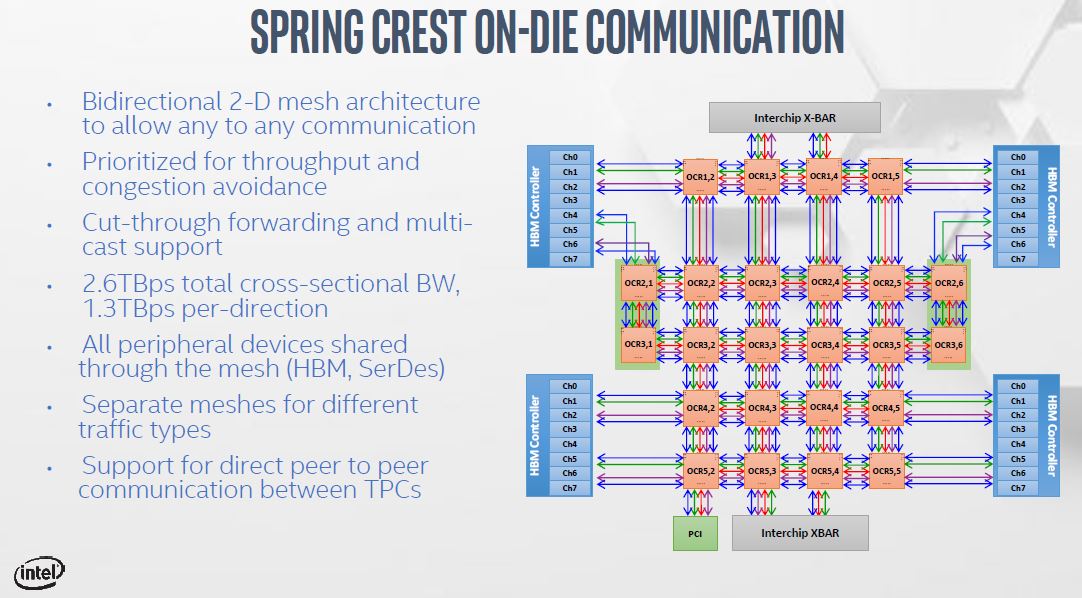
Using the 2D mesh, Intel is able to get 2.6TBps of cross-sectional bandwidth. Between the TPCs, PCIe, ICL, and HBM2 there are different meshes which helps keep data moving through the chip.
We covered the OAM and Facebook Zion quite a bit back at OCP Summit 2019 which you can read about here:
- Intel Nervana NNP L-1000 OAM and System Topology a Threat to NVIDIA
- Facebook Zion Accelerator Platform for OAM
- Facebook OCP Accelerator Module OAM Launched
The key is that these devices have an inter-module communication path that is similar to NVLink in its objective. This allows larger topologies to be made beyond that of a DGX-2.
Final Words
Facebook has been the premier partner for Intel with its Nervana NNP-T line. That has given Intel an enormous partner, but Facebook got something in return. By specifying the OAM spec, Facebook, and other hyper-scalers are pushing away from the proprietary SXM2 and NVLink interface, and to something more open. From that, Facebook now has OAM modules from not just Intel, but also Habana Labs, AMD, and others. While Facebook has given legs to Nervana, it has also kept its options open. We should see more on this later in 2019 and into 2020.



{kind=link}
How do we benchmark these?
Comments are closed.