
For NVIDIA, what Intel showed at OCP Summit 2019 may represent an existential crisis. Intel is using the Facebook and Open Compute Project Accelerator Module (OAM) form factor for its new NNP platform, one clearly aimed at NVIDIA’s high-end Tesla business. Further, this week also marked not just Facebook’s adoption of the OAM, but also Microsoft, Baidu, Google, Alibaba, Tencent, and others. To accelerator vendors, if you want to play with the large infrastructure providers, you need to support OAM. At OCP Summit 2019 we got a glimpse of the Intel Nervana NNP L-1000 module, as well as the system topology of the accelerator. This is a big deal since it is what Intel and Facebook have been working hard to develop in its first generation silicon. For NVIDIA, the architecture may prove scary as it provides a direct threat to the DGX-1 and DGX-2(h) servers.
In this article, we are going to show you the module, how the modules make systems, and how we see them integrating at hyperscale CSPs. Note: we have what Intel and Facebook are doing putting 12x M.2 inferencing chips in front end web modules in our piece 10nm Intel NNP I-1000 M.2 is Perhaps Facebook Inferencing Plan. This is focused on the training products.
Intel Nervana NNP L-1000 Module
Here is the Intel Nervana NNP L-1000 module. You can see the PCIe card’s power input in the right corner. We were told the PCIe version is really more for development, and that the company expects the module form factor to be the way more companies will consume the parts. Reading between the lines, this is the one you want.

One can see the large die flanked by four HBM2 packages. Intel has previously stated that the commercial NNP will support 32GB HBM2 memory equal to the NVIDIA Tesla V100 32GB that we recently tested in the Inspur Systems NF5468M5 Review. Like the NVIDIA Tesla chips, these appear to be direct cooling without a heat spreader. The OAM form factor is supposed to fix a lot of the mechanical challenges with installing accelerator modules that we experienced first-hand in How to Install NVIDIA Tesla SXM2 GPUs in DeepLearning12.
Here is the bottom of the module where you can see a high-density pin array. This appears to be the OAM pin array even on this early Spring Crest sample.

For comparison, here is the mechanical OAM fixture Facebook showed off in its Zion platform.

One can see, that the Intel Nervana NNP L-1000 is designed to have (at least) four high-speed links to other modules as well as a host interface.
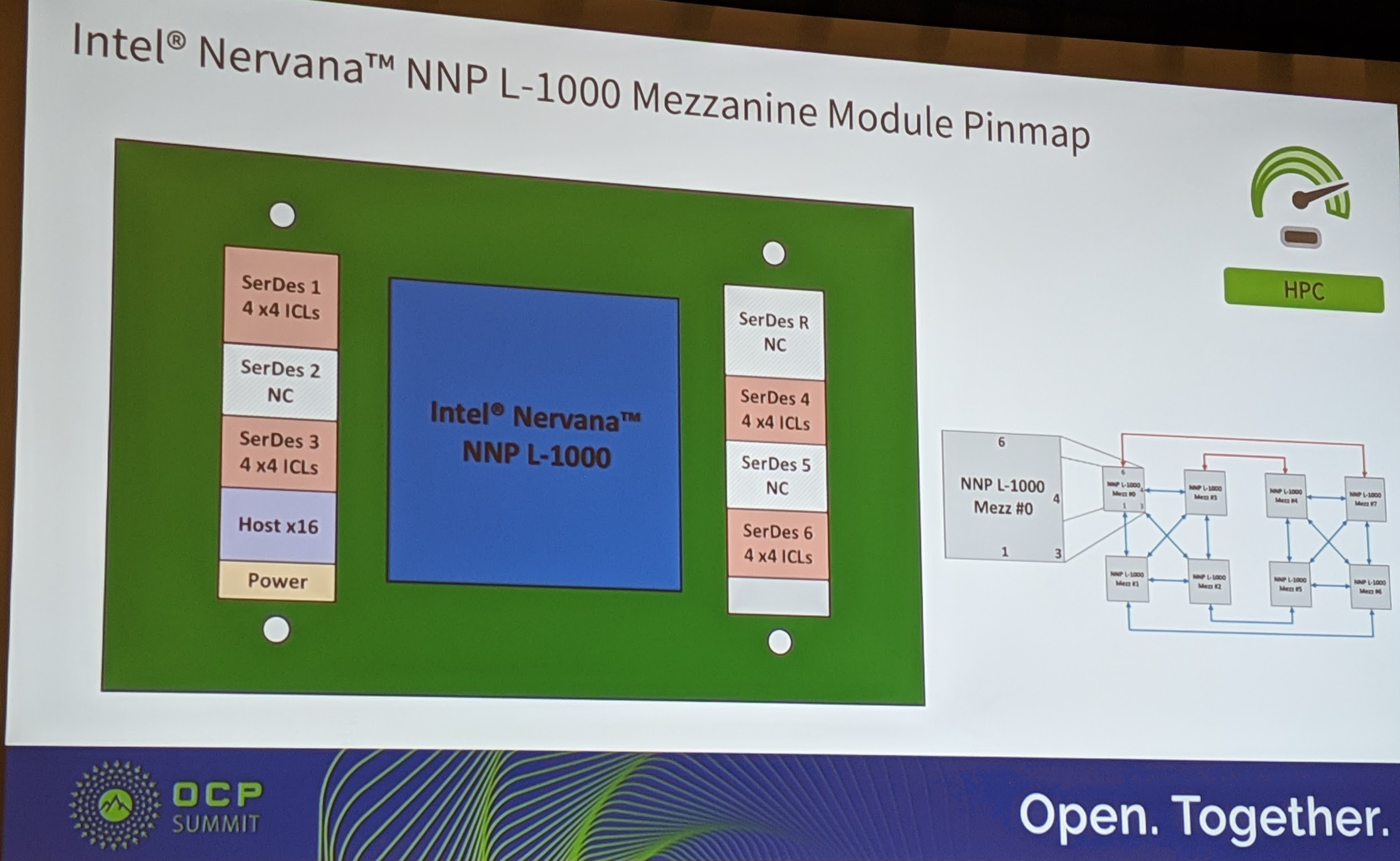
Here is the official slide showing the Spring Crest Intel Nervana NNP L-1000 mezzanine module. You can see that there are components not placed on the version that we showed above from the Intel booth at the show or shown by Jason Waxman at the OCP Summit 2019 Intel Keynote. Here is the official module diagram.

If one were to speculate just how involved Intel was in the OAM creation, look at the “heatsink reference design” for the NNP L-1000 compared to the mechanical dummy.

Those giant PCIe cables are to help get data back to the host. In terms of official specifications:

The large heatsink version that we are seeing is the 425W version and the modules we were told are powered by 48V.
That means that on air cooling, Intel is designing a module that has higher-TDP headroom than the NVIDIA Tesla V100 by a large margin (300W for the V100 at launch, but DGX-2h modules use more with 450W modules.) The trend will be to higher power accelerators. In turn, your 205W TDP CPUs will look paltry in comparison.
Looking at the single module is fun, but Intel went into far more detail at OCP Summit 2019. That includes scaling Spring Crest’s 2nd gen to eight NNP L-1000 modules up to thirty-two modules per system. Next, we are going to cover the Intel Nervana NNP L-1000 topologies as it scales to more OAM units.



{kind=link}
Holy $hit this is awesome. Great writeup STH
SPRING CREST = STH PLEASE REVIEW!!!
Comments are closed.