Intel Nervana NNP L-1000 System Topologies Scary for NVIDIA
Intel then went to show off what a block of 8x Intel Nervana NNP L-1000 modules will look like. Here we can see eight modules with PCIe switches on one side and PCIe connectivity along with QSFP-DD connectors, similar to the 200GbE QSFP-DD connectors we first saw on a system in our Dell EMC PowerEdge MX hands-on review on the other side.

We were told that baseboards for these 8x Intel Nervana NNP L-1000 accelerators should run from 18 to 22 layers. For some perspective, that is in the range of many 4-socket Intel Xeon Scalable servers PCB layer counts, but higher than many dual-socket servers.

Things then get interesting. This slide did not reproduce well, so we converted to black and white to get contrast. The diagram on the left is a reproduction of the one above showing pinouts. Essentially, each NNP L-1000 has four “Inter-Chip Link” connection points for the Hybrid Cube Mesh (HCM) topology. Three traverse PCB to other accelerators. The fourth is cabled via the QSFP-DD connectors. QSFP-DD is designed to be a 8x 50Gbps electrical interface giving up to 400Gbps of bandwidth. We were told that copper cable lengths can be up to a meter.
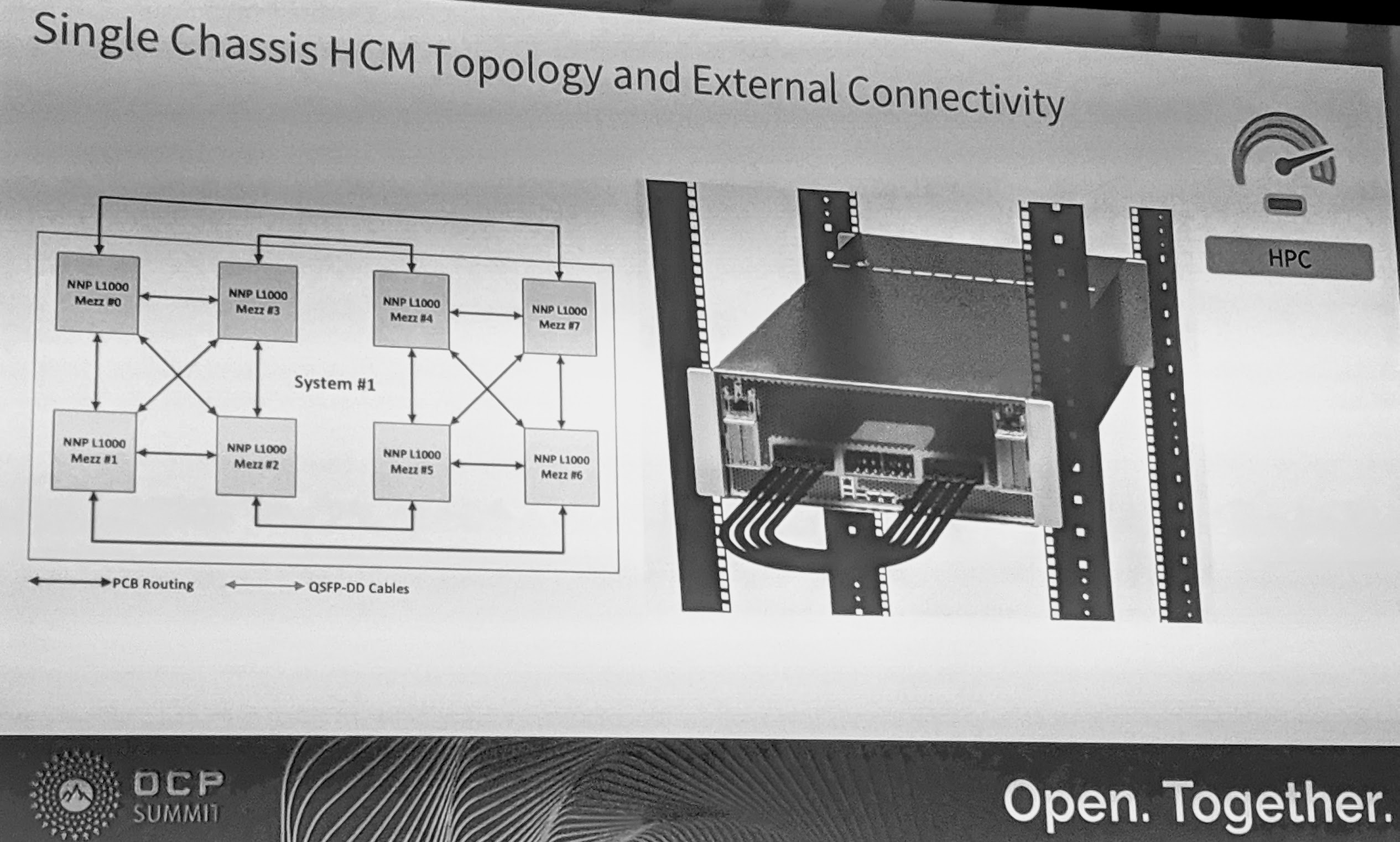
With the 8x 425W NNP L-1000 modules Intel expects these machines to be upwards of 3.4kW. These look a lot like the Facebook Zion platform that was shown off at the show. One can see that the external QSFP-DD cables are an integral part of the solution, and will likely be present even on the single 8x NNP unit. There is a reason that the systems are built this way, and that is for scale.

With external cabling, the links can instead be routed to different chassis. Here we can see a two chassis per rack design with four sets of QSFP-DD cables connecting the 16x Intel Nervan NNP L-1000 solution. As a quick pause here, this is 7.8kW of Spring Crest in sixteen modules with its high-speed fabric. Intel has its SerDes on the module, and from what we have seen it does not need a NVSwitch and the power-hungry NVLink PHYs that are present on the DGX-2. This is your DGX-2/ HGX-2 or DGX-2h competitor topology.

Intel does not stop there. Going beyond two chassis, Intel also showed off a four chassis HCM solution.

Here is the topology diagram for internal and external routes between Intel Nervana NNP L-1000 OAM chips in each chassis and between racks.
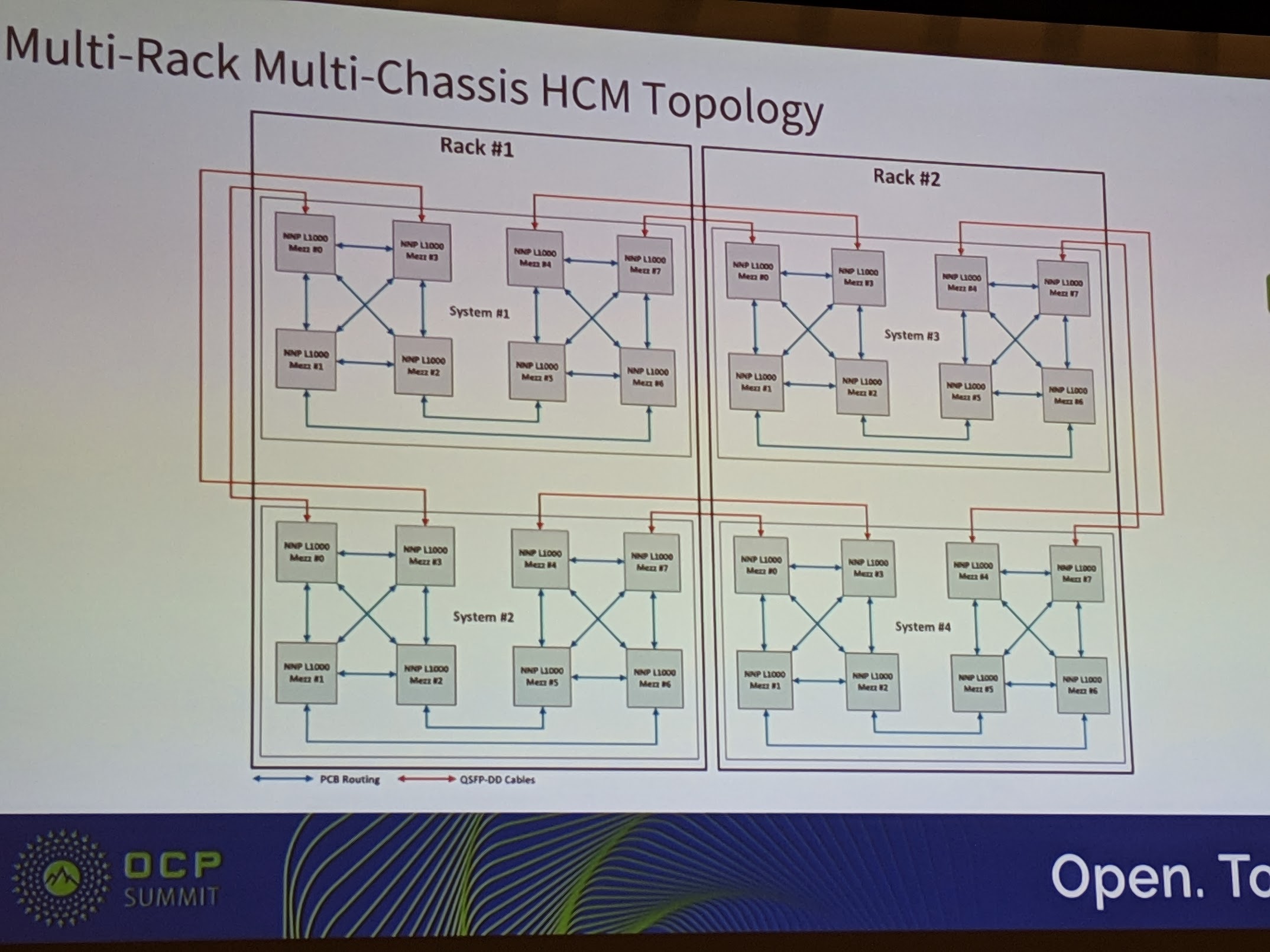
Intel showed off Spring Crest which it expects to launch as a commercial product with a 13.6kW 32x accelerator topology (excluding the host systems) in 2019.
Final Words
Reading between the lines, this should be a scary proposition for NVIDIA. Although NVIDIA is listed as supporting OAM, it looks like Intel had a hand in OAM development, as well as the Facebook Zion platform. The presentation shows scaling from one accelerator to 32 accelerator network using 400Gbps QSFP-DD and PCB routing (likely a similar speed) without hitting external InfiniBand switches nor NVSwitches.
It is likely that the NVSwitch topology or even a GPUoF topology may end up being better option for scale-out deep learning. Intel is sharing details of something that we expect will be launched later in 2019 while NVIDIA announced the NVIDIA Tesla V100 about two years ago. NVIDIA will have a competitive response and since Intel, Facebook, and NVIDIA headquarters are within a 30-minute drive radius (sans traffic) NVIDIA likely has a good idea regarding its NNP competition. NVIDIA also has a massive head-start on its competition in the deep learning training and inferencing space.
On the other hand, we expect that Facebook has advanced knowledge of NVIDIA roadmap and the fact that Facebook (and most of the industry) seems poised to adopt OAM, and the initial OAM infrastructure looks like it had a lot of Intel input may mean Facebook is set to become a bigger customer of NNP in the future.



{kind=link}
Holy $hit this is awesome. Great writeup STH
SPRING CREST = STH PLEASE REVIEW!!!
Comments are closed.