AMD EPYC 7742 Benchmarks
For this exercise, we are using our legacy Linux-Bench scripts which help us see cross-platform “least common denominator” results we have been using for years as well as several results from our updated Linux-Bench2 scripts. Starting with our 2nd Generation Intel Xeon Scalable benchmarks, we are adding a number of our workload testing features to the mix as the next evolution of our platform.
At this point, our benchmarking sessions take days to run and we are generating well over a thousand data points. We are also running workloads for software companies that want to see how their software works on the latest hardware. As a result, this is a small sample of the data we are collecting and can share publicly. Our position is always that we are happy to provide some free data but we also have services to let companies run their own workloads in our lab, such as with our DemoEval service. What we do provide is an extremely controlled environment where we know every step is exactly the same and each run is done in a real-world data center, not a test bench.
We are going to show off a few results, and highlight a number of interesting data points in this article.
Python Linux 4.4.2 Kernel Compile Benchmark
This is one of the most requested benchmarks for STH over the past few years. The task was simple, we have a standard configuration file, the Linux 4.4.2 kernel from kernel.org, and make the standard auto-generated configuration utilizing every thread in the system. We are expressing results in terms of compiles per hour to make the results easier to read:
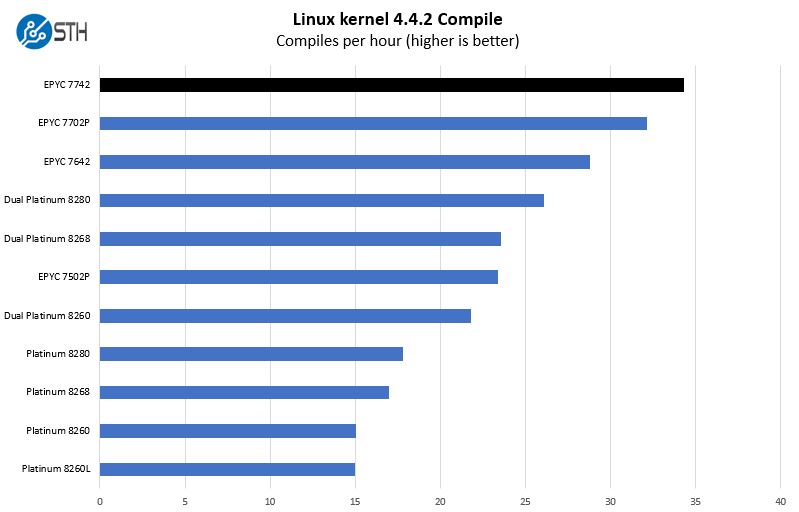
Here we see one of the more eye-catching charts. The top-of-the-line dual-socket Intel Xeon 8280 system is fourth on this chart. That is partially due to having two sockets instead of one as well as the larger caches. One will note, those are two themes that we highlighted in our introduction.
c-ray 1.1 Performance
We have been using c-ray for our performance testing for years now. It is a ray tracing benchmark that is extremely popular to show differences in processors under multi-threaded workloads. We are going to use our 8K results which work well at this end of the performance spectrum.
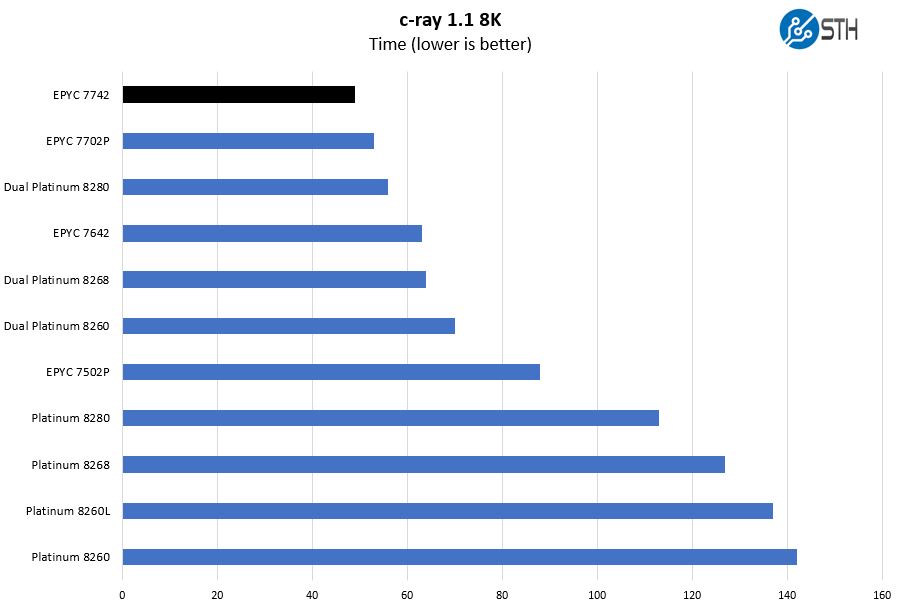
Typically AMD does well here, however, we see the dual Intel Xeon Platinum 8280 setup get relatively close to the single AMD EPYC 7742. If you saw our Crushing Cinebench V5 AMD EPYC 7742 World Record Edition, this is a similar result.
7-zip Compression Performance
7-zip is a widely used compression/ decompression program that works cross-platform. We started using the program during our early days with Windows testing. It is now part of Linux-Bench.
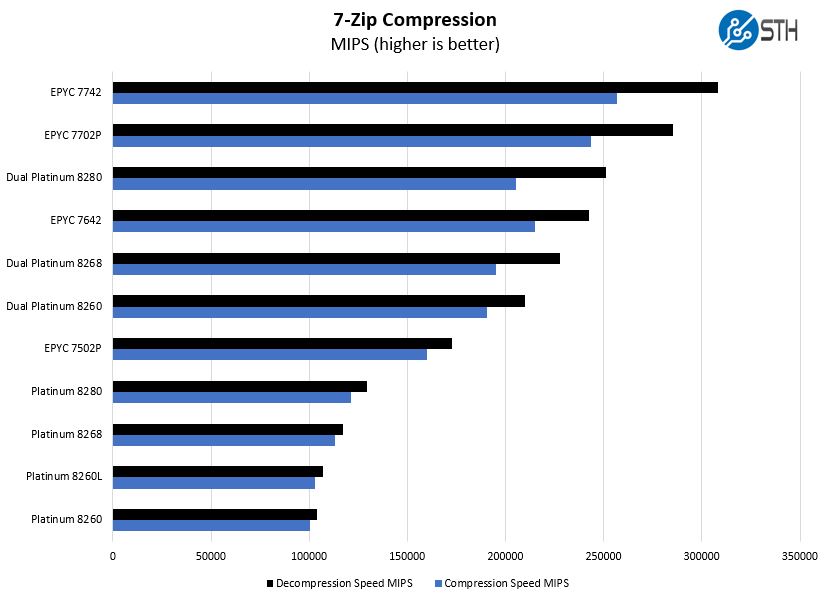
Moving to compression and decompression we see the AMD EPYC 7642 48-core part fall significantly behind. As an aside, that is another 225W TDP part from AMD. Here the extra cores more than compensate for the additional TDP per-core clock speed boost on the 48 core part.
NAMD Performance
NAMD is a molecular modeling benchmark developed by the Theoretical and Computational Biophysics Group in the Beckman Institute for Advanced Science and Technology at the University of Illinois at Urbana-Champaign. More information on the benchmark can be found here. With GROMACS we have been working hard to support AVX-512 and AVX2 supporting AMD Zen architecture. Here are the comparison results for the legacy data set:
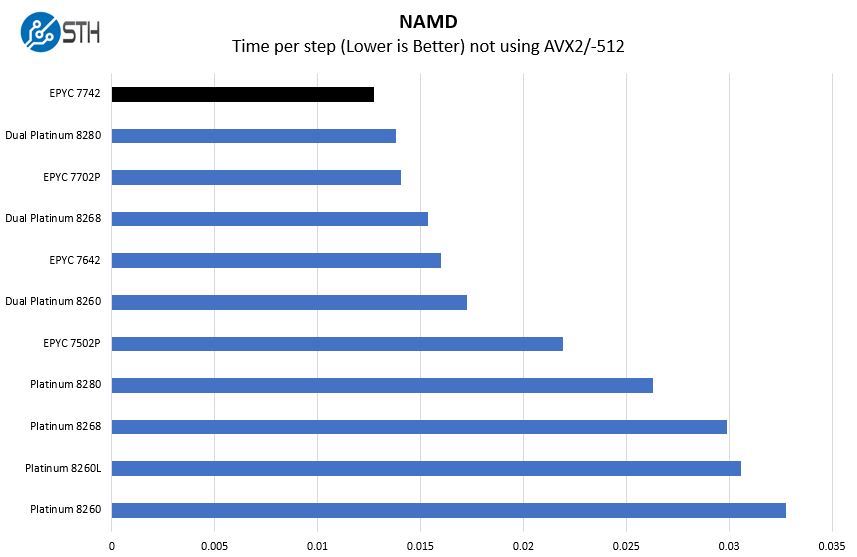
This is essentially code that is scaling to multiple cores but is not optimized for new instructions. A major question we get is what happens if you are using AMD EPYC with existing workloads. We generally advise that if you have a legacy application running in a VM you can move it to an EPYC host, and you will not notice a performance hit. Instead, you are likely to have a bigger pool of resources to work with.
OpenSSL Performance
OpenSSL is widely used to secure communications between servers. This is an important protocol in many server stacks. We first look at our sign tests:
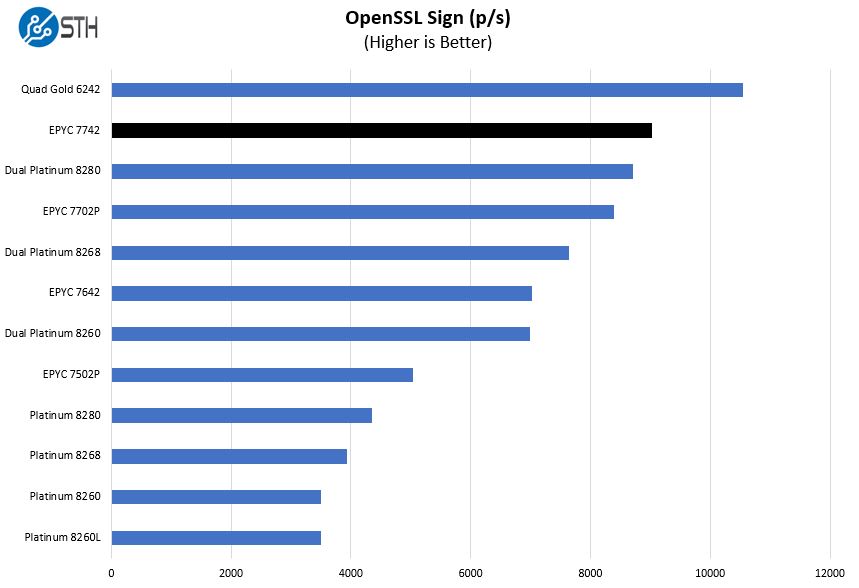
Here are the verify results:
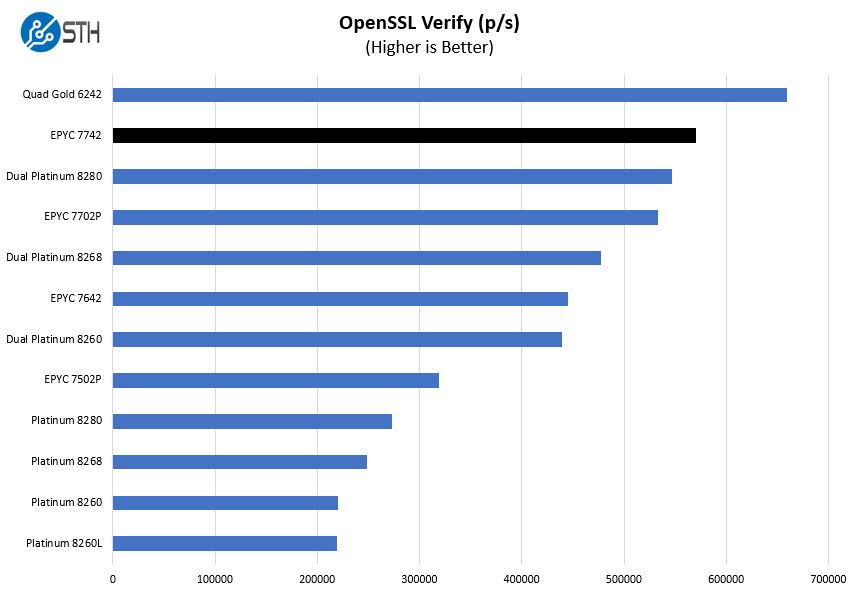
Here we added quad Intel Xeon Gold 6242 CPUs. 64 high-frequency Intel Xeon cores, with 24 DDR4 channels, and 600W of combined TDP are able to beat the AMD EPYC 7742 here. One can see the relative level that the quad CPU solution wins by, and we will let our readers judge if that is worth the trade-off. This is a good example of what we mean by Intel needs four socketed CPUs to equal 64 cores per socket. Frankly, this is one of Intel’s strongest plays versus the single socket AMD EPYC. It has the same number of cores and the same total memory capacity. PCIe lanes are higher but AMD still has the PCIe bandwidth advantage even with the single CPU.
UnixBench Dhrystone 2 and Whetstone Benchmarks
Some of the longest-running tests at STH are the venerable UnixBench 5.1.3 Dhrystone 2 and Whetstone results. They are certainly aging, however, we constantly get requests for them, and many angry notes when we leave them out. UnixBench is widely used so we are including it in this data set. Here are the Dhrystone 2 results:
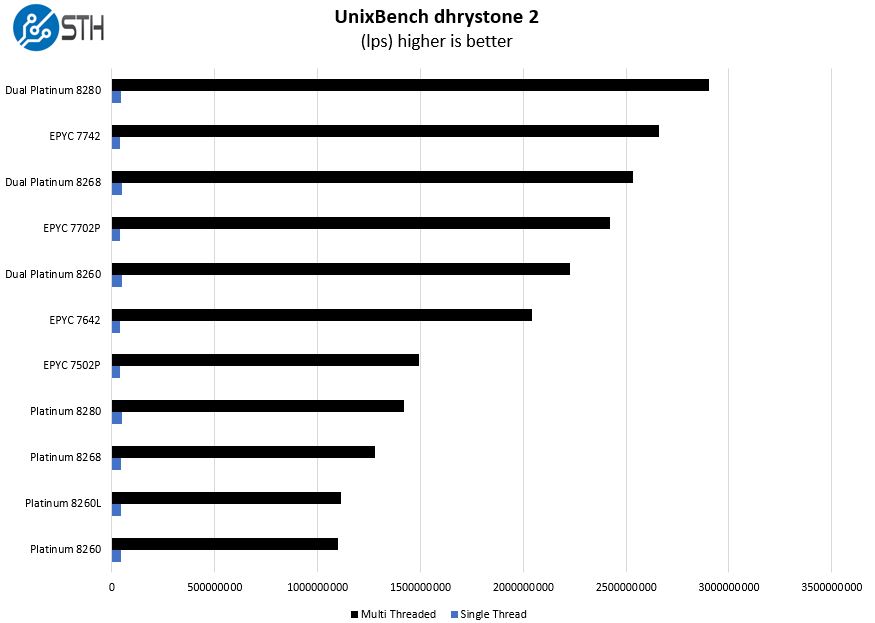
Here are the whetstone results:
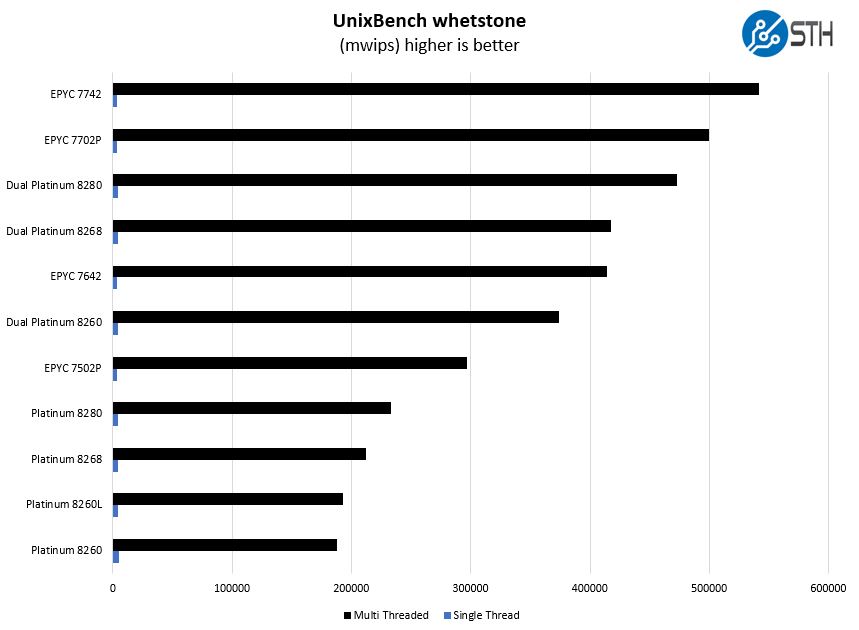
Here the dual Intel Xeon Platinum 8280 registers a split with the AMD EPYC 7742. That is still an impressive result for the single EPYC.
Chess Benchmarking
Chess is an interesting use case since it has almost unlimited complexity. Over the years, we have received a number of requests to bring back chess benchmarking. We have been profiling systems and are ready to start sharing results:
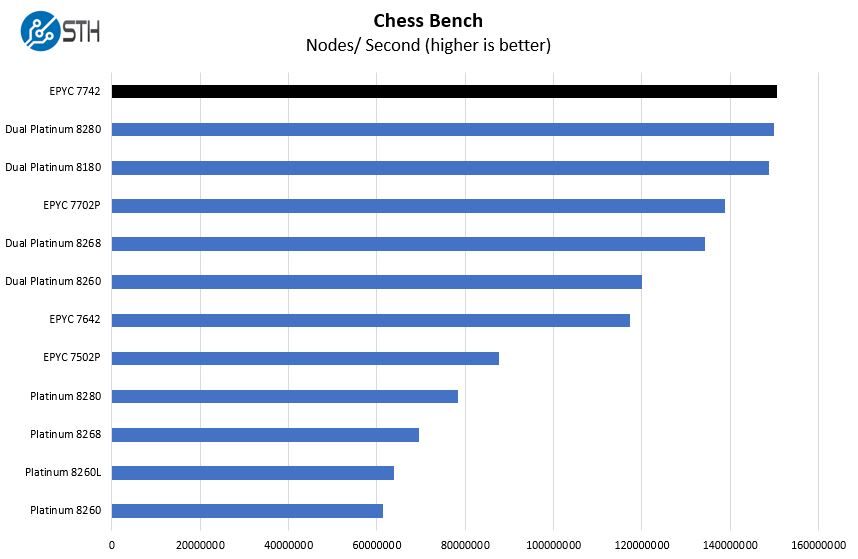
Here we have a very close EPYC 7742 and dual Platinum 8280 result. One of the reasons that the Platinum 8280 seems further behind is that it is a relatively muted upgrade over the previous-generation Platinum 8180. The mainstream Xeon Gold segment saw a big bump in core counts with this generation, but the maximum core count stayed the same at 28 cores.
STH STFB KVM Virtualization Testing
One of the other workloads we wanted to share is from one of our DemoEval customers. We have permission to publish the results, but the application itself being tested is closed source. This is a KVM virtualization-based workload where our client is testing how many VMs it can have online at a given time while completing work under the target SLA. Each VM is a self-contained worker.
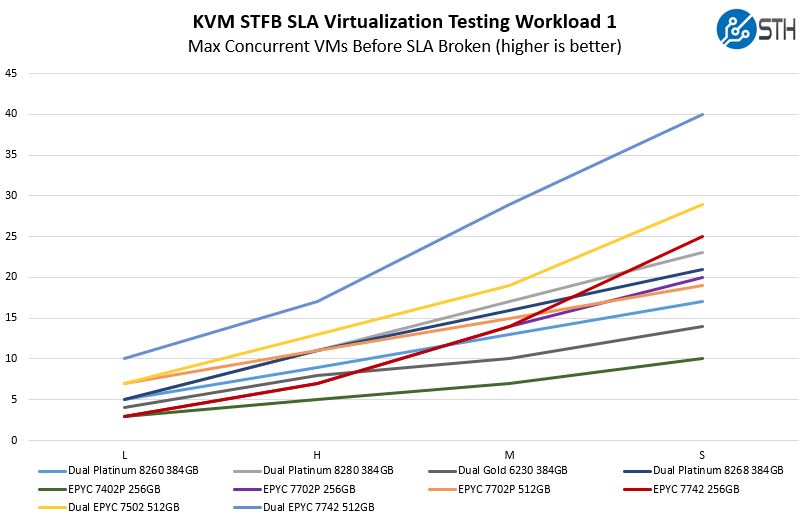
This is a bit hard to read with this many results, but we wanted to add the dual-socket results here. One can see that the single NUMA node AMD EPYC 7742 with more cores is doing better throughout the range than the dual Platinum 8280 setup. One can also see the dual EPYC 7742 setup is in another league versus dual Xeon Platinum 8280s.
AMD simply has an awesome platform for virtualization as one can more effectively utilize bigger pools of RAM and cores per NUMA node. Many of the HCI vendors such as Dell EMC with VMware vSAN have been focusing efforts on the AMD EPYC 7002 series.
Next, we are going to look at the AMD EPYC 7742 market positioning before moving to our final words.



{kind=link}
So basically the only reason you should even consider Intel is if they discount you 60% or you need AVX-512? What a fascinating time to be alive.
Really, a 60-70% Intel discount isn’t a good enough reason to stay with them. Absolutely needing AVX-512 or optane dimms is about the only reason.
Even if you get a 60-70% Intel discount you’re still getting it basically at what AMD charges, but you’re not getting the lower NUMA node count, lower TDP (hence lower electric/cooling costs), rack space savings, PCI gen4, etc, etc.
Thanks for not getting bogged in the weeds. Unlike your launch article, this is actually just right explain + data + editorial. You’ve gotten better.
“Most in the market will continue buying what they bought before.”
This is what we’ll be doing, for sure. Part of it is we just replaced ~half of our VM hosts 18 months ago with Intel (from HPE.) And since we would more likely than not be piecemeal replacing/adding additional servers in the future versus a forklift replacement, the pain involved from running VMware on split AMD/Intel isn’t work the headaches (no live vMotion.)
The other thing is that the person who makes the purchasing decisions isn’t interested in even looking at AMD’s cost/performance. In their mind, Intel is king and AMD is nothing but compatibility trouble. Since we aren’t currently up against a wall as far as colo power or space usage goes, the consolidation factor doesn’t do much for us.
How much longer before Micron launches a competitor to Intel’s NVM/3D-XPoint DIMMs and Micron has already announced its X100 NVMe SSD 3D-XPoint(QuantX branding) competition back in Oct of this year. AMD partners with Micron for GDDR6 along with others so maybe AMD and Micron can work up some Open Standards way of using XPoint based DIMMs on the Epyc/SP3, newer, platform and hopefully that development is already ongoing so that will remove one more reason to choose Intel.
However long it takes AMD to move up from Rome’s AVX256 to AVX512 AMD still has its GPU accelerator products for massive DP FP workloads but is that AVX512 market large enough to go after at this point in time for AMD on CPUs. Epyc/Milan is sure to improve performance once that CCX Unit construct is supplanted by just the 8 core CCD-DIE that shares among its 8 CPU cores the CCD-DIE’s total allotment of L3. And with the only question remaining to be answered is concerning the Zen-3 CCD-DIE’s actual Fabric Topology and will that be a Ring BUS(CCD Die Only) with inter CCD-DIE Infinity Fabric On Package interfacing or some more complicated topology with lower latency as well.
Epyc/Rome really marks the return of wider server/HPC market support for AMD with Epyc/Naples getting AMD’s foot back in the door in the mainstream server market. While AMD is getting some more HPC design wins with Epyc/Rome there are some larger supercomputer/exascale design wins that will be using custom Zen-3 Epyc/Milan offerings specifically targeting Direct Attached Radeon GPU accelerator interfacing via xGMI(Infinity Fabric) Links. So that’s similar to what Nvidia’s NVLink/NVLink2 is doing to interface the Tesla GPU accelerators to OpenPower Power9/Power10 on some HPC design wins.
AMD’s yearly Zen based CPU hardware/micro-architectural update cadence is now in full swing with no signs of any rough patches currently and TSMC’s 5nm apparently progressing faster than was expected. TSMC entered high volume production of its 7nm+ node in Oct 2019 and maybe some of that 20% density improvement claim will go into larger 8 core CCD-Die shared L3 or even AVX512 on some Epyc/Milan offerings.
Guy I think that’s the exact audience behavior he’s talkin’ about.
“The other thing is that the person who makes the purchasing decisions isn’t interested in even looking at AMD’s cost/performance. In their mind, Intel is king and AMD is nothing but compatibility trouble.”
Nobody ever got fired for buying Intel eh? …
When we will see the updated NAMD scores…? I’m really interested to see the uplift if any…
Support for Intel Optane NVMe SSDs is not a substitute for the Optane DIMMs in the new in-memory database applications that are taking advantage of Optane. Oracle is an example.
https://www.oracle.com/corporate/pressrelease/oow19-oracle-intel-partner-optane-exadata-091619.html
According to this article, Cooper Lake has been sampling since May. I presume big customers like FB are already using it. It would have 8 memory channels, avx512, bfloat16 and socketed 56 cores, according to the second link.
https://www.anandtech.com/show/14314/intel-xeon-update-ice-lake-and-cooper-lake-sampling
https://www.anandtech.com/show/14713/intel-to-offer-socketed-56core-cooper-lake-xeon-scalable-in-new-socket-compatible-with-ice-lake
Glad to see Tyan on the bench. They have a great AMD EPYC Rome story.
I’m looking at some DL325’s to replace an aging UCS environment from 2014. Was quite surprised at the lack of choice in HW vendors I had (out of the big players HP seemed to be the only ones that had something ready to go). My MSP seemed a little surprised I was asking about EPYC, too.
While on-prem hardware is no longer the flavour of the month where I am (and hasn’t been for some time) it’s still exciting for me to see how well AMD is doing.
Cooper Lake is still on 14nm, making TCO similar to 92xx Xeons. AVX 512 is no necessity in todays workloads (except AI HPC and other niches of course) Then you’re left with bfloat16, which is probably not utilized by anyone exept the HPC and AI guys, and Intel is left with the position AMD had when they launched Bulldozer for Server – funny how things changed
EPYC 7742 is definitely peerless in 2-CPU servers (comparable to quad 8280 which cost $$$$$).
For 1-CPU servers EPYC 7702P and/or dual 7452 are likely to have significantly better price-performance for most workloads.
@JayN, did you know that electricity is not free?
Also, am I the only one wondering why nobody says to these 99% intel discount arguments that giving discounted prices for high volume orders is not illegal for AMD either?
Just doing a refresh here and moving to all 7702P’s for virtualization hosts. When looking at Intel discounts it doesn’t even come close let alone the per-socket licensing savings. The only outside cost increase is with the WS DC farms which I’m sure Microsoft will be happy when renewals come.
Would AVX512 be nice to have? sure, but for the few workloads that really benefit a couple of GPU’s can handle the bulk of the use cases better for less $$$.
are the updated gromacs or other AVX512/256 results going to be posted in the end? We see them “promised” with the updated gromacs code for many reviews now, but nothing so far, or am I overlooking something? Thank you!
Stan – it took a while to get it stabilized. Now having to re-run everything which means swapping processors. Each swap means a trip to the data center. Slow going. We have been debating in the team whether to just move to a 2020 version and use a larger model as our standard going forward.
Please, *always* provide single core benchmarks even for server CPUs. There a lot of *very* expensive commercial software providers which sell licences per CPU core / per month, and so to pay less for those licencing fees one has strong incentive to buy servers with as fast single cores as possible. However, often all the benchmarks published focus on multi-core performance only.
We have been doing some network latency testing via sockperf using low latency NICs (from Exablaze). Sadly the latency is rather 3000ns instead of 700ns. Does anyone know of a special configuration to get these Dell/AMD boxes into a low latency mode ? We did use the right pcie slots… run cpus at full speed. have set kernel optimizations.
Comments are closed.