
Habana Labs recently presented at Hot Chips 31. The company has a few distinguishing points that were not directly in their presentation, but are perhaps a bigger deal. First, they are one of a handful of AI hardware startups with a working hardware and software ecosystem. Second, Facebook is investing in their platforms even while they use NVIDIA today and have been a major Intel Nervana development partner. That says a lot. NVIDIA and Intel have broader portfolios to cross-incentivize the use of their parts, yet Facebook sees something in Habana Labs that made them take notice. In this article, we are going to look at what the company presented, and show why it may be attractive to Facebook and others.
Habana Labs Goya for Inferencing
Habana Labs is doing something different than many AI hardware startups. It is targeting both training and inferencing workloads. On the inferencing side, its solution is the Habana Labs Goya.

The Habana Labs Goya HL-1000 PCIe card is different than many others on the market. The cards are dual width whereas the NVIDIA Tesla T4 and cards like the Xilinx Alveo U50 FPGA cards are low profile, half-length, single-width cards to enable easier edge deployments. The Goya instead assumes it can basically be twice as fast as an NVIDIA T4 so it can command double-width for inferencing.
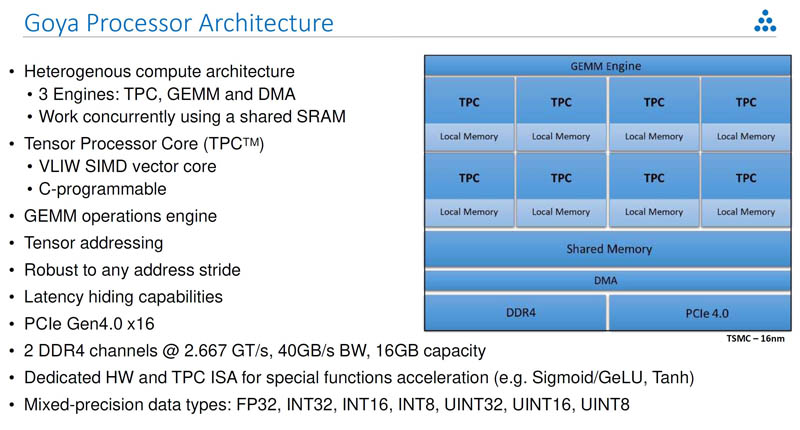
Like the company’s training parts, the Goya has its Tensor Processor Core (TPC), GEMM, and DMA engines onboard with shared SRAM memory. This solution uses DDR4 instead of HBM on the training parts. It has a PCIe Gen4 host interface instead of also having 100GbE which is key to the training parts.
Habana Labs Gaudi for Training
On the training side, Habana Labs has a higher-end architecture that has four HBM packages integrated. Here Habana Labs is exploiting higher memory bandwidth and deep learning training optimized compute blocks to drive performance. The device itself is also a PCIe Gen4 x16 device like the Goya.
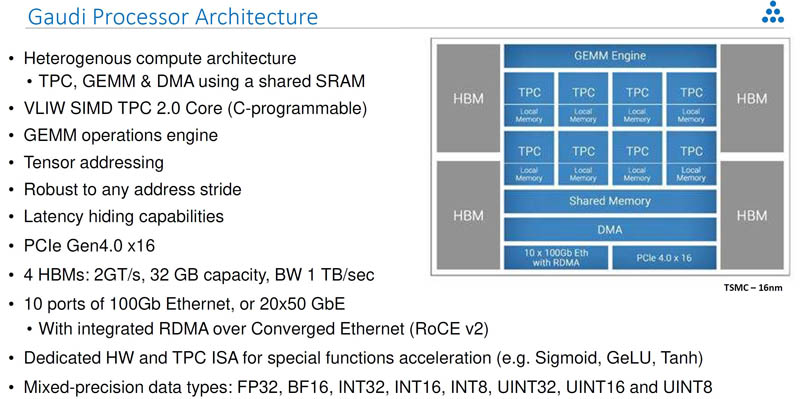
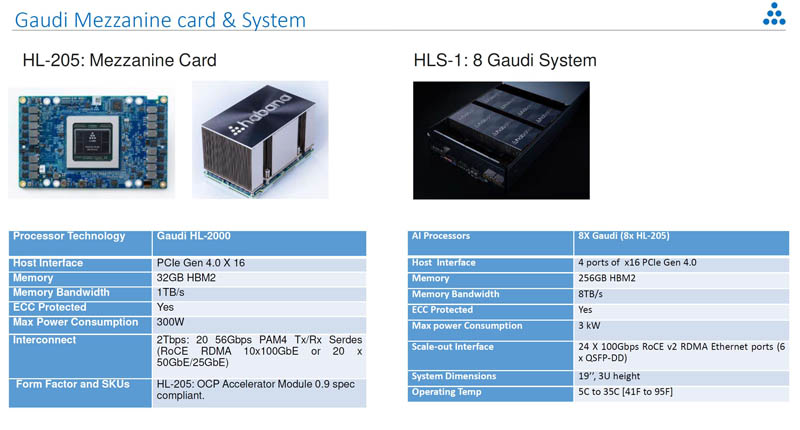
Aside from the bfloat16 support, and higher compute/ memory capacity, there is one feature that sticks out on the Habana Labs Gaudi versus the Goya: 10x100GbE. Each chip is designed to use 100GbE RoCE V2 RDMA to scale-out its communication with other Goya processors. The Habana Labs Gaudi HL-205 is an OCP OAM v0.9 solution. If you read about Facebook OCP Accelerator Module OAM Launched or Facebook Zion Accelerator Platform for OAM, and our STH Interview with Bill Carter of OCP and John Hu of Inspur you will notice that OAM is set to be the form factor hyper-scalers will use to standardize platforms and avoid vendor lock-in (e.g. NV-Link). Habana labs is designed for this system and already has a working 8-way Gaudi OAM platform with the HLS-1.
The chips themselves look fairly similar to an NVIDIA Tesla V100/ P100 with the main compute chip flanked by two HBM packages on each side. This generation’s training part is called the HL-2000.

Here is the back of the card. You will notice that this is the same form factor as we saw the Intel Nervana NNP L-1000 OAM packaged in. Habana Labs is using the OAM form factor to provide a path to cool 300W parts and also deliver an enormous amount of I/O from its cards.

Here is a look at the Habana Labs HLS-1 8x Gaudi OAM platform:
The front of the chassis is full of 24x100GbE ports plus four PCIe Gen4 x16 host interface ports. In contrast, the Gigabyte G481-S80 8x NVIDIA Tesla GPU server we reviewed had four PCIe Gen3 slots which could handle just under 500Gbps of aggregate bandwidth. The Habana Labs solution has over 6 times the external I/O power of a typical NVIDIA DGX-1/ DGX 1.5.
For those that do not want to switch to the OAM form factor, Habana Labs also has a PCIe solution. This was called the Habana Labs Gaudi HL-2000 PCIe card.

Naturally, these were put into an 8x card chassis providing a similar solution to the Inspur Systems NF5468M5 8x GPU server we reviewed. That is less dense than some of the popular NVIDIA training solutions we have seen such as the DeepLearning11: 10x NVIDIA GTX 1080 Ti Single Root Deep Learning Server (Part 1). Still, it allows for easy integration into existing form factors.

Each card has dual 100GbE even on the PCIe version. With each Gaudi HL-2000 chip having its own 100GbE controller, two things happen. First, one does not need a Mellanox 100GbE/ Infiniband card. Second, one does not need to have the PCIe switch we found in the DGX-1 that effectively shares one NIC per two GPUs. Instead, one avoids the cost and small latency of the PCIe switch and can go directly out to the network with more bandwidth.
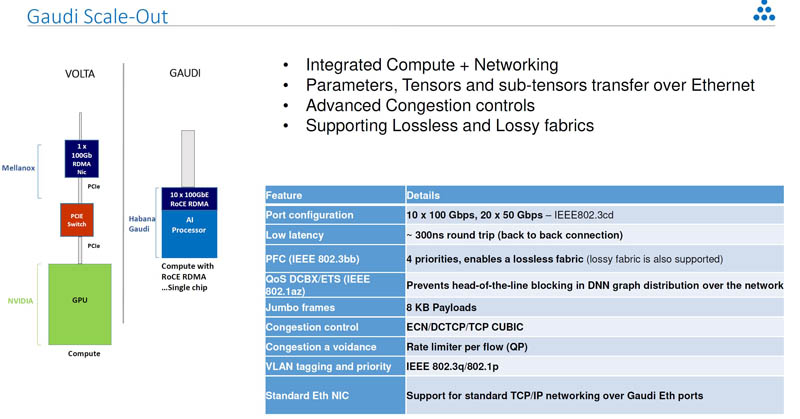
Indeed, the company is specifically targeting the DGX-1 with its HLS-1. It is showing its 2.4Tbps RDMA RoCE V2 networking and simplified topology.
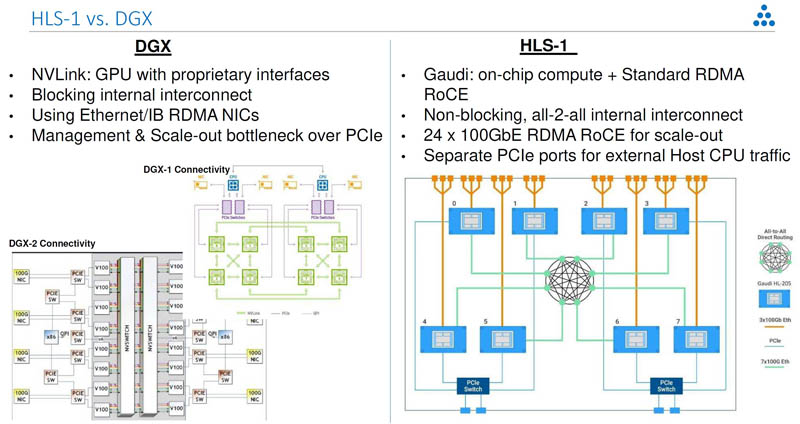
With the focus on the OAM platform and mature hardware that can be shown off, it is easy to see that Facebook is a major supporter of Habana Labs. Hyper-scalers tend to like having everything on one type of network fabric (e.g. Ethernet) since it allows the organizations to scale and leverage their existing infrastructure easily.
Final Words
Beyond the hardware, part of Habana Labs’ secret sauce it is software stack that helps efficiently map training and inferencing tasks to its compute engines, onboard memory, and scale-out topology. The fact that the company has gotten this far in the Facebook OAM ecosystem shows that the company has figured this out to the point where Facebook is putting them on slides along with NVIDIA, Intel, and AMD for its next-generation training platforms. If you were keeping tabs on threats to NVIDIA’s training business, Habana Labs is one that you should follow closely as it has a hardware/ software platform for training at scale and inferencing. There are many AI startups with ideas, but this is something that has at least Facebook’s attention.
One item I wanted to mention is that I tried asking the company’s reps at their Hot Chips 31 (2019) table on Sunday about how one gets started in their solution. The answer was something like “you send us your problem, we run it, if you like the results, you can buy a HLS-1.” That is fairly typical of companies that are set up to sell to hyper-scale companies. To reach beyond the hyper-scale crowd, the company is going to need to get a marketing strategy and story together beyond that type of sales cycle. NVIDIA has a robust channel ecosystem and has a path where people can start on gaming GPUs and migrate up the stack to dual NVIDIA Titan RTX solutions and into servers. The company will need to bridge that gap to get to higher-margin segments of the market, but they have the hardware and likely software to do so today.



{kind=link}
Was there any hints pointing to what the TFLOPs or TOPs are for these accelerators?
Comments are closed.