
At GTC Japan, NVIDIA announced a new data center GPU designed for AI inferencing. The new NVIDIA Tesla T4 is based on the NVIDIA Turing architecture. The company also announced the NVIDIA AGX platform, a common platform for building intelligent machines. The common threads of the new product launches are that NVIDIA is pushing Turing out to more areas of its userbase.
NVIDIA Tesla T4 AI Inferencing GPU
The NVIDIA Tesla T4 replaces the previous generation NVIDIA Tesla P4 GPU launched in 2016. The goal of GPUs in this line is to provide a single width card slot form factor design and a low power envelope to minimize internal cabling within a server. The other goal of the Tesla P4, and now the Tesla T4, form factors is to fit a wide variety of applications. NVIDIA and its server partners are banking on the concept that by making a lower-power single-width card, it can be deployed into a variety of servers.
We have covered quite a bit of NVIDIA Turing in the following pieces:
- NVIDIA RTX Turing Launch Livestream
- NVIDIA GeForce RTX 2080 Ti 2080 and 2070 Launched
- NVIDIA Turing Introduced with the Quadro RTX Line
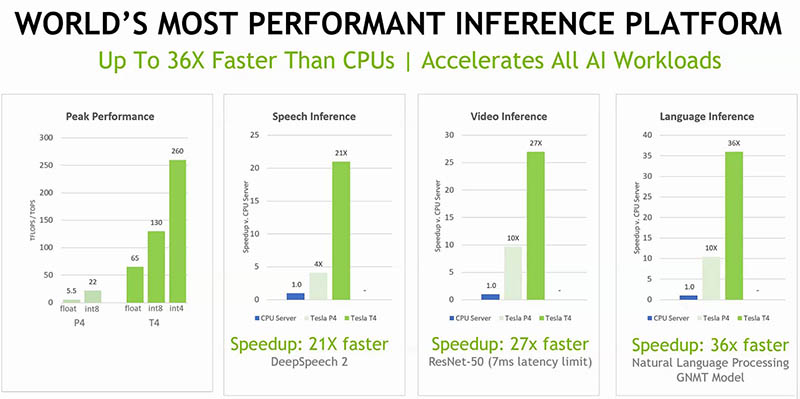
Key specs on the NVIDIA Tesla T4 AI inferencing GPU:
- 320 Turing Tensor Cores
- 2,560 CUDA cores
- FP32 to FP16 to INT8, as well as INT4 support. 65 teraflops of peak performance for FP16, 130 teraflops for INT8 and 260 teraflops for INT4
- 75-watt TDP
- Passively cooled
The key here is that by turning to Turing, those running infrastructure can use tensor cores a feature previously only available in the NVIDIA Volta generation GPUs.
NVIDIA Xavier Invades with NVIDIA AGX
The other key theme that came out of today is that NVIDIA is putting a lot of effort behind Xavier, its Arm-based edge device platform. Unlike the Tegra, Xavier has a number of processors dedicated to accelerating machine vision and other types of tasks typically required to automate machines in the field. At GTC Japan the focus was on robotics, but the platform is being pushed further. One area is into healthcare. There NVIDIA has Clara, for healthcare. Another big area is automotive. The company is trying to further productize the family calling it the NVIDIA AGX. This is a family of Xavier based models designed with different form factors to service different types of intelligent machines.

NVIDIA gave an update on their Drive Pegasus and said that the “next-gen” GPUs were indeed Turing based. That means that NVIDIA is effectively integrating Turing into other parts of its platform agenda. Overall, this is a new growth vector for NVIDIA, potentially displacing Intel and AMD from places like autonomous cars and healthcare industry machines.



{kind=link}
I want to see every high tech company “put and or shut up” with regards to AI claims. That is, present a true working AI platform or stop the efforts at FRAUD for there is no AI in this world and will not be a long time, if ever. Else do the world a favor and produce the holy grail in computing a write an AI program that will know and where in advance another computer program will if at all, crash. Deep diving algorithms do not constitute AI, for all correct solutions are with in predefined parameters, no system or algorithm yet to produce out of parameter solutions that are correct or even repeatable. All of the talk on AI is just a new marketing strategy to exploit those less knowing of AI to get them to buy more of the same wet dream that goes back to Fuzzy Logic. Just because logic gates can produce correct solutions, does not make it AI, like no calculator is AI. The next path to abysmal results from all hype will most likely be quantum computing.
AI already exists. Is it self-aware? No. And it’s not a bunch of IF statements or fuzzy logic either.
https://theconversation.com/understanding-the-four-types-of-ai-from-reactive-robots-to-self-aware-beings-67616
AI doesn’t have to be Commander Data or R2D2 to be called AI.
Correction to the specs in the article: FP16 performance should read 65 TFLOPS rather than 5; looks like a typo, and those are all peak tensor ops. Also, Single-Precision performance on the normal cuda cores is 8.1 TFLOPS, and the card contains 16GB GDDR6 @320GB/s.
This thing would make an awesome little Cuda card for virtualized docker hosts with PCI passthrough. 7-8 of these in 2U with a 32-core Epyc.
Comments are closed.