
Today we are showing off a build that is perhaps the most sought after deep learning configuration today. DeepLearning11 has 10x NVIDIA GeForce GTX 1080 Ti 11GB GPUs, Mellanox Infiniband and fits in a compact 4.5U form factor. There is also an important difference between this system and DeepLearning10, our 8x GTX 1080 Ti build. DeepLearning11 is a single-root design which has become popular in the deep learning space.
At STH, we are creating more deep learning reference builds not just as theoretical exercises. These machines are either being used by our team or our clients. We have done a number of smaller builds including DeepLearning01 and DeepLearning02 that we published. While those builds were focused on an introductory, getting your feet wet with frameworks, DeepLearning11 is a completely different end of the spectrum. We know this exact framework is used by a top 10 worldwide hyper-scale / deep learning company.
DeepLearning11: Components
If we had asked NVIDIA would probably have been told to buy Tesla or Quadro cards. NVIDIA specifically requests that server OEMs not use their GTX cards in servers. Of course, this simply means resellers install the cards before delivering them to customers. As an editorial review site, we do have tight budget constraints so we bought 10x NVIDIA GTX 1080 Ti cards. Each NVIDIA GTX 1080 Ti has 11GB of memory (up from 8GB on the GTX 1080) and 3584 CUDA cores (up from 2560 on the GTX 1080.) The difference in price for us to upgrade from GTX 1080’s was around $1,500. We did purchase cards from multiple vendors.
Our system is the Supermicro SYS-4028GR-TR2 which is one of the mainstay high-GPU density systems on the market. The -TR2 is significant as it is the single root version of the chassis and different from DeepLearning10’s -TR dual root system.

Like with the DeepLearning10 build, DeepLearning11 has a “hump” bringing the total system size up to 4.5U. You can read more about this trend in our Avert Your Eyes from the Server “Humping” Trend in the Data Center piece.

This hump allows us to use NVIDIA GeForce GTX cards in our system with their top facing power ports.
We are using a Mellanox ConnectX-3 Pro VPI adapter that supports both 40GbE (main lab network) as well as 56Gbps Infiniband (deep learning network.) We had the card on hand but using FDR Infiniband with RDMA is very popular with these machines. 1GbE / 10GbE networking simply cannot feed these machines fast enough. We have installed an Intel Omni-Path switch in the lab which will be our first 100Gbps fabric in the lab.

In terms of CPU and RAM we utilized 2x Intel Xeon E5-2628L V4 CPUs and 256GB ECC DDR4 RAM. We will note that dual Intel Xeon E5-2650 V4 are common chips for these systems. They are the lowest-end mainstream processor that supports the 9.6GT/s QPI speed. We are using the Intel Xeon E5-2628L V4 CPUs since single root design bestows another important benefit, no more inter-GPU QPI traffic. Although we have heard one can use a single GPU to power the system, we are still using two for more RAM capacity using our inexpensive 16GB RDIMMs. These systems can take up to 24x DDR4 LRDIMMs for massive memory capacity.
We are going to do a single-root piece soon, but for those deep learning folks using building blocks such as NVIDIA nccl, a common PCIe root is important. That is also a reason that many deep learning build-outs will not switch to higher PCIe count but higher latency/ more constrained designs like AMD EPYC with Infinity Fabric.
System Costs
In terms of a cost breakdown, here is what this might look like if you were using Intel E5-2650 V4 chips:
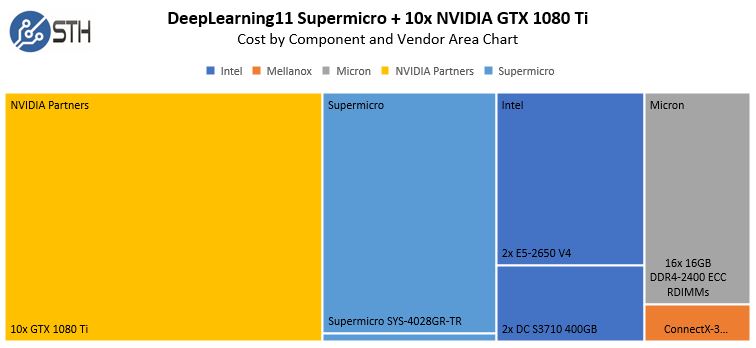
The striking part here is that the total cost of about $16,500 has a payback period of under 90 days compared to AWS g2.16xlarge instance types. We will include hosting costs below to show how that compares on a TCO basis.
Comparing the DeepLearning11 10x GPU example to DeepLearning10 with its 8x GPUs, you can see that the ~25% performance bump comes at a relatively little expense in terms of overall system cost:
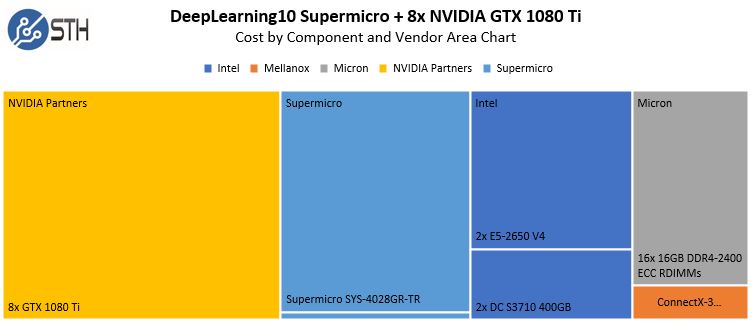
As one may imagine, adding more GPUs means that the overhead of the rest of the system is amortized over more GPUs. As a result, if your application scales well, get 10x GPUs per system.
DeepLearning11: Environmental Considerations
Our system has four PSUs, which are necessary for the 10x GPU configuration. To test this, we let the system run with a giant (for us) model for a few days just to see how much power is being used. Here is what power consumption of the 10x GPU server looks like as measured by the PDU running our Tensorflow GAN workload:
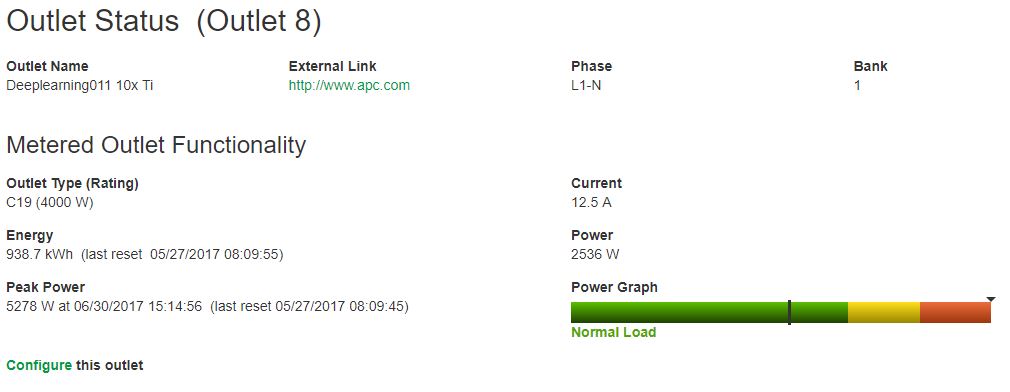
Around 2600W is certainly not bad. Depending on where the model was in training we saw higher sustained power consumption in the 3.0-3.2kW range on this machine without touching the power limits on the GPUs.
You will notice there was an enormous 5278W peak, during some password cracking, more on this in a future STH piece. The peak during a few weeks using different problems and frameworks in the deep learning field was just under 4kW. Using 4kW as our base, we can calculate colocation costs for such a machine easily.
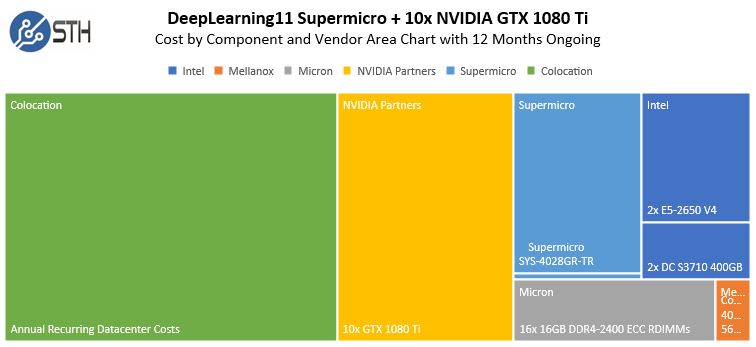
As you can see, over 12 months, the colocation costs start to dwarf the hardware costs. For these, we are using our actual data center lab colocation costs. If you want to build a similar cost model, we are happy to provide contact information with who we use so you can replicate the above. These are not theoretical numbers, we are actually spending around $1k/ month to run this system in the data center.
Compare the above to DeepLearning10 with 8x GPUs and you can see the impact of adding ~500W of additional compute:
Adding additional GPUs adds operational costs in-line with system costs compared to DeepLearning10. Moving into subsequent years, colocation costs will far exceed hardware costs.
DeepLearning11: Performance Impact
We wanted to show just a bit about how much performance we gained out of the box with this new system. There is a large difference between a $1600 system and a $16,000+ system so we would expect the impact to be similarly large. We took our sample Tensorflow Generative Adversarial Network (GAN) image training test case and ran it on single cards then stepping up to the 10x GPU system. We expressed our results in terms of training cycles per day.
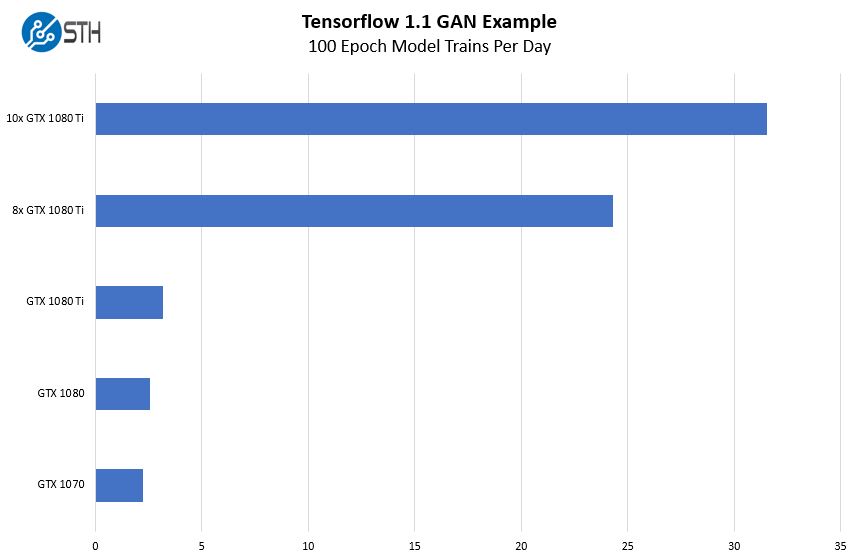
This is a great example of how adding $1400 or so more to the purchase price of the system yields tangible results. Whereas a single NVIDIA GeForce GTX 1080 Ti allows us to train the model once every eight hours, a 10x GPU box lets us train on a greater than hourly cadence. If you want to make progress in a work day, a big box, or a cluster of big boxes helps.
Final Words
As one may imagine, DeepLearning10 and DeepLearning11 use a lot of power. Just those two servers alone are averaging over 5kW of consistent power draw with spikes going much higher. That has major implications for hosting as the “hump” adding 0.5 RU is not significant in many racks. Most colocation racks cannot deliver 25kW+ of power and cooling per rack to fill them with GPU servers. We often see these hosted with 2 GPU compute machines per 30A 208V rack so placement and blanking become important.
In the end, we wanted to have a significant single root system in the lab and we have that with DeepLearning11 and its 10x NVIDIA GTX 1080 Ti 11GB GPUs. Since we advocate scaling up the GPU size first, then the number of GPUs per machine, then to multiple machines, DeepLearning11 is both a great top-end single machine but also as a platform to scale out to multiple machines based on the design. There are some features such as GPUDirect using RDMA that are great on this platform assuming your software and hardware stack can support them. We are practically limited by budget so we got the best cards we could afford, the GTX 1080 Ti.



{kind=link}
If I understand correctly, you have all the GPUs connected to only one CPU via PCIe switches? So, why do you need the second CPU?
RAM capacity without having to shell out $$$$ for larger capacity DIMMs. Cheaper to get a second CPU to gain access to be other DIMM slots.
RAM capacity. Cheaper to get a second CPU and gain access to those DIMM slots than to buy more $$$$ expensive larger capacity DIMMs.
Hate the hump. It costs $25/month in rackspace.
Right angle connectors or going to “Full 0.5U” (un-hump) and sucking air in the front seems more useful.
The only time a hump is good is on a Camel or a Car hood. Humps on a female human is also good, many animals go without since they would drag.
The only thing ‘wrong’ is these Cards aren’t 24/7. I wouldn’t worry about the DP FP with those prices.
With water cooling you could have narrower Cards and use the 0.5U to run some Tubing.
Using two 4 Slot PCI-E 16X 90 Degree Right Angle Riser Cards and one GPU not on a Riser (directly plugged in) would also be worth investigating; I did the Math and that’s 9 double wide in 4U, with water cooling you could double that.
Is Rob a really good chat bot?
$25 / mo for 0.5U of rackspace? These use $1k/ mo in power and you need to be buying full racks to operate even one of them. If you’re buying 4kW of power for a single system colo nobody’s charging you $25 for as 5th U. With 8 of them in a rack and room for switching that’s 32kW or like $8K-10K/ mo.
Why aren’t they 24/7? Usually the loads aren’t 100% 24×7. Everyone’s using the reference designs so they’ll work fine. If you’re using a 10 GPU machine 8 quarters would be a long time for them to run and they’ll still be under warranty. Nobody’s buying 10 1080Ti’s for AI and expecting them to run 5 years lol.
Watercooling it’d need to be facility driven. Everyone just makes fans run at 95-100 percent. Takes 5 min and saves a few thousand. Keeps cards cool.
90 degree huh? If you’ve got much more than 10 you run into power and cooling issues unless you have datacenter watercooling. If you’ve got datacenter w/c then you’re buying DGX-1 class not these.
People with thousands of GPUs and budgets upwards of six figures monthly have evolved it to this kind of 10 GPU. If it was as easy as add w/c those people would’ve already done it. You’re talking top HW and SW minds working with this stuff because there’s so much money in it all.
Sum, Who’s the Chat Bot – Don’t use Google Translate to read and respond to Posts; between your lol and 90° It’s clear you don’t understand what’s being said.
—
Patrick, you might find NVidia’s P2P useful to test your System: http://docs.nvidia.com/cuda/cuda-samples/index.html#peer-to-peer-bandwidth-latency-test-with-multi-gpus .
Microway did some Bandwidth Tests that might give you a head start: https://www.microway.com/hpc-tech-tips/comparing-nvlink-vs-pci-e-nvidia-tesla-p100-gpus-openpower-servers/ .
So the NVIDIA GTX 1080 Ti has driver support for RDMA with Mellanox cards if I’m reading this correctly.
Do the 1080s, 1070s and 1060s support RDMA via Mellanox cards either directly or via a hack?
1.you didn’t use SLI?
2.1080ti support GPUDirect peer-to-peer transfers and memory access?
long nobody uses SLI for AI servers
sth did p2p using theses GPU https://www.servethehome.com/single-root-or-dual-root-for-deep-learning-gpu-to-gpu-systems/
Adi ?thanks a lot.
After p2p is ok , my 4x 1080ti is working well in the right OS (ubuntu server) .I used the ubuntu desktop before
could you explain more about single root / dual root ?
Single root means that the PCIE lanes are provided by the same CPU ? That means you have 40lines(for Intel Xeon E5-2650 V4) shared for those 10 GPUs ? that means each GPU uses a 4x PCIe ?
Dual root will mean that each card uses 8x PCI(5 cards per CPU) but you will loose when you have to send memory for the first group of 5 cards to the other 5 cards ?
How this translates in real life ? From your 8x dual-root system seems to the 10x single root seems that the performance scales linearly in tensorflow. Is just that NVIDIA nccl is not working in dual-root ? (or is it working but slower ? )
Could you like configure this 10x system(TR2) to use dual-root or could you change the 8x system (TR) to use single-root ? I mean is something like a switch on the motherboard or is a totally different architecture ?
Sorry for such a long list of questions and best regards,
Hi Adrian – we have a piece specifically on this topic: https://www.servethehome.com/single-root-or-dual-root-for-deep-learning-gpu-to-gpu-systems/
Like Adrian asked running two Intel Xeon E5-2650 V4 you will have 2 x 40 PCI-E lanes available. In a dual root setup you can run each GPU in x8 mode, assuming the motherboard allows you. But in single root you will only run in x4 mode. Running each card in x4 mode severely reduces bandwidth to each card, resulting in performance per card to drop.
For multiple GPU use, maybe the benefit of using single root vs. dual root out ways the performance hit you get from x8 -> x4.
For multiple single GPU use, i would expect this would not be an ideal setup at all. E.g. many different simulations/training/inference on a single card at a time?
Hi Jenma – that is not how these servers work. They use PCIe switches. Here is an overview https://www.servethehome.com/single-root-or-dual-root-for-deep-learning-gpu-to-gpu-systems/
I read the article and you talk about GPU to GPU bandwidth and latency which can be handled by PCI-E switches, i get that part. What i meant was CPU/memory to GPU bandwidth or latency. If you do not do multi-GPU training but multiple single instance GPU training, where GPU to GPU bandwidth/latency is completely irrelevant, then the main bottleneck would be the CPU/memory to GPU bandwidth limitation. This is limited by the number of lanes from the CPU to the PCI Express.
Thank you for the great article. I checked the motherboard on the Supermicro website (https://www.supermicro.com/products/motherboard/Xeon/C600/X10DRG-O_-CPU.cfm) and the PCI slots are listed as follows:
8x PCI-E 3.0 x16 (double-width) slots
2x PCI-E 3.0 x8 (in x16) slot
1x PCI-E 2.0 x4 (in x16) slot
Do you think that the slowness of one of the GPUs that you observed may be due to this configuration? Also, is the PCI-E 2.0 x4 slot sufficient for the Infiniband card?
Hi Patrick,
Thanks for this comprehensive article and for the nice photos of the server.
Just out of curiosity, what are the GPU core temps and clock frequencies (as reported by nvidia-settings) after running all 10 GPUs at full load and for at least 15 min? I suppose that all fans would be set at full speed under such a scenario.
Full fan mode ~60C IIRC.
Did you guys augment the power supplies? I’m sing 2X2000kw power supplies included with this chasis. Are you relying on both and forgoing redundancy?
I may have answered my own question. It looks like it’s 2×2 and each PS supplies 2kw.
Greg, there are 4x PSUs in this server.
Patrick, I just put together a similar system for DNN training using a Supermicro 4028GR-TR2, but using 8 GTX 1080 Ti. I am running into an “Insufficient PCI Resources Detected” I tested a number of different BIOS combinations after having researched the problem on line. Changed MMIOH and MMIO High Size. Also enabled Above 4G Decoding and excluded Slot 7 where NIC card lives and locked myself with a no boot issue a few times. I just can’t seem to get a combination that works.
The system disables some PCI devices and pauses with the error message into BIOS. After booting, it only sees 3 of the 8 GPUs. Do you recall what BIOS settings were used in your system?
Thank you.
Hi Lou and Patrick,
I’m in almost the same boat as you Lou. I’m setting up the Supermicro 4028GR-TRT2 for my university lab.
I’ve played around with a bunch of PCI settings, like Lou mentioned. However, I cannot get rid of the “Insufficient PCI Resourced Detected” Error.
I’m using 8x GTX 1080 Ti’s, and 2x ConnectX-5 VPI cards from Mellanox, all on the single root. I even disabled the SATA controller and and excluded Slot 7, but still can’t get rid of the error. I haven’t installed an OS yet.
Any insight if you find out the solution would be greatly appreciated.
Cheers
I have a system that has 8 x GTX-1080 Ti. However, recently our requirement has grown and planning to buy a new GPU machine. Can I buy another 8 x GTX-1080 Ti machine and make a cluster with the former machine? Will there be any bottleneck considering that GTX-1080 Ti doesn’t support GPUDirect RDMA? Is creating a cluster good idea or Should I buy separate machine with 16 x GTX-1080 Ti?
Thanks in Advance.
Cheers
Comments are closed.