
After a few months/ years of urging, in the last month or so my wife (disclaimer she works at NVIDIA) has voraciously taken to learning about machine learning / AI / deep learning. She has a background in math and computer science so once she started reading, she got hooked. At some point she started dropping hints like “you know, a lot of this deep learning stuff uses NVIDIA GPUs” and “my Apple does not have a GPU, it would be great if I could use something GPU accelerated.” I quickly took the hint. Instead of provisioning her a few GPU nodes in the STH/ DemoEval lab that have huge amounts of RAM, multiple GPUs, high-end CPUs and arrays of NVMe I realized this was not right.
Over the past two years, I have been asked to advise dozens of folks on simply the segment of starter machine learning / AI / deep learning systems. There is one aspect I have noticed in common: most people wildly overspend on GPUs for starter rigs and are less than happy with results. This article is real-world starter build for my wife. The hope is that others can use this as a template to build a desktop server that is right-sized for a starter build and can expand later.
The Build List
In the subsequent sections, we are going to explore the choices made in the build. Here is a quick list before we get started:
- GPU: ASUS GeForce 6GB Dual-Fan OC Edition DUAL-GTX1060-O6G
- CPU/ Motherboard: Intel Xeon D-1541 / Supermicro X10SDV-TLN4F (review here)
- RAM: 64GB (2x 32GB) DDR4 RDIMMs (Amazon example here)
- SSDs: 4x Intel DC S3500 480GB
- Chassis: Bitfenix Prodigy mITX Case
- Hot swap: Icy Dock ExpressCage MB324SP-B (review here)
- Power Supply: Seasonic 520w Fanless Platinum
Some of these items you could certainly customize but we had a few goals: reasonable costs, near silent operation, “fast enough,” and the ability to update in 6 months. In the next sections, we are going to explain these decisions in turn. We did scour for best prices and ended up spending just under $1700 on this build. We will also discuss options to cut a few extras and get the entire build sub $1000.

A GTX 1060 why not a GTX 1080?

In the world of GPU compute, NVIDIA is currently king. They have over a decade of experience making CUDA compute cards and are aware that their gaming GPUs are used as entry GPU compute devices. Since we have helped spec, build, and get feedback on many entry-level systems, there are a few vectors we optimize on:
- Get as much onboard memory as you can. Models that take up more space than the local GDDR5 allows end up slowing down significantly.
- Get as much CUDA compute as you can. Like in CPUs, more CUDA cores, in a given generation, mean more performance.
- Cost-optimize the platform. NVIDIA is all-in on deep learning/ AI, so we expect 2017 iterations to improve significantly. Look to upgrade GPU as user’s skills improve to take advantage of new technology.
Focusing on that last point, we have found that there are many people who buy extremely high-end systems to start endeavors in machine learning. There are two minor issues with this. First, as you are starting off, you likely are not using giant data sets and models. Most learning “NVIDIA DIGITS with MNIST” type classes/ models are relatively small and take, at most, single digit minutes to train. Importing pre-trained models and using more inference based applications is also common. Starting out, you are also unlikely to have the data to train, nor the experience to utilize multiple machines or GPUs effectively. Learning on small models seems to be common as feedback happens in seconds or minutes rather than days. By planning for a lower-end GPU at the outset that is right-sized for first endeavors, we can save money today to take advantage of tomorrow’s faster GPUs.
At STH we spend more than the cost of several GTX 1080’s on power and space in our data center colocation each week, so cost was not the paramount concern. Instead, we wanted to derive some metric on picking the best GPU for someone (e.g. my wife) who is in their first few weeks of deep learning. Here is the chart I came up with and shared with several folks in the community focused on GPU compute:
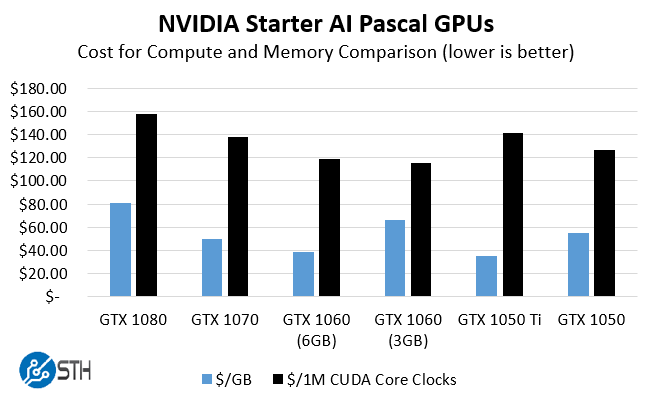
Raw performance wise, get a GTX 1080, Titan X (Pascal), Tesla M40 or whatever your budget allows. Looking at value, the NVIDIA GeForce GTX 1060 has a few features working in its favor. First, it has 6GB of GDDR5 memory onboard. While the memory bandwidth is lower than the higher-end cards, it is still significantly faster to use built-in memory rather than system RAM. Second, the 6GB model has more CUDA compute cores than the GTX 1060 3GB model (1280 v. 1152.) That helps lower the overall $USD per 1 million CUDA core clocks as we paid a $30 premium for the additional compute. We are taking clock speed (MHz) times CUDA cores and dividing by 1 million to get our 1M CUDA Core Clocks just to get the units manageable and graphable on the same relative scale. The real deciding factor was getting twice as much RAM on the GTX 1060 6GB versus the 3GB model. The NVIDIA GeForce GTX 1060 just happens to be the second lowest $/GB and the second lowest $/1M CUDA Core Clocks (MHz). While the GTX 1080 is a very popular card, you do pay a premium for higher-end compute and memory.
On why we picked the ASUS card, the reason was simple. We snagged one off of Amazon one evening for about $230, so it was priced right. In every CUDA application, we have used it with it has out-performed a GTX 970 while using noticeably less power.
CPU / Motherboard / RAM: Overkill?

We did go overboard a bit on the CPU motherboard and RAM. If you are just doing low-end GPU compute you can easily get by with a Core i5 or Core i7 on the desktop side, a low-cost Intel Xeon E3-1200 V3 or V5 on the E3 side or a Pentium D1508/ Xeon D-1518 on the Broadwell-DE side. We have a decision guide on buying Intel Xeon E3 v. Intel Xeon D which goes into more detail. We ruled out the Core i5 and i7 because I wanted the ability to have IPMI with a dedicated console GPU. It is also important if you are going to build a server, it acts as a server. Once you deal with colocated machines, IPMI and iKVM are near essential since you can remotely load OSes, troubleshoot computer issues down to the BIOS level and etc. Although both the motherboard and the GTX 1060 have video outputs, we never connected a keyboard, video, monitor nor optical/ USB drive to the machine.
On the Xeon D side STH now recommends all new systems use 10GbE as a minimum. We expect larger data sets to be stored on a ZFS NAS and there is a significant latency/ throughput impact by increasing network speeds tenfold. In 2017 we expect new servers to all have 10GbE, and that will be a rating criterion for STH reviews.

Going with the Intel Xeon D-1541 gives us 8 cores and 16 threads in a low power 45w TDP package along with 10GbE. The plan is also to use this machine for builds and transforming data so having more cores and saving tens of minutes a day seemed worth a few hundred dollars. The D-1518 is a great and 35w 4 core/ 8 thread model. If you just want GPU compute with 10GbE, check out the Pentium D1508. We have benchmarks of the D-1518 and D1508 to help make that decision.

RAM wise, you can certainly get by with 2x 16GB DIMMs but getting 2x 32GB means we can add two more 32GB RDIMMs in the future and not have to sell/ re-purpose smaller 16GB DIMMs. Luckily, the same DIMMs that work in our Intel Xeon D machines also work in Xeon E5 V3 and V4 machines, so it is easy to re-use the RAM later in larger servers. In fact, we have even put the same RAM into our Intel Xeon Phi 7210 (x200 series) 64 core/ 256 thread system. It costs a bit more, but we are firmly recommending 2x 32GB over 4x 16GB for future expansion.
SSDs: Cheap, Fast, and Redundant
Our SSD array is a RAID 10 setup that provides ~1TB of redundant local storage. It can also burst read speeds into the 1GB/s range which allows us to push data over the 10GbE NICs at wire speed. Another strong option was getting a m.2 NVMe SSD. We may add one later, but redundancy was required (happy wife, happy life.) We did buy the Intel DC S3500 480GB drives used off of eBay. We have purchased over 400 used enterprise SSDs and even publish our used enterprise SSD reliability data. You can read that link for more details, but our AFR is well below 0.5% now with several million hours tallied, or about 10x better using used SSDs than new hard drives.

Aside from going m.2 NVMe we also could have used larger SATA drives as they are inexpensive. We do steer clear of consumer drives as we have seen much higher failure rates with those. Datacenter SSDs are often not that much more expensive than consumer counterparts. Check the STH “Great Deals” forum where people post deals on used enterprise SSDs daily.
On the Icy Dock, we like their ExpressCage design. I was able to review one in 2015, and the tool-less drive tray design is great.
In the chassis we also have room for 2x hard drives. It would be very easy to setup a NAS and turning this into a dual purpose machine.
Chassis: Gaming Tower?
We wanted the build to be compact, but we also wanted to be able to fit larger GPUs. The BitFenix Prodigy is around $75 or less. It was also available with same-day prime shipping on Amazon so that was a matter of convenience. It even fits the ASUS GTX 1070 STRIX with its triple fan cooler without issue which will be important come Volta.

There is a lot of extra room in this chassis. We did a cluster-in-a-box build with three systems and two switches inside a few years ago. With the excess space we have plans to locate a small Raspberry Pi/ ODROID 64-bit ARM development cluster with a network switch.
We did replace the fans with some of the quiet Corsair coolers we use regularly which keeps the build sub 32dba.
Power Supply: I Screwed Up!
The Seasonic unit required using small spacers and we did not need to get the fanless model. Nor did we need to get a big 520w unit. Given the small power footprint of the Intel Xeon D/ Supermicro platform and the low power GTX 1060 we have seen very low power consumption. The 520w model was also too big. We need to use small spacers to get the unit to fit in the chassis (oops!)
To give one an idea, we tried running Monero crypto-currency mining to validate CUDA was working and that the CPU was going to stay cool. With just the CUDA miner the system used 100W +/- 0.5w on our Extech TrueRMS power meter. Adding in the CPU miner and the power consumption was around 130w. The insane power of the Intel Xeon D is the ability to provide 10GbE network and many cores in a low power envelope. 130w is easy to cool and in hindsight, we would have been better served buying a 300-400w class PSU
Our final tally, great PSU, but wrong application and user error in selection.
Final Words
It would be absolutely trivial to cut $600-800 off of the price of this build by using a lower core count Xeon D, using a smaller PSU and a single SSD or NVMe drive. You could do this while still retaining the same CUDA compute capabilities, the 10GbE networking, near silent operation and out-of-band iKVM/ IPMI management. At the same time, this build is intended to have the GPU replaced in 6-12 months as the user starts to work on larger data sets. For a starter build, the cost is around the price of a single Titan X (Pascal.) Instead of buying a large card and having it go to waste, we were able to build a system that will expand over a longer term. It can also be re-purposed into a colocated machine housed in a data center simply by getting an appropriate chassis.



{kind=link}
Thank you so much for this article! Sincerely appreciated! The overall power envelope of this setup is surprising to say the least.
Great article! You’re totally right. We bought an 8x Titan X Maxwell-gen server for one of our developers to learn on. What a waste! Sat almost bone idle for a year. I’d like to see the same build with a single slot cooler 1050 Ti. Save another $100+.
What about a cheap rackmount build?
I sent this to my co-workers. It just saved us a few grand. Very helpful.
Kudos for taking STH in this direction. We’ve just ordered the parts to make 3 of these systems for interns.
We ordered parts for two of these systems for the teachers at our kids high school. But we used a Corsair PSU. We’d have liked a $1-1.2k version but this was easy to follow
There’s a great writeup here:
http://timdettmers.com/2014/08/14/which-gpu-for-deep-learning/
Executive Summary:
The most important parameter for machine learning is memory bandwidth.
Based on benchmarks here is an approximate equivalence:
Titan X Pascal = 0.7 GTX 1080 = 0.55 GTX 1070 = 0.5 GTX Titan X = 0.5 GTX 980 Ti = 0.4 GTX 1060 = 0.35 GTX 980
GTX 1080 = 0.3 GTX 970 = 0.25 GTX Titan = 0.175 AWS GPU instance (g2.2 and g2.8) = 0.175 GTX 960
Every Nvidia card spec can be found here:
https://en.wikipedia.org/wiki/List_of_Nvidia_graphics_processing_units
I put these equivalence values into a spreadsheet for both new and used both new and used prices and reached the same conclusion: The 1060 is the best value.
What rack mount enclosure would you recommend for this build?
Chris – rackmount solutions tend to cost quite a bit, especially with GPU capable PCIe x16 slots and PSUs.
My advice there would be to look at a used GPU compute server. If you ask on the forums someone can probably find you a great deal on one https://forums.servethehome.com/index.php?forums/diy-server-and-workstation-builds.12/
Hi,
I’m going to start deep learning in NLP Filed. I do not spent time and money on upgrade and I want to assemble a nice working box at first try. As I’m concerned about DL model size, so I think 1080 ti is a good choice.
On Nvidia site They offer a box with such card but with up to 32GB memory and a core i5 cpu. In other hand u assemble much more expensive cpu and ram. I cannot compare this two option. Would u plz help me on comparison.
I found that a 1080ti with 32 or 64 GB of ram will be a good choice. But, no expert has mentioned how to assemble such system with reliable main board for days of continuous computing. minimizing energy consumption while we do not have bottlenecks on cpu ram or ssd. Then, I appreciate if sb write articles about choosing cpu mb ram(latency/clock) ssd and hdd for a cheap system but reliable and best compatibility, and energy efficiency.
tnx
Beginner question: what’s the watt consumption when idle?
I have looked through a lot of machine learning builds, and I think this one is the best for my use case. Any updates on parts in the last few months? I especially like the info on SSD failure rates for used units. With RAID, the configuration is brilliant!
Comments are closed.