
Today we are going to share some data on our experiment using second hand data center SSDs in the STH environment. In 2013 we had a hypothesis: low failure rate enterprise SSDs would still be useful in servers long past when we would consider spinning hard drives useful to deploy. This hypothesis has enormous implications. If hard drives had real AFRs of 3-5% and SSDs had real failure rates of under 0.5%, SSD-based servers would be considered “reliable” well past what we would have expected in the past.
In January 2015 we published a piece titled, Buyer’s Guide to getting a used data center SSD inexpensively. Since that time, we have expanded our use of used data center SSDs significantly. We added two new colocation racks, hundreds of nodes and many more drives. In early 2015 the experiment covered 78 drives. Our current tally is now at 412 and growing due to DemoEval infrastructure needs. That is starting to provide us with a better data set and new insights on re-deploying data center SSDs. The reason we are re-deploying enterprise SSDs is simple, cost savings. By re-deploying enterprise SSDs we pay about 5x per TB but also have 5x the write endurance of hard drives. Today we present our findings thus far.
Expanded STH / DemoEval used data center SSD data set
We keep track of STH’s used SSD experience so we can provide feedback to our users in the forums. These data center SSDs are deployed in a wide variety of machines across the three data centers where we lease colocation racks. This is not a huge data set by any means. It is more representative of what a thrifty enterprise or a cash strapped start-up may experience versus a hyper-scale deployment. Given that caveat, we wanted to at least present the data we have thus far.
Defining the Population
STH is unique in that it is not a typical enterprise shop. With our test lab, we do get sets of dozens of SSDs to test on a regular basis. Instead of utilizing all SSDs we have running in racks, we defined a subset we consider our “production” SSDs. These are the SSDs used to keep the various portals and applications running every day. We had a set of criteria we used to define our population:
Criterion 1: Passing burn-in

In our used data center SSD buyer’s guide we mentioned the importance of quickly testing SSDs before putting them into production. We did have two SSDs, SanDisk Lightning Ascend Gen II 800GB drives that failed burn-in likely due to firmware issues. We were not able to deduce what happened to the firmware on these drives. We requested SanDisk look at why these drives did not pass burn-in but do not have results. These particular drives we think were DOA.
We do recommend all hardware deployed in a remote data center gets an initial burn-in prior to its use in production. Our key lesson when purchasing used data center SSDs is that they need to be tested. This is to protect a buyer against vendor locked firmware and DOA drives as we saw with the SanDisk Lightning Ascend Gen II 800GB drives. Since those drives were never deployed, we are excluding them from our population.
Criterion 2: Epoch of collected data

Our data was tallied between late June 2014 and mid July 2016. Since we pulled data, the drives in the population have all had another 6 days of up time with zero failures. We have had 9 SSDs enter service in the interim and those SSDs were excluded from our population. We did include drives that were removed from the population due to upgrades (e.g. moving to a larger capacity.) All of the drives removed for these reasons had at least one year of running time. We did not consider those drives as “failed” since they were still operational. We just needed larger drives.
In early June 2014, we experienced a multiple disk failure in a single production Dell PowerEdge C6100 where all of the Kingston E100 SSDs (SandForce based SSDs with 50% over provisioning) in the chassis failed simultaneously. Other hard drives and Intel SSDs were OK in that chassis but every node saw its cluster storage disk fail simultaneously. These Kingston drives were excluded from our population because we were not keeping sufficient data resolution at that time. That single event had more SSD failures associated with it than we have seen cumulatively across the data set since then. It also helped form this experiment.
Criterion 3: Production Applications
We are only counting drives in what we would consider “production” machines. These are machines where we expect them to achieve a high-level of up time because they are web hosting nodes, data collection nodes, dashboards, hypervisors running applications, VDI hosts and gateways, networking nodes or etc.
As a result of this, SSDs that are solely used on the testing side or for DemoEval’s user demo machines are excluded. We sometimes test pre-production drives and firmware and we have seen failures. Since one cannot buy these drives with the firmware/ hardware combinations we test, we are excluding them from our data set. We also have dozens of drives that spend a few months in the lab for testing before being returned. As a result, we are excluding those drives from our “systems under test” data set as they are not used in production.
Acquisition and Deployment Information
Our acquisition of these drives came from three primary sources: IT recycling firms, ebay and user-to-user purchases. Common ebay sellers are IT recycling shops who specialize in parting out used enterprise gear. We purchased less than 1% of our production SSD population as “new” drives from retail sources. We did have several drives that were purchased second-hand but had zero power on hours logged.
In terms of the servers these SSDs are installed in, we have a number of server brands represented (alphabetically):
- ASUS
- Dell
- Gigabyte
- HP/ HPE
- Intel
- Lenovo
- Supermicro
- “Whitebox” custom servers
This is a fairly good mix of machines in terms of what we use in production. The oldest machines by Intel processor generation are:
- Intel Xeon E5: V1 (Sandy Bridge)
- Intel Xeon E3: V3 (Haswell)
- Intel Xeon D: (Broadwell DE)
- Intel Atom: C2000 series
It is not uncommon for our servers and SSDs to have different manufacturing dates. For example, we may have a 2012 server with a SSD manufactured in 2016 or a 2015 server with a SSD manufactured in 2012. As one will see with our experience, we now are more concerned with fan failures than we are with drive failures.
Demographic Overview
The SSDs we are using come from nine vendors and span some 52 different models. Here is a view of the drives in our population by vendor:

Since failures have become so rare, we are now using drive days not hours to track failures. In terms of total drive days by vendor, here is what our picture looks like:
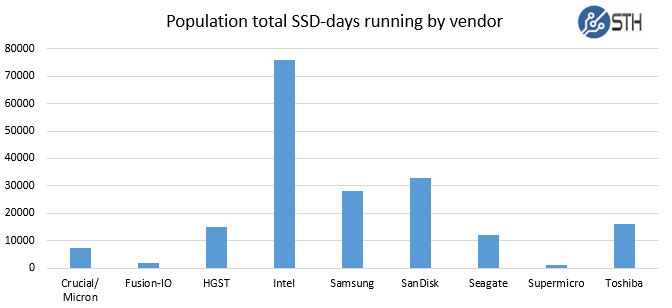
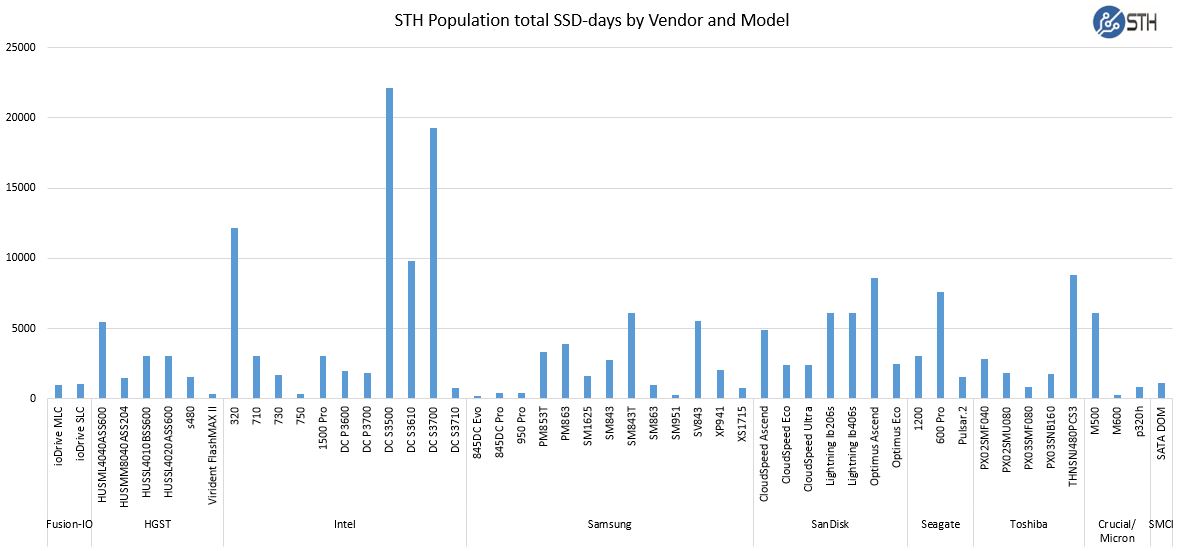
We had a total of 52 different SSD models represented in the population. Total number of drives by model (click to expand):
We are increasingly using more PCIe/ NVMe SSDs however the primary interface of the drives is SATA II or SATA III. Here are the drives by interfaces:
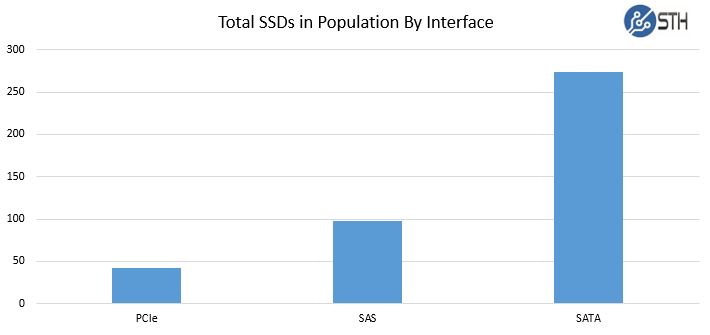
As one can see, we primarily utilize SATA SSDs. This is simply because many of our servers are low disk count and utilize onboard SATA ports. We also exclusively utilize SSDs as boot devices and we use onboard SATA controllers for boot devices.
Drives by capacity:
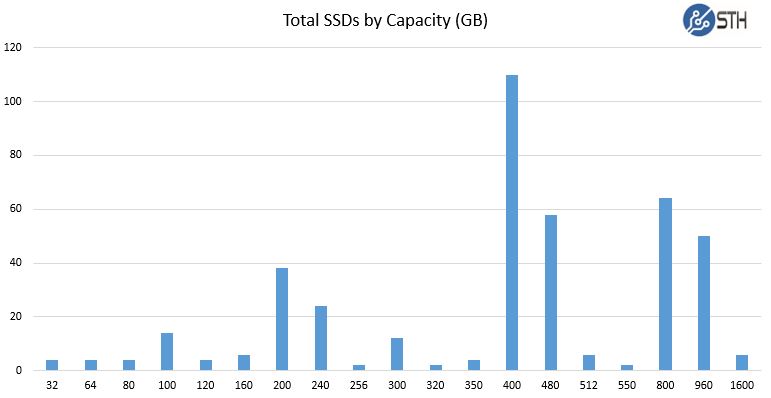
We do utilize a number of different drives to prevent failures like we had with the E100 drives mentioned earlier. We are not currently mixing drive models in our ZFS mirrors although we do have (very) heterogeneous all flash Ceph storage deployed.
To say we have a mix of SSDs is an understatement. There are a total of 66 different model/ capacity combinations out of 412 drives.
Original Condition
We also wanted to show some demographic information about how these drives were received. One of the more fascinating discoveries we have had in the process is just how many drives still have data on them. In January 2015 when we took a tally we found 38% of the 78 drives still had accessible data on them. In our expanded data set today, we found 121 drives with data still accessible, or over 29% of the drives we purchased.
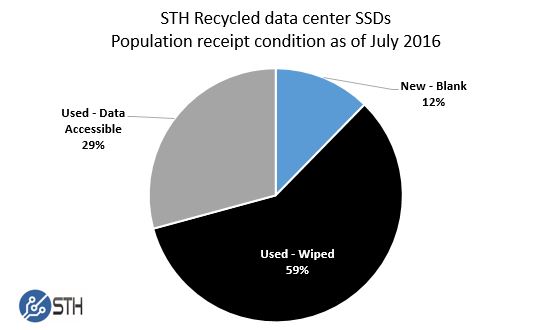
Granted, the “locking’ of drives preventing secure erasure can be annoying in a server environment but using secure erase on a SSD is significantly faster than securely erasing hard drives. When hard drives are pulled, they are often destroyed. With SSDs, secure erase functions should make them easier to re-deploy. It is amazing that we continue to see a large number of drives with data still intact given the advancement in erasing SSD media.
Key takeaway: For sellers in this space, whether they are IT recyclers or private parties: secure erase your SSDs!
Real World Write Figures
Given the acquisition of our data set, we did not have data on the deployments these drives were in before we purchased them. Also some SSDs, e.g. the Dell OEM drives we purchased, do not report standard SMART data on the amount of data written or power on hours. For those drives that were used before we purchased them and we could access TB written (TBW) information for (234 of our 412 drives), we saw generally low writes to the drives:
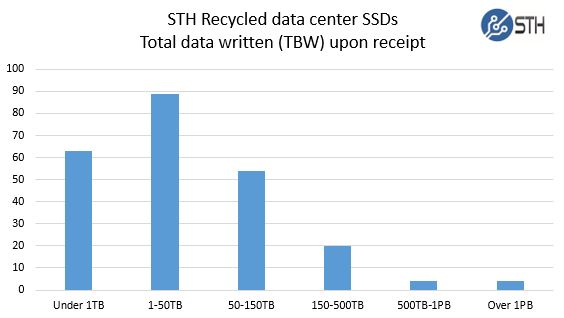
Constant 4K endurance ratings are often used for enterprise SSDs but they are a worst case scenario. Most workloads have a mix of write sizes and read heavy applications are common. Overall usage of these drives was extremely low. We did find two Samsung SV843 960GB drives each with over 1 PBW. We also had two Fusion-IO drives reach over 1 PBW. 88% of the drives we purchased second-hand had under 150TBW.
The above chart does clearly demonstrate one trend: actual write workloads are less than one may expect given spec sheets, sales representatives and many professional reviews.
Perhaps more informatively, we took this data and mapped it against drive write per day endurance ratings, usually measured in 5 year periods for enterprise SSDs. Of our 234 drive subset, here is the DWPD distribution. Note, we put all drives with greater than 1 DWPD rated endurance (5 years) in one category. This includes drives with 10 DWPD or more endurance.

When we converted our actual TBW to actual DWPD for the 234 drive subset we saw that the majority of drives we had in the population we below 0.1 DWPD. In use cases such as OS disks where a 400GB SSD is holding 200GB or less of OS data, the actual data written will be low. Similarly if one were using SSDs to hold video to be streamed, files to be written once and read often, or the like, the odds of writing large volumes of data consistently is very low. Finally, DWPD figures are based on 365 days per year whereas some enterprise IT applications see very low usage during weekends.

Although these drives were from different installations and running different applications, the takeaway is clear: the vast majority of SSDs have rated write workloads well beyond what anyone is actually writing to them. This confirms a general industry acknowledgement that actual writes to drives are much lower than one may believe by reading spec sheets. SSDs already outpace hard drives several fold in terms of rated write endurance. Before you purchase a high-endurance SSD, you should make sure your application is actually going to write that much data. One does not need a 7+ DWPD 400GB SSD as a ZIL/ SLOG device in front of a normal usage SharePoint data store/ file server that is only 20TB in size. Likewise, just because one is expecting a “database” workload does not mean one necessarily needs enormous write endurance. For truly write intensive workloads high endurance makes sense. There are many workloads that are write infrequently and read often in nature where lower endurance drives may be cost effective.
Key takeaway: You are likely putting too much emphasis on write endurance and write performance in evaluating storage needs.
Operating Reliability
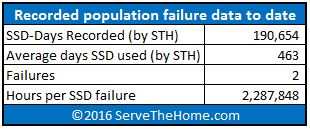
After over 4.5 million hours recorded on our drives, we have seen two failures. Most of our workloads are more read intensive so we are not in danger of hitting write endurance walls on our SSDs. Given most SSDs carry a 1.5 to 2 million hour MTBF our experience is in-line with expectations. Furthermore, given our method of acquisition, we likely are not seeing the effects of the “infant mortality” portion of a bathtub reliability curve since the original installation would have suffered the initial failures and replaced before being recycled.
The failures were very interesting. With our SanDisk failure, the drive simply stopped responding. It did show up on the SAS controller however we could not access it via OS.

The Samsung SM1625 failure was much more troublesome. The server it was in would not boot with the drive attached. Removing the drive sled from the chassis immediately allowed the server to boot as normal. If you have a high number of servers and an architecture intended for servers to fail at some point, this is not an issue. With a small number of servers (1-2) this would be a much larger concern.
Hard drives are relegated to backup and low-end file server duties in our architecture so we simply do not have that many in service at this point. We plan for a 3-5% AFR on hard drives which seems in-line with publicly available data from sources such as Backblaze and what we have been seeing in our small population. On the SSD side, we plan for an AFR of one tenth that amount.
Key takeaway: Enterprise SSDs are very reliable. Plan for 1/10th the failures you are accustomed to with hard drives.
Final Words
SSD reliability has come a long way. Years ago, it seemed as though SSD firmware was less mature and that lead to SSD failures. Today, we are benefiting from significantly better reliability than we have seen in the past. For buyers of SSDs we have a few thoughts we wanted to highlight:
- You may want to keep an eye on existing HDD/ SSD installations and how much data is actually being written before making purchases. Right-sizing SSD write endurance can easily save 50% or more on a flash purchase.
- How does SSD reliability change your perspective on server service? Hard drives were the top failure component in many servers for years. If you have a 24-bay 2U server filled with 2.5″ hard drives that fail at a 3-5% per year service contracts are going to be used often. If that AFR is one tenth the amount, how does that change what you are willing to pay for and need in terms of service? Intel, for example, advertises a 0.2% AFR on its data center SSDs which is much lower than observed hard drive failure rates.
- If you are going to remove a SSD and sell it to a third party, please secure erase the drive.
- We are seeing Silicon Valley start-ups extend the useful lives of servers using SSDs (new and recycled) in order to severely undercut AWS pricing (60-80% after administration, setup and colocation costs are included.)
- This should not be used to judge the reliability of any particular model. We are simply providing our data to show how our sample basket of recycled data center SSDs is failing over time.
The STH forums is the best place on the Internet for finding used enterprise SSDs. Our Great Deals section is full of users contributing used enterprise SSD deals they find. We do actively curate the Great Deals section to ensure that recycled IT vendors are not posting their own wares. After years of experience, the STH forums community is very sharp at spotting good deals and potential pitfalls. If you are short on time and want to get started, that is the go-to place on the Internet for finding recycled SSDs to run your own experiments. We are creating a thread there to discuss this article. Feel free to drop-in and share your experiences here.



{kind=link}
“We are seeing Silicon Valley start-ups … undercut AWS pricing (60-80% after administration, setup and colocation costs are included.)” Can you provide more details on AWS savings in start-ups?
Comments are closed.