
Ever since the AMD EPYC launched we have gotten a barrage of questions on the architecture. Many of these questions come in the form of “so and so YouTube vlogger/ gaming website said EPYC is all one chip and STH is wrong,” or “AMD EPYC is always better than Intel’s architecture,” and conversely “Intel Xeon E5-2600 V4’s will always smoke AMD EPYC.” All of those statements are patently false. There are four NUMA nodes and pieces of silicon on each EPYC package. They are tied together with Infinity Fabric. This makes total sense based on what we have seen in the lab.
To help our readers understanding the new AMD EPYC Infinity Fabric architecture versus the Broadwell-EP generation, and by extension, the rest of the Intel Xeon E5-2600 V1-V4 generations, we put together a quick video showing differences in design philosophies.
Some Background on Where and Why
STH was perhaps the first 3rd party independent site to have AMD EPYC hardware in the data center. At STH, we keep dozens of Intel Xeon CPUs online in the data center just to be able to run performance regressions with new benchmarks on older chips for clients. While we are still awaiting some of our performance data to settle (e.g. with new firmware that came in over the past few days) we feel confident saying AMD has some great use cases. At the same time, there are plenty of use cases where the Intel Xeon E5-2600 V4 generation performs well.
In Q3 2017 we will, for the first time in 5+ years, have competition in the server market again. Accordingly, there are now more considerations to purchasing decisions than simply buying the next generation of Intel Xeon E5-2620 V3 to E5-2620 V4 or buying more cores/ higher clocks. For the first time in years, we have a legitimate, competitive x86 architecture. As an IT and technology industry, those purchasing new gear do need to add another domain of knowledge to address these new developments.
At launch, AMD provided this slide showing dual socket Infinity Fabric. We wanted to add a bit more information beyond what this view shows and also help our readers compare to Intel.
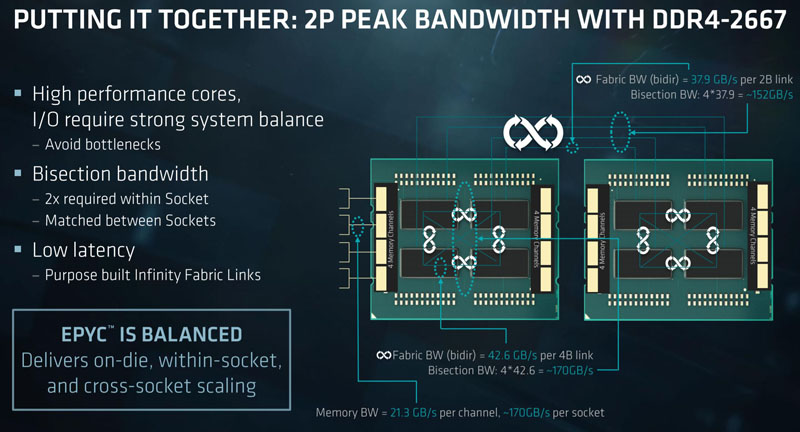
Although this is a great graphic, AMD is actually doing a lot more with Infinity Fabric than one may see at first glance.
AMD EPYC Infinity Fabric v. Intel Broadwell-EP QPI and NUMA Nodes
To understand why the AMD Infinity Fabric design both makes sense for AMD’s business model and why Intel Broadwell-EP is different here is the video we made:
Although at STH we are primarily creating content that is easy to read without speakers and in planes (I am typing this from the Lufthansa Lounge en route to San Francisco from Munich), this discussion requires a video.
In the video we show why the eight NUMA nodes in a dual socket AMD EPYC Infinity Fabric is a complex engineering marvel. We also show why a dual socket AMD EPYC platform is going to rely on the Infinity Fabric to a much higher degree than Intel’s QPI will be used in a dual socket system.
After watching, you should understand why comparing QPI speed and bandwidth v. Infinity Fabric speed and bandwidth is not an apples-to-apples comparison. In the Intel design, ~50% of resources can sit on the other side of the link while with AMD ~87.5% of system resources will be across one or two Infinity Fabric hops.
Final Words
With Skylake-SP launching, we will have an update comparing the next-gen Intel architecture to what AMD has as there are some differences. Expect more data in our upcoming pieces for the new Intel Xeon Platinum, Gold, Silver and Bronze family. We are also working on characterizing the performance of AMD EPYC v. Intel Xeon E5 and Platinum, Gold, Silver, and Bronze to help our readers understand which is better. As the different firmware and kernel versions change, we are seeing some drastic swings in performance. Once the dust settles, we will have more.
For those wondering, we do not see AMD EPYC competing against Intel Broadwell-EP (Xeon E5-2600 V4.) General availability of systems from major vendors such as Dell EMC, HPE, and Supermciro, along with others, will likely be in mid-Q3 2017. While AMD “launched” first, in the market AMD will be shipping alongside Intel Skylake-SP. We still wanted to post this video for those who need to explain how current systems compare to AMD EPYC Infinity Fabric.



 QPI architecture and NUMA design to share with colleagues){kind=link}
I’ve been working on specing out a single socket server that can handle at least two 4k Plex transcodes at once. I understand it’s still early for benchmarks and such, hut strictly speaking between say an e5-2630v4 and an EPYC 7301 or 7351, would the epyc better handle multi threaded apps? Based on the architecture and core count it would seem so, but I haven’t had a chance to see what epyc can do yet. Thanks!
In initial testing, you are right on the EPYC performance side.
And here is EPYCs only “supposed” Achilles heal – Latency
From the Anandtech testing of Epyc 7601 ($4200) and Intel 8176 ($8700):
blk size 8176 latency (ns) 7601 latency (ns) delta (ns)
0.5KB 4 5 1
1KB 9 10 1
2KB 17 11 -6
4KB 20 11 -9
8KB 23 33 10
16KB 26 62 36
32KB 40 102 62
64KB 75 107 32
AMD claims 250GB/s Memory BW. From the Anandtech testing of Epyc 7601 ($4200) and Intel 8176 ($8700), 7601 w/ 2400MHz RAM showed 207GB/s, so 2666MHz RAM would achieve 230GB/s.The one good BW out of three test methods for 8176 was 165GB/s w/ 2666MHz RAM.
If using all of EPYC 7601’s 230GB/s Memory BW (w/2666MHz RAM):
64KB transfer takes 278ns + 107ns = 385ns
32KB transfer takes 139ns + 102ns = 241ns
16KB transfer takes 70ns + 62ns = 132ns
8KB transfer takes 35ns + 33ns = 68ns
4KB transfer takes 17.5ns + 11ns = 28.5ns
If using all of 8176 165GB/s Memory BW (w/2666MHz RAM):
64KB transfer takes 388ns + 75ns = 463ns
32KB transfer takes 189ns + 40ns = 229ns
16KB transfer takes 90ns + 26ns = 116ns
8KB transfer takes 45ns + 23ns = 67ns
4KB transfer takes 22.5ns + 20ns = 42.5ns
64KB transfer Epyc 20% faster
32KB transfer Epyc 5.2% slower
16KB transfer Epyc 13.7% slower
8KB transfer Epyc 1.4% slower
4KB transfer Epyc 49% faster
Latency Shmatency, no big deal.
For large data and 64KB block sizes, Epyc wins
For small data and 4KB and 2KB block sizes. Epyc wins
For 1KB and 0.5KB block sizes it is essentially a tie.
Intel will try to manipulate benchmarks to use 16KB block sizes
This site looks like Intel Paid. Good luck :)
Hi anakonda – we do not accept direct advertising dollars from any vendor (unlike most large tech sites.)
We also offer a full and constantly updated conflicts list along with our editorial policy and are the only major technology site to make such disclosures.
Suffice to say, we do not do paid content and have no direct ad sales to Intel.
Why is my comment still awaiting moderation days after other comments were posted?
Comments are closed.