
Over the past few months, we have seen a surge of interest in our two “large” deep learning systems. Here is an overview of the 8x NVIDIA GeForce GTX 1080 Ti system we called DeepLearning10. For DeepLearning11 we have a 10x NVIDIA GeForce GTX 1080 Ti system. Aside from the raw number of GPUs, another key difference is the PCIe architecture. DeepLearning10 is a dual root system while DeepLearning11 is a single root variant. We are going to show a bit about what that means and show example data of why that matters in this piece.
DeepLearning10 Test Configuration
DeepLearning10 is our dual root test bed configured as such in our lab:
- System: Supermicro SYS-4028GR-TR
- RAM: 16x 16GB DDR4-2400 RDIMMs
- CPUs: 2x Intel Xeon E5-2690 V3
- SSDs: 2x Intel DC S3710 400GB
- GPUs: 8x NVIDIA GTX 1080 Ti 11GB Founders Edition
- Networking: 1x Mellanox ConnectX-3 Pro
- Ubuntu 16.04.2 LTS server with CUDA Version 8

If we were building the system today we would use Xeon E5 V4 CPUs but these still utilized a 9.6GT/s QPI. In dual root systems, you want the highest QPI speed you can get. Today, that means you want UPI on the new Skylake-SP Xeon Scalable family. While we expect the new Skylake systems to be better in this regard, we do not have an 8x or 10x GPU Skylake server in the data center yet. This configuration will still show data across the PCIe switches in a normal light and will be comparable to mid-range E5 V4 chips with the same QPI speeds.
DeepLearning11 Test Configuration
Here is the DeepLearning11 configuration:
- System: Supermicro SYS-4028GR-TR2
- RAM: 16x 16GB DDR4-2400 RDIMMs
- CPUs: 2x Intel Xeon E5-2628L V4
- SSDs: 2x Intel DC S3710 400GB
- GPUs: 10x NVIDIA GTX 1080 Ti 11GB Founders Edition
- Networking: 1x Mellanox ConnectX-3 Pro
- Ubuntu 16.04.2 LTS server with CUDA Version 8

The -TR2 in the test system means that it is the single root version. We use many of the Intel Xeon E5-2628L V4’s in the lab because they are great low power SKUs. They only have an 8.0GT/s QPI link, however, that is less of a concern in the single root system. One of the advantages of the single-root architecture is being able to use a lower QPI/ UPI speed and a lower-end CPU SKU. The power savings we see with the low power chips essentially pay for a 1080 Ti over 3 years.
Single v. Dual Root Topology
As you can see, in the typical dual-root setup half of the GPUs are on one CPU, the other half are attached to the second CPU. In these systems that is important because it also means that Infiniband placement may be across one or two PCIe switches and across a socket-to-socket QPI link. To mitigate this impact, we have seen deep learning cluster deployments with two Infiniband cards, one attached to each CPU.
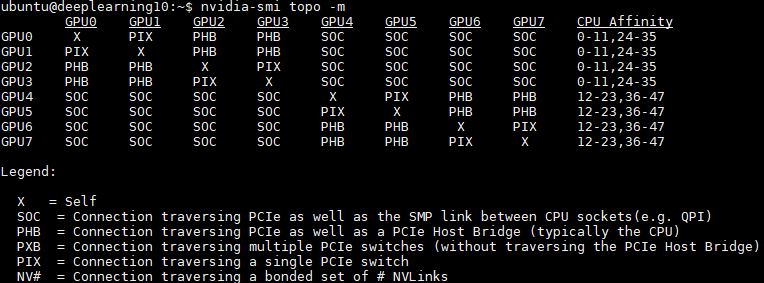
We actually illustrated this via a picture using the SLI covers. Red and Black SLI covers are on different CPUs. In the topology above that means that they need to traverse QPI and therefore communication is marked as SOC:

For peer-to-peer connectivity, this means that GPUs 0-3 and 4-7 can do P2P.
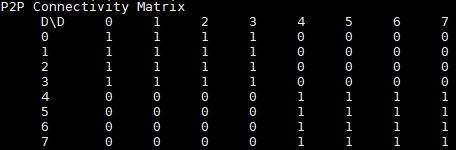
Despite this, our GPU7 showed some strange behavior. We have heard a number of theories as to why, but we have yet to get the performance to where it should be.
Single root means that each GPU is connected to the same CPU. There are generally PCIe switches to handle this. As you can see from the topology matrix, there are no “SOC” entries.
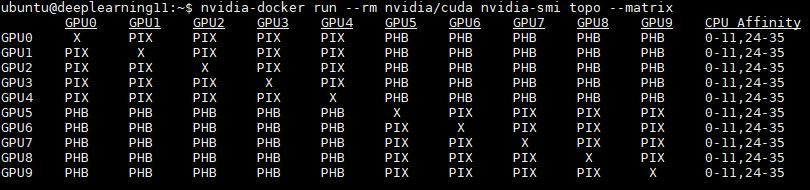
The impact here is that there are two layers of PCIe switches. This is a costly architecture, but it has some significant benefits as we will see.
Here is what that looks like using black SLI covers on our 10x NVIDIA GTX 1080 Ti Founders Edition cards:
You will notice there are no red SLI connectors on the second CPU. What that means on peer-to-peer connectivity is that we no longer have a matrix of 1’s and 0’s:

This is a popular topology for deep learning servers and we have seen several big data/ AI companies using both versions of the GPU server. We have also seen a large hyper-scale AI company use the single root version of this server with GTX 1080 Ti’s, Titan Xp’s as well as P100’s.
Let’s take a quick look at some of the benefits.
Single Root v. Dual Root Bandwidth
NVIDIA specifically says that the p2pBandwidthLatencyTool is not for performance analysis. With that said, we wanted to get some data out there simply to present a rough idea of what is happening.
Unidirectional Bandwidth
Here you can see the 8x GPU server GPU to GPU bandwidth. GPU7 is giving us some strange numbers.
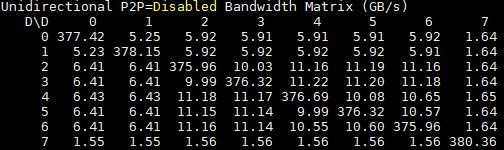
We have asked around and are still troubleshooting. We suggest ignoring GPU7 for these charts as there is something going on.
Here is the single root version:
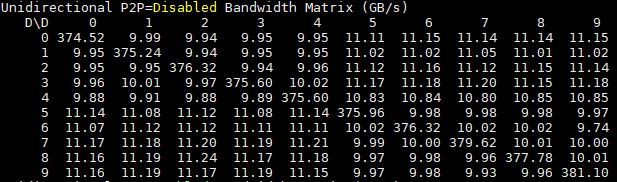
Aside from using more GPUs, you will notice that by not having to traverse the QPI bus, there is around a 2x GPU to GPU speed improvement.
Turning to P2P enabled here is the 8x GPU dual root system:
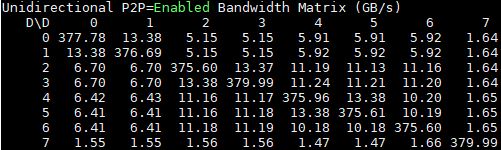
Now let’s take a look at the 10x GPU single-root version:
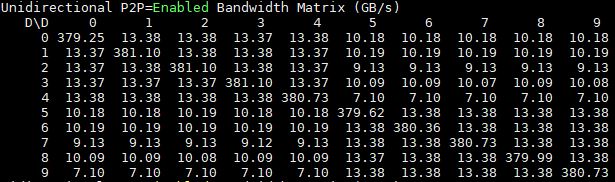
You can see the impact of using multiple PCIe switches tiered but the bandwidth gains cannot be ignored.
Bi-directional Bandwidth
What happens when we move to bi-directional bandwidth? Here is the 8x GPU dual root system (again see the note above about GPU7):
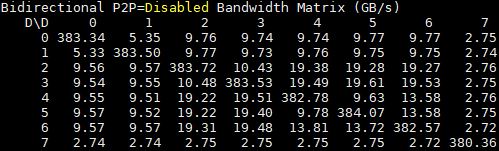
Here is the 10 GPU system for comparison:
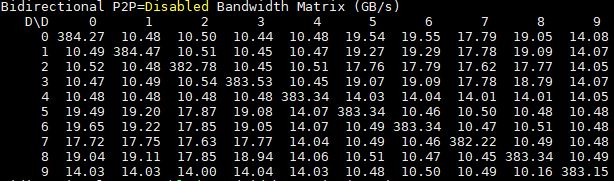
When we turn on P2P we see some gains on the dual root 8x GPU system:
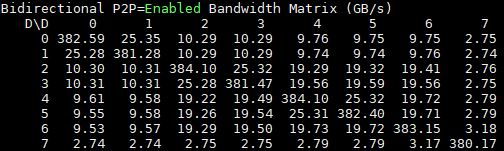
We also see more substantial gains on the single root 10x GPU system:
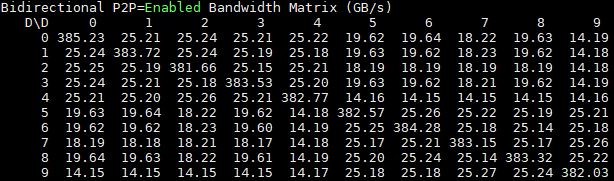
The key here is that the biggest gains are happening for GPUs on the same switch complex.
Single Root v. Dual Root Latency
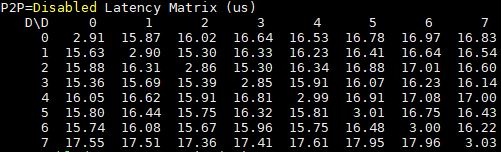
When it comes to latency, here are the P2P disabled 8x GPU results:
Here are the signle-root 10x GPU results. Note that even with more GPUs on the PCIe switches, the performance is still good.
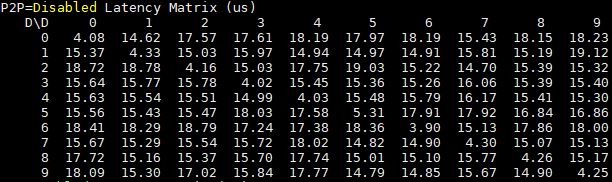
P2P makes a significant latency impact on the dual root system, for GPUs on the same CPU/ PCIe root.
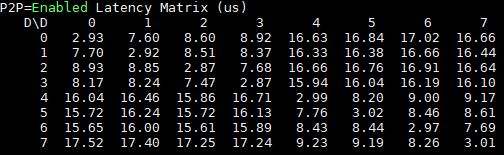
When you flip to P2P with the 10x GPU system, you will notice a fairly dramatic latency drop from the above.
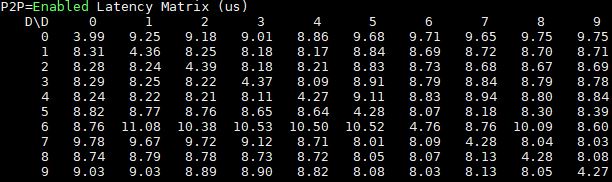
That contrast above is one of the key drivers towards single root PCIe systems.
Final Words
While these may not be the only advantages, we simply wanted to show some context around single-root versus dual-root PCIe complexes. There are two key takeaways from this.
First, PCIe switches do add some latency, however, as you can see there are advantages to using more PCIe switches versus having to traverse QPI/ UPI. If you want to see why we are tempered in excitement around EPYC’s architecture, the above shows why. Remember, in most EPYC systems you will see GPUs connected to different CPUs which require Infinity Fabric hops (see our AMD EPYC Infinity Fabric latency piece here.) Either way, many of today’s deep learning applications are being developed on single root systems for some of the reasons shown above.
Second, moving to a single root PCIe complex also means that one does not need the highest-speed interconnect between CPUs. One may want this for additional memory, however as one can see the latency is decoupled from socket-to-socket interconnect performance. While PCIe switches may cost more, one can also spend less on the CPU(s) utilized in single-root systems.
For those wondering why we did not use Vega RX, Intel Xeon Scalable, nor AMD EPYC, first off they were not available when we were working on the above. Second, NVIDIA CUDA has a lot of tooling readily available. That is something that we do not have on the AMD Radeon side, although I did tell Raja Koduri at the Ryzen event this year I was willing to contribute funds via a Kickstarter campaign to an amd-docker equivalent of nvidia-docker. Alas, the GTX 1080 Ti is this generation’s killer value GPU for today’s deep learning shops.
Over the next few weeks and quarters, we are likely going to have additional systems to show GPU results from, including a single root, single CPU Intel Xeon Scalable system as well as AMD EPYC systems. This is certainly an exciting time in the world of servers!



{kind=link}
It’s interesting measuring things like latency and bandwidth, but that doesn’t really prove one is better than the other. You need to run a real workload on both servers and see which one is faster. That’s the ultimate proof of the pudding.
Ed – 100% correct. We get a lot of questions on what is single root v. dual root? Why would you ever want single root? and similar.
It is also industry/ workload specific. Many of the oil & gas guys like dual root for their workloads. A big hyper-scale AI shop we work with regularly prefers single root for their deep learning.
What does STH use Deep Learning for?
I’m confused as to why most Epyc systems are expected to be dual socket. It seems to me that it explicitly lend itself to being a single socket. Using a single processor would lower power consumption (similar to your using the 2628L) and provide the same amount of PCIe bandwidth to a dual socket system. I admit I have zero experience in machine learning systems but from an outsiders perspective it would seem like a pretty stupid move to choose a dual socket Epyc with higher upfront cost, higher operating cost and the potential for the inter-process communication to slow things down over a single socket system.
Perhaps on the GPU side. From the big OEMs we are hearing single socket EPYC, especially as a storage server is a big deal.
Dave, we actually run demos for silicon valley startups on our hardware as part of DemoEval program.
We do have a project that we are using it for, you have probably already seen it in use. We are not discussing it at this time.
I have seen it in use?
“I was willing to contribute funds via a Kickstarter campaign to an amd-docker equivalent of nvidia-docker” Nice! So what did Koduri say about that idea?
We do not have a Kickstarter campaign to date :-/
10 GPU and GTX in servers aren’t supported by NVIDIA. You can’t do this!
Glad to see it works.
3.2.6.4. Peer-to-Peer Memory Access
…
Peer-to-peer memory access must be enabled between two devices by calling cudaDeviceEnablePeerAccess() as illustrated in the following code sample. Each device can support a system-wide maximum of eight peer connections.
How did you get P2P working on 10x GPU?
Is not this motherboard wired as 8 PCIe3x16 + 2 PCIe3x8 (in x16)?? The GPUs require PCIe3x16, what happen with these 2 GPUs? How they are powered up? There are 8 power pci ports on the motherboard.
Thanks!
jota83 – the SYS-4028GR-TR is 8 PCIe x16, 2 PCIe x8 in x16, and 1 PCIe x4 in x16. The SYS-4028GR-TR2 has 11x PCIe x16 and 1x PCIe x8 in x16. That is why we see more 10x GPU installations in the -TR2.
All GPUs are powered via cables that come from the motherboard PCB just behind some of the PSUs. You can see this in our system reviews.
@Patrick Kennedy,
> To mitigate this impact, we have seen deep learning cluster deployments with two Infiniband cards, one attached to each CPU.
Do you mean GPUDirect-RDMA (p2p GPU through Infiniband) actually works on GTX too?
Or, at least the GPUDirect (without RDMA, as defined in http://on-demand.gputechconf.com/supercomputing/2013/presentation/SC3139-Optimized-MPI-Communication-GPUDirect-RDMA.pdf ).
That’s interesting, cause there’s not much info about this, only Tesla/Quadro are officially supported ( https://devtalk.nvidia.com/default/topic/996772/gpudirect-rdma-with-geforce-gtx-10xx-/ ) and some people say “The only form of GPU-Direct which is supported on the GeForce cards is GPU Direct Peer-to-Peer (P2P). This allows for fast transfers within a single computer, but does nothing for applications which run across multiple servers/compute nodes.” ( https://www.microway.com/knowledge-center-articles/comparison-of-nvidia-geforce-gpus-and-nvidia-tesla-gpus/ )
@i3v:
GPUDirect-RDMA does not work on GTX cards, the traffic has to pass the CPU.
Comments are closed.