
We finally have our Supermicro 2U Ultra server with what seems like it may be a production firmware. Over the past two weeks, we have upgraded the system to a new motherboard PCB revision, cycled through several BIOS versions, and upgraded to DDR4-2666. Our reviews live for many quarters so we wanted to ensure that if we are publishing numbers on something that one can actually buy. Now, we are ready to publish some numbers based on AMD Infinity Fabric and have a quick comparison point against the Intel UPI interconnect as well.
Some Background on Intel MLC
The Intel Memory Latency Checker tool has had several revisions and one of the main purposes is to show memory latency and bandwidth between different CPUs in a system. For example, Intel has, for years used different QPI speeds throughout its range that impacts socket to socket communication speed. MLC is one of those tools that has pushed companies to use slightly higher-end CPUs even in high-end 8x and 10x GPU systems as we described in DeepLearning10 and DeepLearning11 pieces.
We are using Intel’s MLC to provide the figures below as an initial data set. While one may immediately cry afoul with this, Intel essentially had no opportunity to fudge the program for AMD EPYC. We asked Intel about if they had tried MLC on AMD EPYC and as of the time we ran these benchmarks the company confirmed they did not yet have access to an EPYC system. That makes sense since AMD EPYC is still not shipping in retail available systems as of a month after its launch. What that also means is that Intel’s developers were not on an AMD EPYC system prior to these benchmarks. Without access to AMD EPYC systems, Intel could not reasonably tune or detune for AMD’s reliance upon NUMA as the NUMA enumeration looks slightly different on AMD v. Intel architectures.
We still took the figures with a bit of skepticism. We looked at the results we obtained and compared them against what we know of the architecture. Further, we shared them with a handful of industry analysts who are technically excellent and the general gut check is that they make sense. That gave us the confidence to publish these numbers.
We are also publishing figures for both DDR4-2400 and DDR4-2666 operating modes. The AMD Infinity Fabric is tied to the memory clock domains. If you want to see an example of how the firmware evolution and the change to DDR4-2666 has real-world implications, here is our Linux Kernel Compile Benchmark using the initial pre-production AMD AGESA firmware we received, and production AMD AGESA at DDR4-2400 and DDR4-2666.
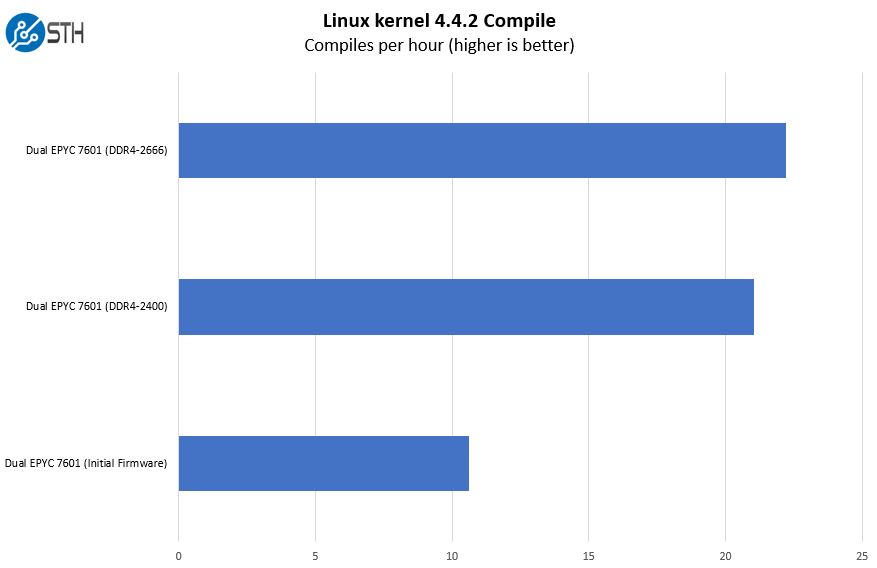
That picture above is a prime example of why we have held off on publishing full benchmark result sets to date. Expect more coming. Infinity Fabric plays such an enormous role in AMD EPYC performance that we wanted to show real-world performance. If you are buying a new AMD EPYC server, we highly suggest using DDR4-2666 over DDR4-2400. We expect very few AMD EPYC dual socket buyers to opt for DDR4-2400 anyway now that DDR4-2666 is shipping.
Test Configuration
Not to belabor the background information, but here is the test platform we are using:
- System: Supermicro 2U Ultra EPYC Server (AS-2023US)
- CPUs: 2x AMD EPYC 7601 32-core/ 64-thread CPUs
- RAM: 256GB (16x16GB DDR4-2400 or 16x16GB DDR4-2666)
- OS SSD: Intel DC S3710 400GB
- OS: Ubuntu 17.04 “Zesty” Server 64-bit
- NIC: Mellanox ConnectX-3 Pro 40GbE

We are going to have more on the server and performance at a later date.
AMD EPYC Infinity Fabric DDR4 2400 v. 2666
We are going to bound this discussion in terms of two MLC outputs. First core to core latency as well as bandwidth. We ran the tests on the system with DDR4-2400 and DDR4-2666 RAM to make a direct comparison. Since the AMD EPYC dual socket system has 8 NUMA nodes, we also have summary tables so you can easily parse the large data set. There is a ton of misinformation going around, so we wanted to simply present some data.
We did ten runs on each and the results were extremely consistent. We used the final runs (generally in the middle of a +/- 1 or 2 ns variance for each NUMA node to NUMA node figure) to showcase the configurations. MLC produced very consistent results.
AMD EPYC Infinity Fabric DDR4 2400 v. 2666 Latency
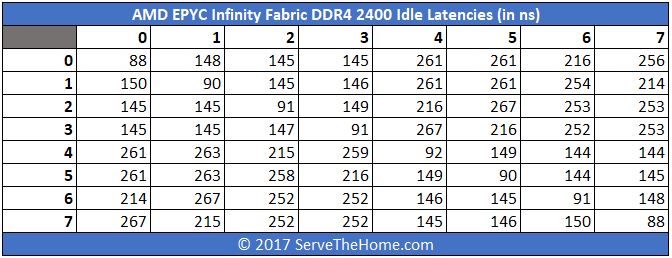
Here is a quick view of what AMD EPYC Infinity Fabric latency looks like across different cores using DDR4-2400. For these charts the 0-7 on the horizontal and vertical headers correspond to NUMA nodes.
Here is the same system with DDR4-2666 DRAM:
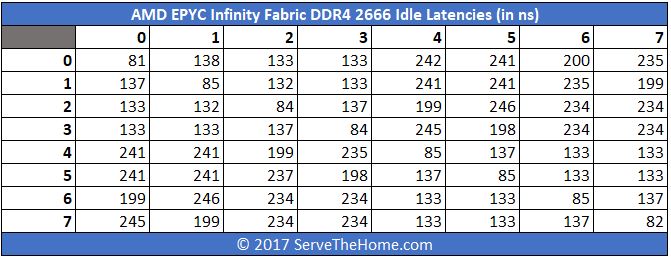
You can see that there is an appreciable drop in overall latency. Instead of trying to calculate each drop on an absolute basis, here is a table with the differences:
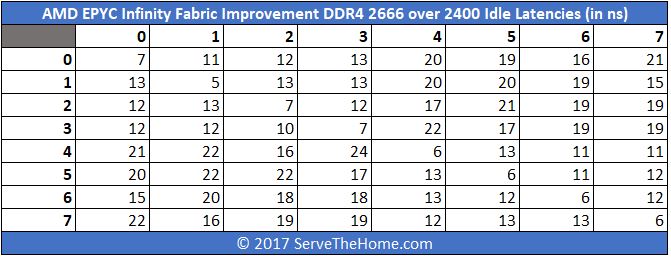
If you want to see those figures on a percentage basis, here is the view:

The overall average is about an 8% lower latency using the faster RAM. In an 8 NUMA node design, that is a big deal.
The extremely cool finding here is that we saw a clear pattern that one may have hypothesized. AMD EPYC socket-to-socket communication is done via four Infinity Fabric links that we were told connect each die to its respective die on the other package. So Socket 0 Die 0 has a direct link to Socket 1 Die 0 which is a single hop trip. Conversely, if Socket 0 Die 0 wants to communicate with resources from Socket 1 Die 3, we expect this is a two hop trip. Here is a diagram where Yellow is Socket 0 Die 0 and Blue is Socket 1 Die 0 for reference.
That is exactly what Intel MLC is showing us, to an extent. We highlighted four sets of figures corresponding to the same die results, the same package results, other package/ socket, and other package/ socket with the corresponding die. Taking that view, we saw a clear pattern:
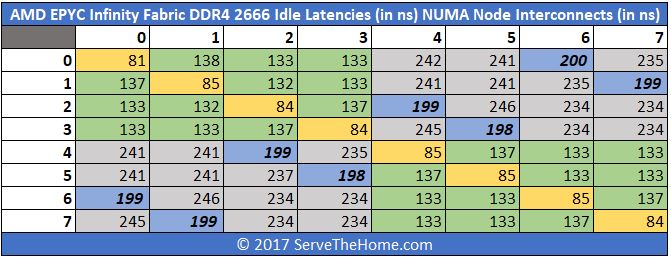
Now, one will note that the bold and italicized results do not line up perfectly. E.g. we would expect one to fall at the intersection of NUMA 0 and 4, 1 and 5 and etc. Although we do not have a great answer for this, we do know AMD EPYC NUMA enumeration is slightly different. One extremely simple answer for this is that Intel did/ does not have a test system to check the enumeration is the same. Still, we are seeing a clear delta between those four latency domains as we discussed in our AMD EPYC and Intel Xeon Scalable Architecture Ultimate Deep Dive and our launch AMD EPYC 7000 Series Architecture Overview for Non-CE or EE Majors piece.
AMD EPYC Infinity Fabric DDR4 2400 v. 2666 Memory Bandwidth
Latency is great, but in NUMA architectures one of the other major factors is memory bandwidth. Here we have similar data to the latency numbers, instead expressed in terms of bandwidth at DDR4-2400:
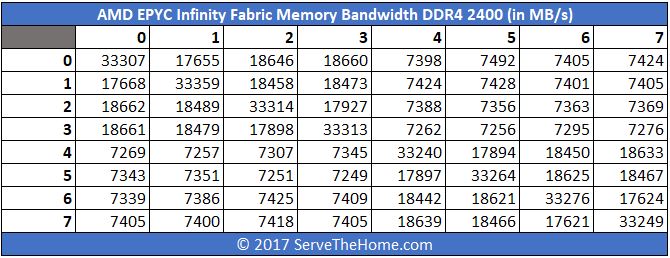
Swapping that to DDR4-2666 you will see a significant bump in bandwidth:
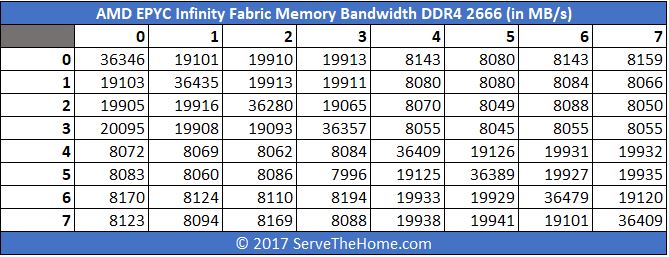
Again here is the delta chart:
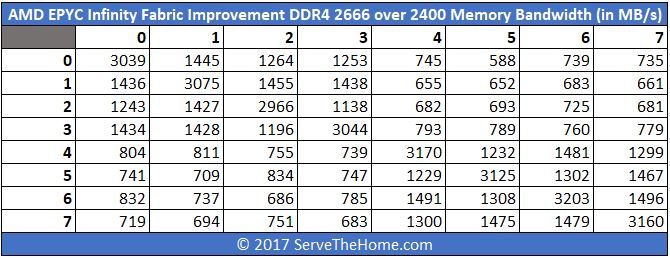
Like we did for the latency side, here is the improvement expressed as a percentage:

Again we see around 9% improvement.
We took this data and applied the same formatting from the latency measurements and the results did give us pause.
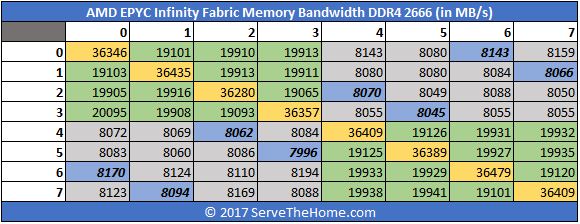
Here the inter-socket bandwidth between partners is not showing additional bandwidth versus the non-partners across sockets. The major gains are again coming across the board from DDR4-2666 over DDR4-2400.
AMD EPYC DDR4-2400 v. DDR4-2666 Quick Summary
If you cannot tell our theme thus far: do not buy an AMD EPYC system with DDR4-2400. Just get DDR4-2666. You can see from the Linux kernel compile benchmark (copied again for ease of reference) that there are tangible differences in a real-world application of around 5% that accompany the 8% latency and 9% bandwidth improvements we are seeing between the NUMA nodes.
Using DDR4-2400 on an AMD EPYC 64-core system is equivalent to running a DDR4-2666 system with only 60 cores.
We now have 50+ benchmarks run with the three firmware levels shown in that chart. We will note that smaller workloads that do not have much die-to-die traffic work about equally well on DDR4-2400 and DDR4-2666 (and even that “Initial Firmware” revision.) However, when you configure a system, the performance gained with DDR4-2666 over DDR4-2400
Since we are going to get asked the question, we did want to put some UPI perspective around these figures.
Intel Xeon Scalable 4 Socket UPI v. AMD EPYC Infinity Fabric
Since comparisons are all the rage these days, and we boldly made the statement that AMD’s on package latency looked much like Intel’s inter-socket latency (in a quad socket configuration.) To an OS, both an Intel Xeon Scalable quad socket system and a single socket AMD platform will look similar with four NUMA nodes.
Here is what a DDR4-2666 quad socket Intel Xeon Platinum 8180 platform looks like in terms of latency next to the numbers from the first socket of the AMD EPYC DDR4-2666 platform:
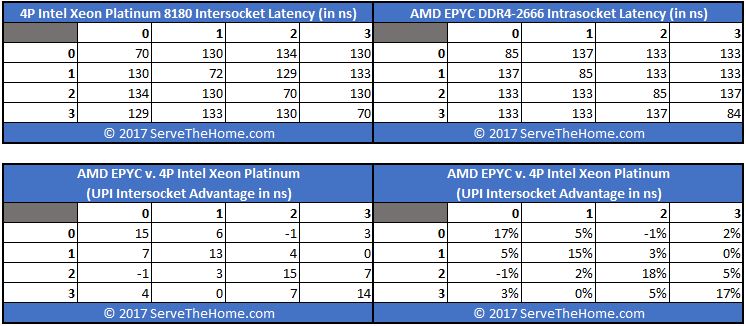
As you can see, the Intel inter-socket latency is roughly equivalent to the intra-socket latency for AMD EPYC Infinity Fabric. Intel is still doing a bit better in its most complex (with full 3x UPI link direct connection) four NUMA node topology than AMD EPYC is.
Quad socket for Intel is a decidedly tougher case than dual socket, but we wanted to show both configurations near their practical maximums. The Intel Xeon Scalable CPUs can scale to 8-socket configurations as an example, but those configurations lack direct die-to-die communication channels via UPI. Instead, we wanted to show what happens when we stress that architecture to its practical maximum.
Final Words
Overall, the proof is in the real world benchmarks. The Linux Kernel Compile Benchmark above is a great example of how Infinity Fabric speeds have significant impacts on overall performance running real application workloads. With DDR4-2400 memory speeds there are significant performance hits that are frankly not worthwhile for anyone ordering a new AMD EPYC system.
Since the above will likely incite scores of supporters from the AMD and Intel camps, feel free to review our Editorial and Copyright Policies. We are the only major publication to publish a full and regularly updated conflicts list, down to pizza companies we have indirect investments in. We are also the largest technology website that does not sell ads or sponsored content posts to either AMD or Intel. That is terrible for our revenue but allows us to remain a highly independent source. All of our display ad placement sales are through Google so nobody from our organization is ever involved. Then again, we are also decreasing display ads significantly bucking the overall industry trend to give our readers the best experience and best information possible. This is done to provide STH’s audience of IT professionals the most independent and objective coverage out there.



{kind=link}
That is some f****** great data. What brought it home for me was showing the real world result on the kernel compile. I was disappointed by the fact it isn’t 8-11% better but it prob that’s just an example of not scaling 100%. That’s real world truth tho so thanks.
TL;DR for anyone else is just buy 2667.
To summarize, latency is much bigger for Epyc. Latency for 8180 from socket 0 to socket 1 is 130ns, compared to 241 for Epyc (socket to socket).
I was surprised how bad the initial firmware was. Gives a feeling that EPYC despite being late was still quite rushed. It would be ok to have at launch firmware with some optimization potential, but the kind of improvement you saw there is kind of surprising at this stage.
Also, it would be great if you could mention if EPYC is a newer stepping revision vs. Ryzen, because Ryzen has bug(s) that may not be fixable via microcode updates. At least that is what people are saying after AGESA 1.0.6 was released with no improvement.
Good Article. Incidentally using the DDR4-2666 and the newest firmware the compile speeds on the Epyc appear to be similar to the initial benchmarks for a 2-socket 8176 that you published on launch day and a step behind the 8180.
https://www.servethehome.com/quad-intel-xeon-platinum-8176-initial-benchmarks/
That’s massively different than the published results from a certain website starting with “A” that got a bunch of press attention but did not seem to be doing a very thorough job in running proper benchmarks.
We appreciate your attention to detail and accuracy rather than just trying to get clicks on launch day.
Don – we are going to have more Xeon Platinum, Gold, Silver and Bronze benchmarks soon. I would probably place the performance a few notches below the 8176 on this benchmark (and note I do have a spreadsheet with a lot of data behind that statement.)
This test case was particularly bad using that firmware. Others such as c-ray showed very little improvement as they used the fabric less. I did want to show why STH did not publish numbers earlier.
Again, EPYC is launched but as of publication, it is not available at retail.
Any plans to do a single socket benchmark? I ask because single socket Epyc are meant to be the more compelling products in AMD’s line out. For instance, a single socket Epyc can support more NVMe drives than a 2 socket Xeon (in theory any way).
Yes. Skylake-SP will likely be first since we can get those chips and platforms at retail.
Lots coming :-)
16x16GB DDR4-2666 is single rank?
Test also dual rank 2400.
Socket to socket Bandwidth is low. Try another MLC benchmarks that can load channels more.
Test also with NUMA switched off.
If socket to socket is so slow, test also benchmarks with single socket Epyc.
Great article, with excellent in-depth information about the new EPYC platform. Thanks a lot! The article makes a great point about DDR4-2666 for maximum performance on this particular platform architecture. I am curious about the memory speeds with all memory slots fully occupied. This technical detail is quite hard to dig out from any EPYC presentations or articles. Can you still achieve DDR4-2666 speeds with all 16 slots per processor used by RDIMM and/or 64 GB LRDIMM?
Is it correct that Skylake-SP supports DDR4-2666 memory speed with all 12 slots per processor used by 64 GB LRDIMM?
Not bad for a $ 4.200 cpu, the competing intel 8170 is $ 7.400, for me this means 256 GB for free.
I think the EPYC 7551P at $ 2.100 will be an even bigger hit .
Looking forward to the benchmarks.
Stellar presentation STH. This site is a gem.
Each chip in EPYC uses one link of 16 lanes to connect to chip in another socket.
Same link of 16 lanes can work as PCI-e 8 GT/s x16.
But EPYC must use higher transfer rate in that link when that link is used for socket-to-socket interconnect.
That transfer rate must be 10 GT/s or more for socket-to-socket link.
AMD claims that B/W for that link is 19 GB/s in each direction.
But your tests show only 8 GB/s for reading via socket-to-socket link.
Maybe another processor or link are working in some sleep mode in MLC test?
For example, could it use only 8 lanes from 16 lanes or half frequency 5 GT/s instead of 10 GT/s?
You can ask AMD: why socket-to-socket interconnect is so slow in MLC for both B/W and latency results.
@ep maybe the prefetcher is using some bandwidth? As that tool is built for Intel CPUs it can’t know how to disable Epyc’s prefetcher
Thorough analysis. Eagerly waiting for 1S benchmarks. We have a lot of 2S servers we want to upgrade, with almost half with only one CPU…
STH is amazing, providing accurate information to make good decisions.
@Ed : Prefetcher is not problem. Prefetcher can help for B/W tests.
B/W for inter-socket bandwidth is good: 20 GB/s from 21.3 GB/s of AMD claim.
B/W for socket-to-socket is bad: 8 GB/s from 19 GB/s of AMD claim.
But it could be some low power mode in another processor.
If there is sleep problem, maybe there is some optional mode in MLC that can wake up another cores in another processor with some additional load?
The high inter-socket latency in EPYC explains the low socket-to-socket bandwdith. I guess this is related to the fact that PCIe PHY is used in socket-to-socket connection.
it’s surtenly not bad if we see the price differences.
1) Intel Quad CPU vs AMD Dual CPU ?
2) what about dual vs dual or quad vs quad?
3) is DDR4-2666, the fastest memory out now?
4) epyc cpu = $4,200, dual epyc = $8,400 ???
5) intel 8180 =$7,400, quad intel 8180 = $29,600 ???? what the hell are these price for (the full system)
If you are doing direct Intel to AMD comparison, most folks will look in the Intel Xeon Gold 6150 to 6152 range, not the low volume Platinum SKUs.
Another pattern in the Epyc data is that the three neighbors on the same die are not quite the same latency away, two are similar and one ~5ns longer. Assuming the longer one is the diagonal neighbor, then it looks like the numbering order is something like
0 2
3 1
So toggling the least significant bit produces the diagonal neighbor, not one of the closer neighbors.
This could make sense for optimizing heat dissapation rather than optimizing inter-node communication, for schedulers that allocate nodes sequentially.
For two sockets, the timing indicates that to match the arrow diagram they might be numbered like
0 2 | 6 4
3 1 | 5 7
Sorry: “three neighbors on the same die” -> “three neighbors in the same socket”
Great post (also about the adds). Going further: How is even higher clocked RAM comparing, even though not officially supported?
Seeing that you cannot even list the kernel you are using, nor how the latency is being calculated.
Stick to IT work, you have no clue how to conduct a scientific test.
We are on 4.12 for this to help get all of the latest kernel patches for Zen. We have been using updated kernels for many months, and have been offering machine time to OS developers (e.g. Canonical) to help get broader Zen support.
https://www.servethehome.com/amd-ryzen-with-ubuntu-here-is-what-you-have-to-do-to-fix-constant-crashes/
4.12 has bugs under heavy loads for Ryzen and likely Epyc.
Patrick, why not https://www.servethehome.com/amd-epyc-infinity-fabric-latency-ddr4-2400-v-2666-a-snapshot/#comment-460906
al – not supported by vendor systems we have seen thus far. Server side is more conservative with memory speeds than desktop in general. There are HFT focused solutions from Dell EMC, Supermciro and a few others that have pushed memory clocks with certified modules and platforms.
Patrick, yes, as I said “even though not officially supported”, but maybe you could still test it. Imagine again a big speed increase. Some people care about this improvement (and you yourself too because you say it with 2666: “… do not buy an AMD EPYC system with DDR4-2400. Just get DDR4-2666.”) because they don’t have a contract and are not forced to use 2666 at max. If 3200 again is a big win you might say: ~”Use 3200 if you want a big speed improvement and are not forced to stick with 2666.”
There is also a lack of RDIMMs at those speeds. Getting DDR4-2666 is hard enough for us.
@Patrick – Thanks for your work and good humor: “… regularly updated conflicts list, down to pizza companies we have indirect investments in.”.
@Ben – One person has reported that Epyc and Ryzen operate differently on 4.12: https://www.phoronix.com/forums/forum/phoronix/latest-phoronix-articles/967080-ryzen-test-stress-run-make-it-easy-to-cause-segmentation-faults-on-zen-cpus?p=967344#post967344 – there’s a lot of discussion in other posts over there and a Test Script has been developed.
@gc – Interesting observation, thanks.
DDR4-2666 speed can only be achieved with 1 SR-DIMM DPC, or 1 LRDIMM DPC. As soon as you go to 2 DPC, memory speed decreases to DDR4-2133 and Infinity Fabric speed drops accordingly. This is worth mentioning, since the 16 DIMM slots are touted as a significant advantage.
“With DDR4-2400 memory speeds there are significant performance hits that are frankly not worthwhile for anyone ordering a new AMD EPYC system.”
Hi Patrick,
In the “Intel Xeon Scalable 4 Socket UPI v. AMD EPYC Infinity Fabric”, you mention that it compares Xeon to the EPYC + DDR4-2666 but the values in the table are those of the EPYC with DDR4-2400, exaggerating the advantage for Intel’s UPI.
Thanks for some very interesting articles on the EPYCs. I’m looking forward to the full range of tests as they become available. In particular I’m looking to compare the 16-core Threadrippers with the 1P EPYCs to see whether the difference in performance will be worth the difference in the system costs.
Patrick, it would be great to see this article updated for Epyc Rome; much as AnandTech has done: https://www.anandtech.com/show/14694/amd-rome-epyc-2nd-gen/7 .
Comments are closed.