
Today we have our initial benchmarks of a dual socket Intel Xeon Gold 6150 system. One of the biggest questions we have heard lately is around what is going on with the rest of the stack beyond the top-end quad Platinum 8180 and Platinum 8176 systems we already benchmarked. There are a few answers, first, Linux-Bench2 is not quite ready. 80% of the test suite is working well with regressions, but we are working to nail down the last 20%. When we do around 10,000 regression runs, even with many machines doing short 15 minutes per run benchmarks still require over 100 machine days across dozens of systems for us to validate and put into use. In the interest of time, we are going to publish figures based on our legacy Linux-Bench suite.
The Intel Xeon Gold 6150 is a significantly more mainstream part versus the Platinum 8180’s we tested earlier. These chips retail for under $3400 each. With 18 cores, 36 threads and high clock speeds (2.7GHz base 3.7GHz single core turbo) the chips are a higher-TDP 165W variant. Compared to the previous generation of Intel Xeon E5 V4 chips, they are similar to the E5-2697 V4 with significantly higher clocks or the E5-2697A V4 with more cores and slightly higher clocks. Of course, there are a host of architectural improvements with the new Intel Xeon Scalable family. We have a complete architecture discussion you can review via our Intel Xeon Scalable Processor Family (Skylake-SP) Launch Coverage Central. Let us explore how well these chips perform compared to our legacy data set.
Test Configuration
For this test, we are using a relatively standard 2U dual socket setup.
- CPUs: 2x Intel Xeon Gold 6150
- RAM: 384GB in 12x SK.Hynix 32GB DDR4-2666 2RX4 DIMMs
- OS SSD(s): 1x Intel DC S3700 400GB
- NVMe SSD(s): 2x Intel DC P3600 1.6TB AIC
- OSes: Ubuntu 14.04 LTS, Ubuntu 17.04, CentOS 7.2
This is not the highest-end configuration, but it is showing off what the system can generally handle.
Dual Intel Xeon Gold 6150 Benchmarks
For our testing, we are using Linux-Bench scripts which help us see cross platform “least common denominator” results. We are using gcc due to its ubiquity as a default compiler. One can see details of each benchmark here. We are already testing the next-generation Linux-Bench that can be driven via Docker and uses newer kernels to support newer hardware. The next generation benchmark suite also has an expanded benchmark set that we are running regressions on. For now, we are using the legacy version that now has over 100,000 test runs under its belt.
Python Linux 4.4.2 Kernel Compile Benchmark
This is one of the most requested benchmarks for STH over the past few years. The task was simple, we have a standard configuration file, the Linux 4.4.2 kernel from kernel.org, and make utilizing every thread in the system. We are expressing results in terms of compiles per hour to make the results easier to read.
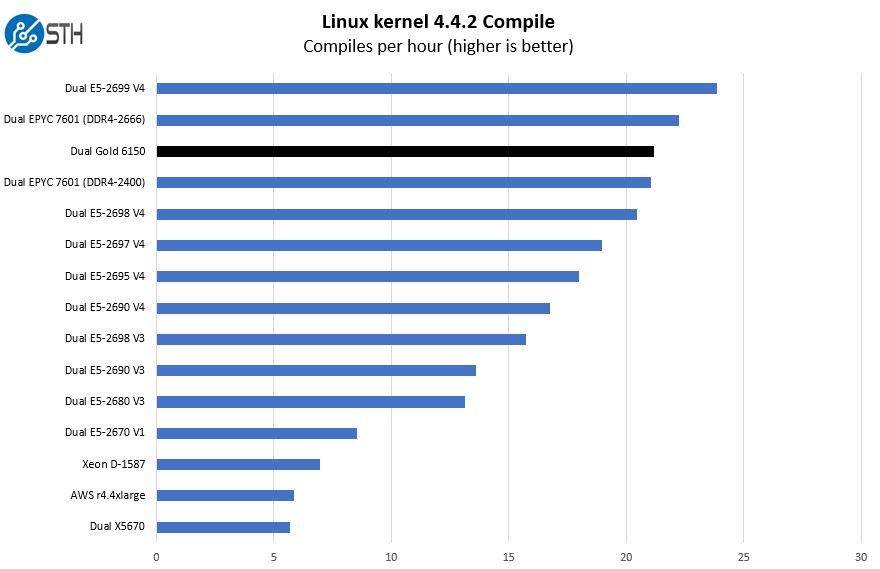
One will notice that we added the dual AMD EPYC results in this chart for an interesting reason: the dual Intel Xeon Gold 6150 falls just between the EPYC 7601 DDR4-2400 and DDR4-2666 results. This also creates a lot of traffic in the caches so we see better scaling than we do in benchmarks were data sits locally. In many of our tests, we will see the Intel Xeon Gold 6150 is close to the Intel Xeon E5-2697 V4. In this instance, the new Skylake-SP architecture plus more memory bandwidth is serving the chips well.
c-ray 1.1 Performance
We have been using c-ray for our performance testing for years now. It is a ray tracing benchmark that is extremely popular to show differences in processors under multi-threaded workloads.
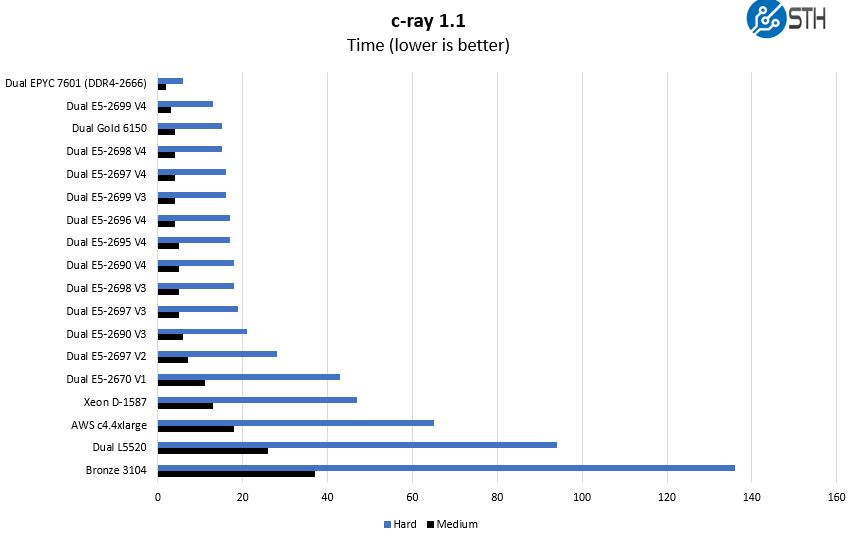
This is an example like Cinebench R15 on the windows side.
7-zip Compression Performance
7-zip is a widely used compression/ decompression program that works cross platform. We started using the program during our early days with Windows testing. It is now part of Linux-Bench.
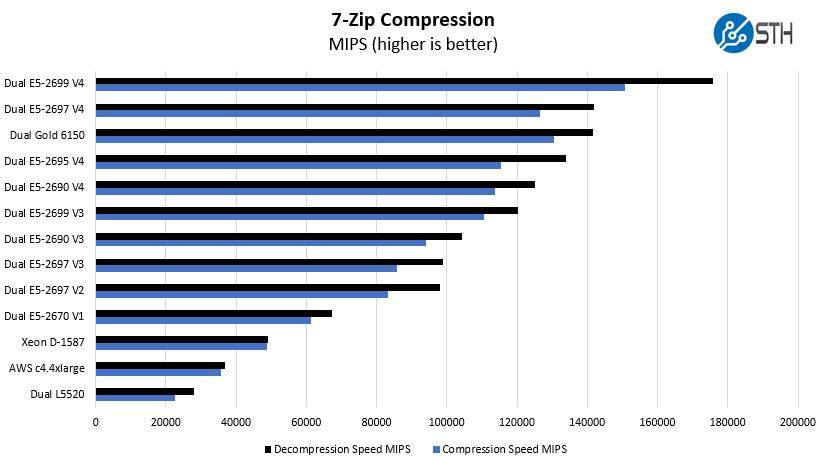
Here you can see that the Intel Xeon Gold 6150 performs very close to a previous generation Intel Xeon E5-2697 V4 configuration. We also wanted to highlight that these chips offer strong consolidation ratios over Sandy Bridge (E5 V1) systems and older.
NAMD Performance
NAMD is a molecular modeling benchmark developed by the Theoretical and Computational Biophysics Group in the Beckman Institute for Advanced Science and Technology at the University of Illinois at Urbana-Champaign. More information on the benchmark can be found here. We are going to augment this with GROMACS in the next-generation Linux-Bench in the near future and already have the first dozen or so machines with AVX-512 and new Zen architecture supporting AVX2 code.
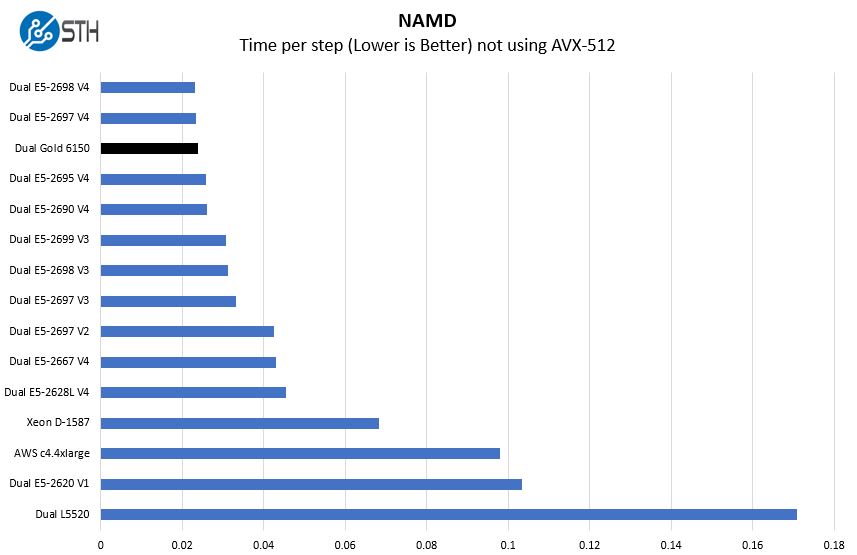
Again, performance is very close to what we would see on the dual Intel Xeon E5-2698 V4. We kept the lower-end dual L5520 and dual E5-2620 V1 just to give a bit more color for those looking to consolidate.
One item to note, in the newer AVX-512 code, we expect the Gold 6150’s to top this chart.
Sysbench CPU test
Sysbench is another one of those widely used Linux benchmarks. We specifically are using the CPU test, not the OLTP test that we use for some storage testing.
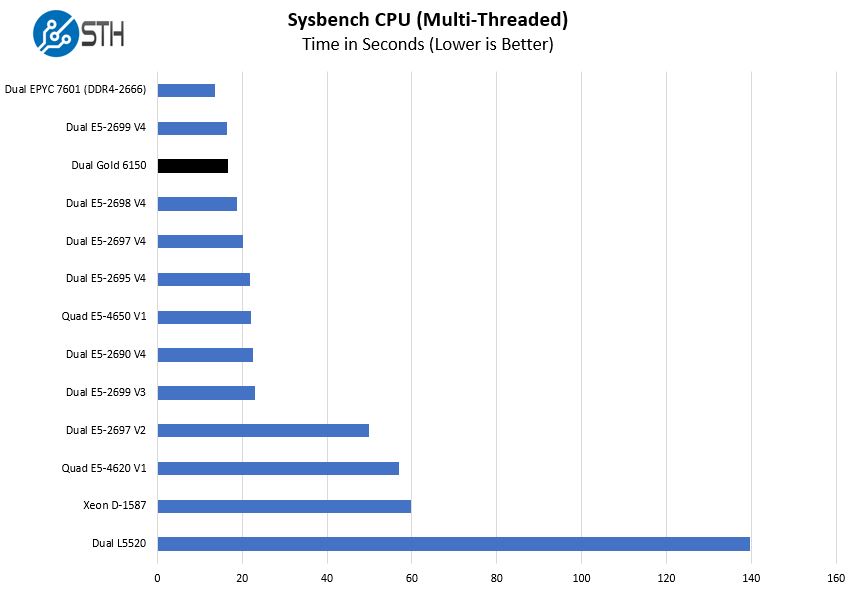
Sysbench does very well on AMD’s architecture as it features less inter-core/ NUMA node movement. The key takeaway here is that the Intel Xeon Gold 6150 performs very well compared to the older generation Xeon E5 V4 parts.
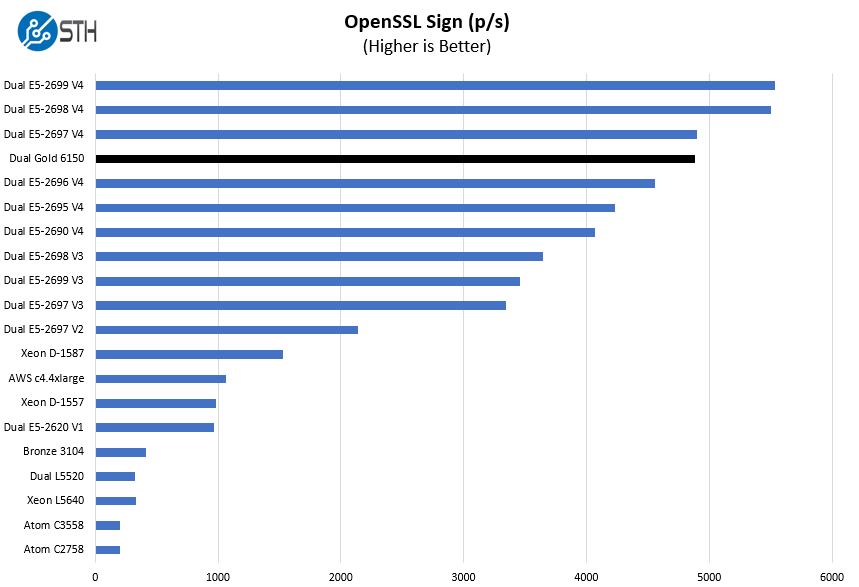
OpenSSL Performance
OpenSSL is widely used to secure communications between servers. This is an important protocol in many server stacks. We first look at our sign tests:
And verify results:
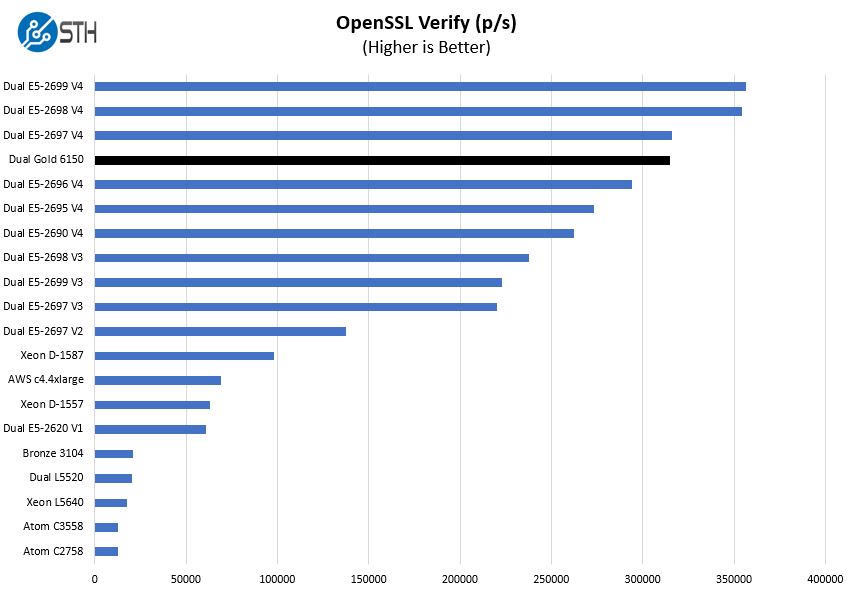
Again, we can see just how close the dual Intel Xeon Gold 6150 setup is to the dual E5-2697 V4 chips in this test.
The next generation of data we are collecting is significantly broader in terms of OpenSSL performance. We are going to maintain this test for backward compatibility.
UnixBench Dhrystone 2 and Whetstone Benchmarks
One of our longest running tests is the venerable UnixBench 5.1.3 Dhrystone 2 and Whetstone results. They are certainly aging, however, we constantly get requests for them, and many angry notes when we leave them out. UnixBench is widely used so it is a good comparison point.
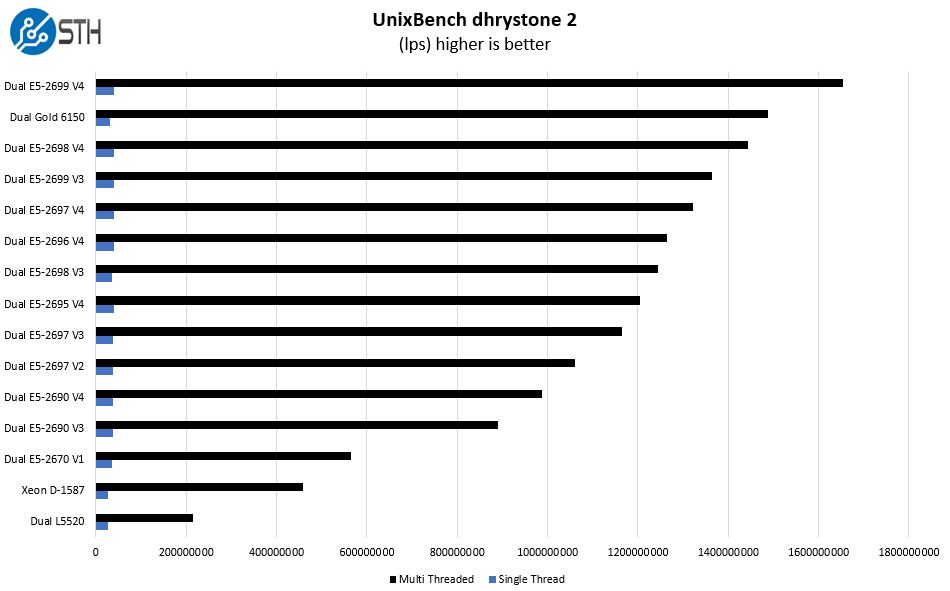
To make this a bit less redundant, we widened the scope of the whetstone comparison numbers:
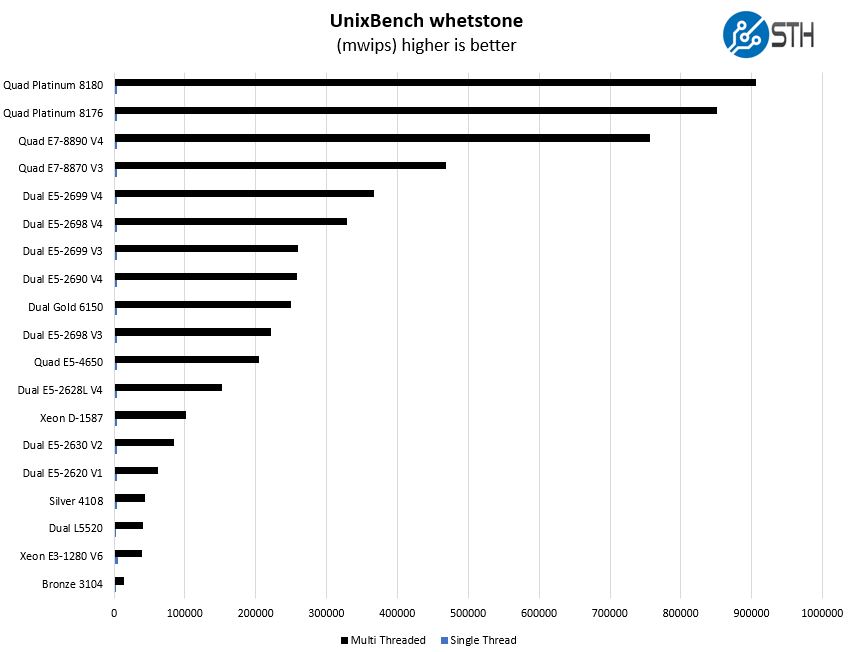
Again, we see a part that is competitive with the higher-end of the previous generation. You can also see where the dual socket configuration falls between the quad Platinum 8180 and the single Bronze 3104.
Final Words
The next generation Intel Xeon Scalable processors are certainly an architectural improvement over previous generations. We are busy generating a huge data set to help you navigate the current generation of processor options. A careful eye will have noticed a few of the Bronze, Silver, Gold and Platinum results we are working on creep into the charts above. Stay tuned for much more to come!



{kind=link}
it’s both interesting and disappointing to see the bronze chip, wherever it’s shown, seems to have less than half the performance of the dual 2620v1 system. I can remember someone claimed Skylake was 50% faster per instruction than SandyBridge, tough it seems the bronze in fact a lot slower per instruction than the E5v1, since sandybridge came with the “inferior” chipset, “slower” memory and most likely also has slower storage.
Patrick,
Why don’t you have Dual AMD EPYC 7601 comparison numbers in all graphs?
@BinkyTO Those charts were generated before all of the EPYC 7601 data had been added to data set due to re-runs. Full numbers later this week.
@xibo the Bronze chips are 1.7GHz without hyper-threading. Really they are intended for allowing you to light a storage, or basic network services platform (e.g. a DNS server) using the least expensive CPU possible.
We have 1P and 2P configurations of both Bronze chips in house. Also, 1x Silver 4108 is about equivalent to 2x E5-2620 V1’s on the Linux Kernel compile benchmark. Perhaps that is a good comparison point.
Looking forward to the full review, Epyc versus Skylake.
Are you planning to do power efficiency benchmarks (i.e performance / power)?
We are trying to get it down to using the same chassis/ PSUs so we can have like for like comparisons.
That may be difficult, but I am working very hard to make it happen.
Also, EPYC v. Skylake is still going to take a bit of time. I want to get more EPYC and more Skylake SKUs. Platinum 8180/8176 and EPYC 7601 are not going to be selling to the same customers so I think being fair to both AMD and Intel requires comparing CPUs priced in similar bands.
Would be great to see more single socket reviews with lower end chips…not everyone has 7000 $ to blow on a dual socket board plus two high end processors. Perhaps geared more towards a simple storage server, for example, along the lines of an e3-1230v5 or e5-16xx or e5-2620v4
Great review and it’s interesting to see that in the main real-world benchmark the 6150 can run compile jobs at basically the same speed as the much larger Epyc.
I have a question though, you list three different operating system versions: OSes: Ubuntu 14.04 LTS, Ubuntu 17.04, CentOS 7.2
How do those OS choices factor into the final results? Are there any big differences that you have observed between OS versions?
We already have the first four benchmarked:
Xeon Bronze 3104
Xeon Bronze 3106
Xeon Silver 4108
Xeon Silver 4114
Doing both 1P and 2P configurations. Also, I believe we have the 4112 and 4110 already or en route.
It’s like Intel wants us to buy AMD.
why there is no and power consumption test/chart?
*any
We do power consumption at the system level. Power supplies, chassis cooling fans, drives, onboard devices such as BMCs, NICs, and SAS controllers all have a large impact on power consumption.
Some of the systems we test we are able to get CPU information from, but you would not want to use for power consumption.
It would be pretty bad to try comparing two different systems for different use cases and trying to show power consumption for the CPU.
Yes but can You show us a similar chart like this for those gold/plaitnum xeons?
https://www.servethehome.com/wp-content/uploads/2017/06/Dual-AMD-EPYC-7601-in-Supermicro-2U-Ultra-Power-Consumption.jpg
After counting different between idle and full load we can estimate CPUs power consumption.
PS. What about this this answer for @BinkyTO “EPYC 7601 data had been added to data set due to re-runs. Full numbers later this week.” Week is ending so we are impatient :)
I must say that you have provided me with the most important recent resource in my general work, thank you Patrick. I have saved for another day the long appreciation to which I hope to return where and when appropriate. I am very grateful to you beyond simple comments, for addressing the very areas most likely to cause confusion amongst the customers and colleagues I know, at any rate. I only hope that the evangelism I’ve so happily indulged will also result in business for you and not merely even my highest praise, which I must make sure you hear!
Would you by any chance be likely to test the 4 and low core, top frequency, 4 and higher socket count servers, as and when possible?
Those are very much my main machines. For such a variety of reasons I began to vignette, but nearly wrote a precis of my business history! Dozens of causes interact with this less common selection. What I do, really responds to high L2, L3, and high clocks. However, and averting the diversion pulling me again… I see possibly how the core interconnection bandwidth and latency as well as arranging demand my better attention.
I think this generation of chips is going to have some very unexpected effects in some companies and installations. My own application is going to be tough to deploy, wanting both high memory and AVX512 advantages and I’m looking to some quite unusual approaches to try to capture as much of each as possible. Including splitting the applications. Or using Scale MP like clustering. Even processor affinity if I read correctly that Windows Server is not sick upon encountering heterogeneous server configuration. The Compaq, HP Superdome was surely meant to solve this problem? But I don’t remember well enough to know. That will be interesting, when, assuming that it goes well, Open VMS arrives on x64. I am sure that the Itanium silicon had to be brought to Xeon, to enable that port, something about Alpha chips having stack machine like registers… I am long ago superannuated!
I cannot speak highly enough of your website! Thanks for all your help and efforts, I almost never don’t mention it, if opportunity arises!
John – working on this by next week we should have in the lab about 33-35% of all 1P and 2P Skylake-SP and EPYC performance variants covered. The Silver 4112 is the first low core count chip we have, albeit without the higher-end AVX512. https://forums.servethehome.com/index.php?threads/sth-project-xavier-placeholder.16008/
Thank you for your kind words.
Patrick, if instead of 10,000 runs, you did 1,000 runs, wouldn’t you still have very good results? What is the advantage of going from 1,000 runs to 10,000 runs? I bet the number you would get after 1,000 runs would still be within +-0.1% of what you get after 10,000 runs and that should be good enough.
It is taking ages for the full Epyc vs Skylake-EP review and still to date we have these pieces where Epyc is not even featured in all charts for a proper Dual Gold vs Dual Epyc comparison.
As others have noted here, we all appreciate very much your work and your site. That is why we care. But maybe you are wasting lots of efforts and resources for very little benefit. You of course know your stuff very well, but we usually increase sample size when we are studying something that has high variability, like human behaviour/opinion. In those cases, a sample of 100 is quite often not enough. But you instead is sampling a processor running the exact same code on the exact same platform multiple times. The variability should be minimum and therefore a smaller sample should be very precise already.
Hi Marcelo,
We just got the Gold 6154’s in last week which should be a good comparison to EPYC.
EPYC systems are just starting to ship BTW and there are several announced vendors still not shipping. Still very early days for EPYC. Also, we have been told by several distributors that it will be until end of August/ early September for the 7251’s.
Still, progress is being made. The number of runs is more due to the fact that we re-run the set when we make changes. For example, our “large” GROMACS benchmark has had 3 revisions in the last 10 days. Multiply by the fact we are running regressions on Intel Xeon E5 V3, V4, Xeon D, Atom C3000 series, E3 V5/ V6, EPYC, and the fact we are also doing 1P / 2P configurations it ends up being a lot of testing. 40 systems 100 runs each is 4000 runs.
Understood on your frustration. We share it. We were not going to publish original Linux-Bench numbers for the newest gen of EPYC/ Skylake-SP, however, we want to ensure we have data we can trust.
Hello,
Any chance of seeing a comparison between the Gold 6154 and the Epyc 7601 any time soon ? I am in the process of deciding between dual 6154 and dual 7601 nodes for a small HPC cluster and it has been close to impossible to find benchmarks on the 6154 …
I would also like to say that your work is invaluable and very much appreciated by those of us that must take well-informed decisions.
Jose – appreciate the kind words. We have the data, just stuck in the publishing queue.
Comments are closed.