
This has to be one of the strangest stories of 2021 thus far. Graphcore finally submitted MLPerf Training v1.0 results. While some may have assumed that a dedicated AI accelerator would handily beat a NVIDIA GPU-derived architecture in terms of performance, or at least price performance, that is not exactly what happened. While many read Graphcore’s blog post and celebrated a victory, the details are quite a bit more nuanced.
The Context
As a bit of a backstory, this week when Cliff’s MLPerf Training v1.0 results went live I was actually testing a few NVIDIA HGX A100 8x GPU systems for a piece that will go live, after our review of an Inspur HGX A100-based server goes live, in the very near future. We have been working with OEMs to get their big GPU servers tested, the kinds that cannot be powered on standard 208V 30A North American data center circuits. This is all for a series we are running in July. At this point, the STH team and I have gotten to know the A100 platforms from PCIe cards, Redstone, and Delta parts, even ones that are not on the official spec sheets.

When I saw Cliff’s initial draft, he flagged something for me to look at. I thought it was a bit harsh on Graphcore’s performance so that was toned down a bit. Then after I was done with the hands-on session, I had a few folks highlight Graphcore’s glowing analysis of its own results. It was time to see what was going on. For those who are unaware, I have been very excited about Graphcore for some time. Prior to the MLPerf results, I would have enthusiastically put them in the camp of top AI training chip contenders.
Analyzing Graphcore’s Celebratory Analysis
In Graphcore’s blog post about its MLPerf Training v1.0 results, it states:
For both ResNet-50 and BERT, it is clear that Graphcore systems deliver significantly better performance-per-$ than NVIDIA’s offering.
In the case of ResNet-50 training on the IPU-POD16, this is a factor of 1.6x, while the Graphcore advantage for BERT is 1.3X. (Source: Graphcore Blog)
These statements are perhaps true, but require looking at a specific, effectively irrelevant comparison. Since this is STH, we are going to share why with the context that, of course, we are the site in the world that actually does hands-on independent server reviews in our various data center facilities. This is one of those areas where our direct experience intersects questionable vendor marketing and so we call that out so millions of STH readers can get to a better level of industry understanding.
First, let us get to the numbers. We tried to get a section of the results that are comparatively closest to the Graphcore IPU-POD16 figures. With MLPerf Training v1.0, each system does not have to run every test so most submissions were for 1 or 2 tests, not all eight. There are also many submissions for clusters, so we wanted to remove those as well.
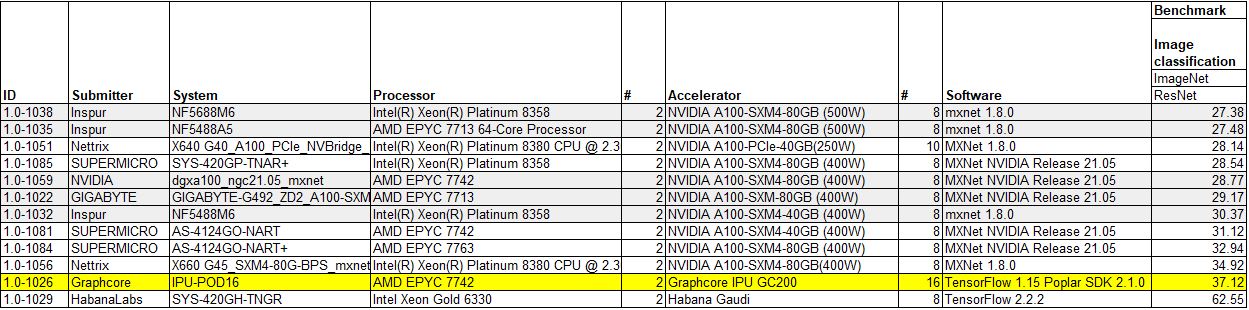
Specifically in this section, we are highlighting the Graphcore IPU-POD16 results as those were the primary focus for comparison with NVIDIA’s offerings in the Graphcore blog. We whittled down the results to somewhat comparable systems, then ordered them based on the benchmark Graphcore is focusing on instead of the MLPerf ID. In the above case, this is the ResNet-50 benchmark. Here is Graphcore’s blog post comparison:

Here, Graphcore is claiming a 1.6x advantage over NVIDIA. Graphcore is using its “Closed” division result and did not provide an “Open” division result. Graphcore highlights its 37.12 minutes to complete the benchmark while the NVIDIA DGX A100 takes 28.77 minutes which is the result 1.0-1059. Looking at 1.0-1059 we can see this is using the SXM4-based A100’s that are the 80GB 400W models. One may immediately look at the Inspur NF5488A5 result and see 27.48 still using AMD CPUs. We will have a review of the Inspur NF5488A5 next week, but the 1.0-1035 result is using the 500W variant so we should exclude it here. They have been offered by most OEMs for some time, but are not listed on NVIDIA’s current A100 data sheet which only lists 400W models. We also have a piece using the 500W GPUs in a system from another OEM coming in July. That one is waiting on the YouTube video to be complete. Here is what the 8x NVIDIA A100 80GB 500W nvidia-smi looks like:
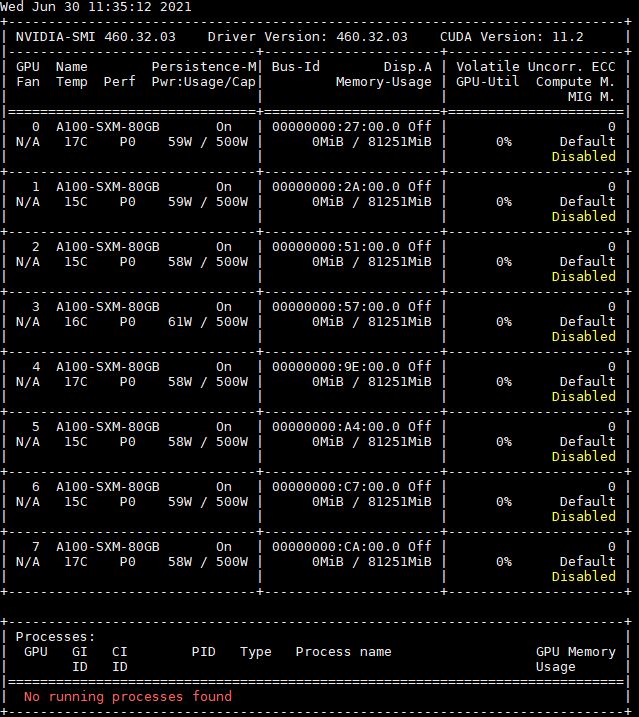
Here is the 40GB 400W version for comparison:
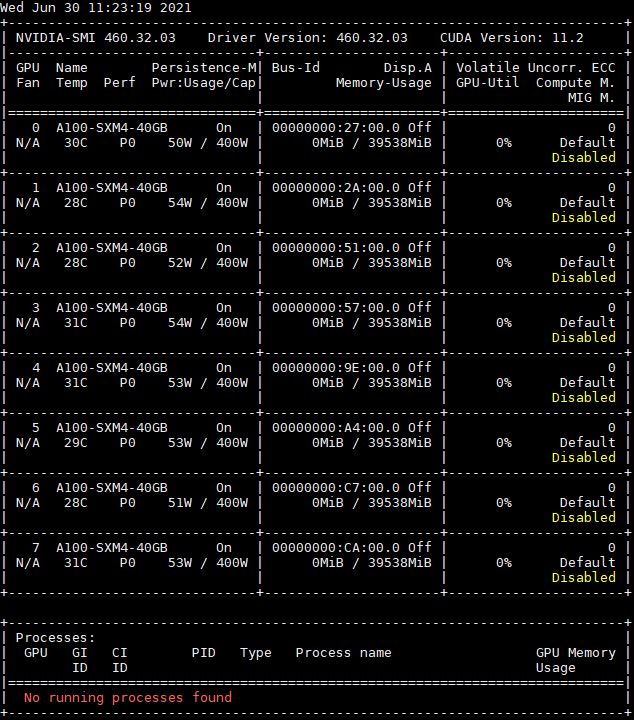
For now, the 500W A100 is a bit of a different solution, so it is most relevant to use the 80GB 400W systems for the top-of-line NVIDIA to Graphcore comparison, not the 500W parts. One will notice that the Supermicro SYS-420GP-TNAR+ result 1.0-1085 is slightly faster than the NVIDIA DGX result that Graphcore is comparing its IPU-POD16 to. This is important and we will get to that in a bit.
The other big result that Graphcore highlighted was its natural language processing (NLP) BERT benchmark result. Again, it is highlighting that while it is significantly slower, it is less expensive which is why Graphcore was claiming some sort of victory. Although we are going to show why that claim, as with ResNet-50 is not exactly relevant, there is something more important going on here.
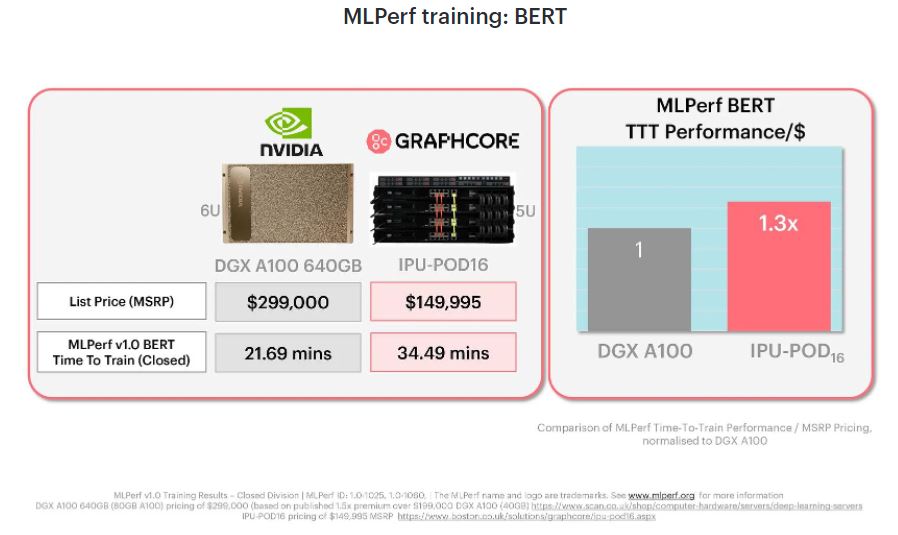
Graphcore mentioned that while it submitted its Closed division result, it used the Open division to really show what its solution could do if it was allowed to tune as it pleased and not go by the uniform benchmark standard. Since MLPerf is heavily supported by NVIDIA, it is likely we will see other AI vendors use the Open division to compete. Kudos should be given to Graphcore for publishing both results. Below is a look at the NLP BERT results with Graphcore highlighted.
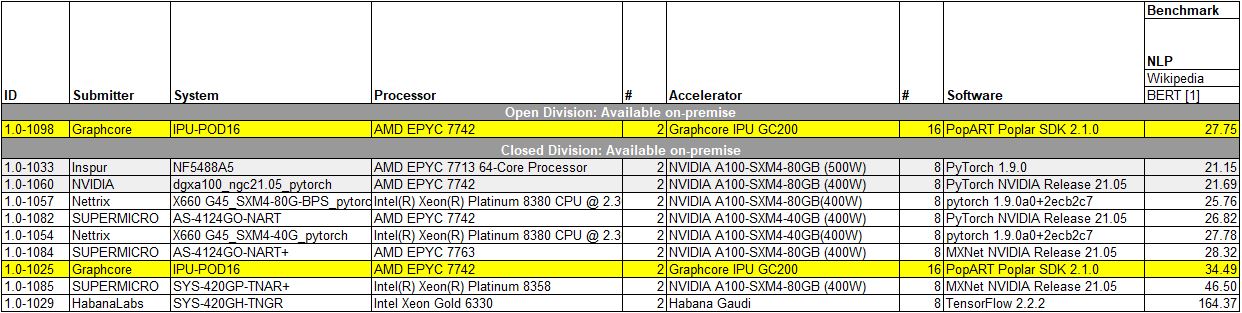
Here we see the NVIDIA result of 21.69 minutes in 1.0-1060 compared to Graphcore’s Closed 1.0-1025 result of 34.49 minutes and 27.75 minute open result in 1.0-1098. In either case, NVIDIA ended up faster. We are also going to note on the above that the Supermicro systems did not use PyTorch with the 400W 80GB A100’s so we do not have that direct comparison point here.
The short summary is that Graphcore is showing performance of its IPU-POD16 with 16x GC200 Mk2 IPUs that is below 8x NVIDIA A100 80GB 400W SXM4 modules. Since it cannot claim a performance victory, even disregarding the Closed division guidelines and submitting in the Open division, Graphcore is using a price/ performance comparison to celebrate victory.
The question remains, what are we actually comparing here? Let us get into some of the important details.



{kind=link}
This is why STH is great.
– Vendor “Yo we’ve got some BS to peddle.”
– STH “OK but here’s how it works and some actual data.”
You’ve been critical of NVIDIA before so it is good to see you’re being consistent.
We buy hundreds or thousands of GPU servers a year. You’re correct that we’re paying half of the $300K that Graphcore is using. Calling that “fantasy” is correct if you’re comparing real world price performance. We get a discount over what you’re using for the HGX A100’s but it isn’t that far off.
You could’ve stopped with just people don’t pay 300K for a system with 8 11-15k GPUs because that’d be stupid. Great analysis tho. Graphcore sells to AI shops that have smart engineers. I don’t see why they’ve used 300K since that’s not real. We also have A100 systems and they weren’t 300K.
You’re missing that the point of the article is not just about Graphcore.
It’s really a cautionary article for other AI startups looking to submit to MLPerf.
I’d only add that Google competes well in MLPerf but others shouldn’t even try.
I agree that comparing list price of high-end equipment is of little use because the procurement policy at most organizations for such expensive stuff involves a special contract negotiated by a purchasing department.
Thanks for including the energy analysis at the end of the article. From a technology point of view, performance per watt is much more interesting. It may also be more relevant in terms of total cost of ownership.
In the future it would be nice to measure total energy and time needed for each system to complete the same task for a number of different machine learning related activities.
You are right that Graphcore shouldn’t have participated in MLPerf.
My comment is you should make the PCIe-RedStone-Delta its own article so it is easy to reference. That and the DELTA label pic are golden.
Patrick, do you have any similar real-world pricing for the Graphcore solutions? NVIDIA is sold at 50% of MSRP but if Graphcore is similarly discounted then their comparison still holds.
ListVLower if you read, he’s saying the LIST of the HGX A100 is in the 150-180k range before discounts. This is a very educated view of pricing because all this is priced at the cluster level and it’s not priced at the node.
It’s a little silly to make the price comparison because any organization that is buying a specialized training computer is spending a multiple of what it costs on developers, “data scientists”, labeling and such.
The devs already know something about the NVIDIA ecosystem and won’t feel like they’re wasting time learning more. (e.g. as it is widely used in ML, image synthesis, etc.) NVIDIA also has some nice tools that would be hard for GraphCore to match. Dev(s) can even develop with laptop & desktop cards w/ NVIDIA but w/ Graphcore Dev(s) will have to fight for access to the server and put up with a slower training cycle so add it all up and they will be less productive and you’ll pay back whatever you saved on the machine — if you really saved on the machine.
In inference there is more the case new tech can be transformative, but not if we are talking a factor of 1.2x but more if there is a factor of 12x. (Incredible if memory bandwidth is anywhere near being the memory bottleneck)
An alternative takeaway is that this is the first time we get real numbers out of these startups, and they’re not good. “Focusing on customers” is not going to do much if your platform is not competitive.
I think saying that all these startups chose to not participate is being generous. I guarantee that everyone who has working hardware ran the suite. The absence of good results should be taken as a signal that they aren’t competitive, not that they didn’t bother trying.
—–
As always, great in-depth reporting!
The text under the “ML Perf training: ResNet-50” image states
“Graphcore highlights its 32.12 minutes to complete the benchmark while the NVIDIA DGX A100 takes 28.77 minutes which is the result 1.0-1059.”
The time shown in that image for Graphcore is 37.12, not 32.12
Thanks for the catch Grant!
There seems to be typos in:
“One major OEM had too think of thermal paste”
and
“Instead, and OEM purchases the NVIDIA Redstone platform and integrates it”
You might like to fix. Thanks :-)
This is one where STH shows why its #1 in server analysis. Usually the next platform does good stuff but they swung and missed on this one. The HGX A100 8 GPU bits, power, and the “cluster” view where the training systems are only part of the deployed solution are relevant and this is an insane level of depth.
Just know we appreciate it.
“We will have a review of the Inspur NF5488A5 next week, but the 1.0-1035 result is using the 500W variant so we should exclude it here. They have been offered by most OEMs for some time, but are not listed on NVIDIA’s current A100 data sheet which only lists 500W models.”
only lists.. 400W models?
@Chu Lim I’d bet Graphcore sponsors TNP.
Amazing stuff! For years i was getting the impression, that those gazillions of startups would be much more competetive than they now actually seem.
That NVIDIA is holding up so good with GPU derivied silicon against supposedly hyper-optimized silicion exclusively design for AI is stunning.
Just a naive view from a AI novice.
Again, really amazing article!
The site NextPlatform’s article aligned with GraphCore’s claims: https://www.nextplatform.com/2021/06/30/graphcore-right-on-the-money-in-first-mlperf-appearance/
U?s?u?a?l?l?y? almost always their articles are better than that.
@Moderator, I noticed that my comment was deleted; was there a problem with it?
Comments are closed.