Gigabyte G481-S80 GPU-to-GPU Performance
With our system, we have the ability to do peer-to-peer GPU-to-GPU transfers over NVLink. That is different than the single root and dual root PCIe servers for deep learning. For our testing, we are using 8x NVIDIA Tesla P100 16GB SXM2 modules. Folks would probably want us to use Tesla V100 32GB modules, but STH has a tight budget for buying GPUs.
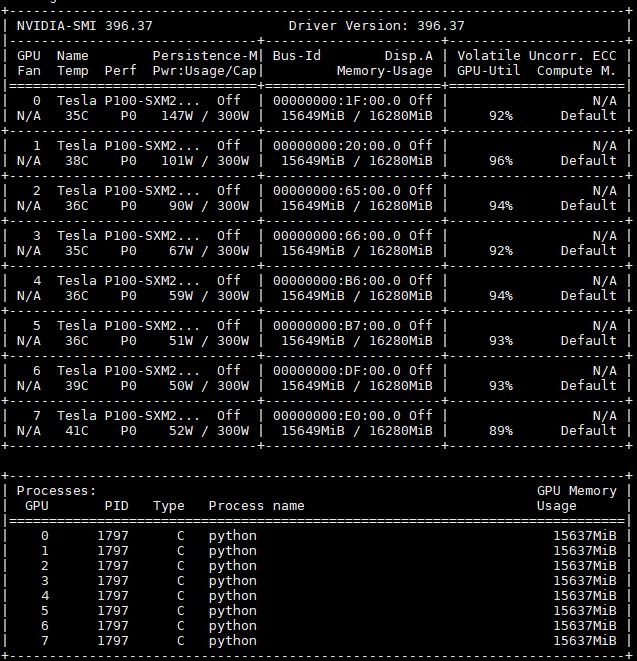
First off, we wanted to show that our 8x NVIDIA Tesla P100 16GB GPUs in the Gigabyte G481-S80 SXM2 GPU complex. This is important since we saw with the system topology that the GPUs are attached to different CPUs.
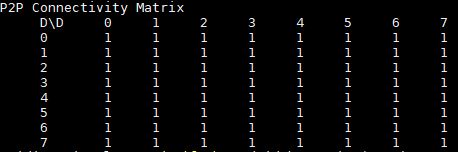
With NVLink, we have 64x PCIe uplink lanes to the server’s CPUs while maintaining peer-to-peer connectivity. As we covered in our piece: How Intel Xeon Changes Impacted Single Root Deep Learning Servers, with a PCIe switch architecture and Intel Xeon Scalable, one is limited to 16x PCIe lanes attached to one CPU. The Gigabyte G481-S80 is significantly more efficient.
NVIDIA Tesla P100 SXM2 / DGX-1 P2P Testing
We wanted to take a look at what the peer-to-peer bandwidth looks like. For comparison, we have DeepLearning10, a dual root Xeon E5 server, and DeepLearning11 a single root Xeno E5 server.
Gigabyte G481-S80 P2P Bandwidth
Here is the bidirectional P2P bandwidth on the dual root PCIe server:
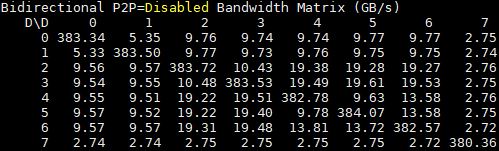
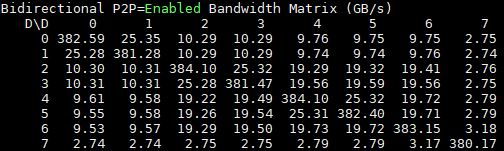
Here is that same server with P2P enabled. You can see a large uptick in performance.
Moving to the 10x GPU DeepLearning11 one can see the P2P disabled results:
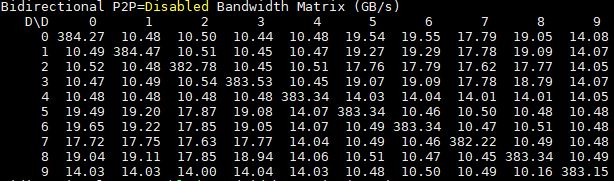
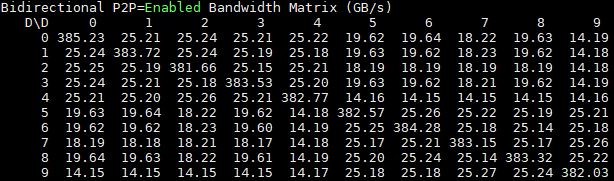
Here are the P2P enabled results:
Here is the Gigabyte G481-S80 DeepLearning12 system with 8x NVIDIA Tesla P100 SXM2 GPUs and P2P disabled:
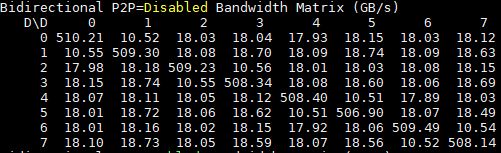
Here are the P2P enabled figures for DeepLearning12:
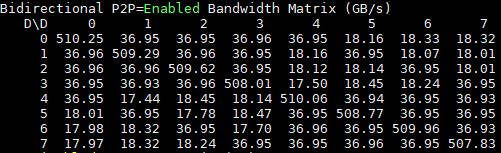
You can clearly see single versus dual hop NVLink runs. For the single hop runs you can see nearly 37GB/s compared to the figures just over 25GB/s for the PCIe 3.0 root systems.
Gigabyte G481-S80 P2P Latency
That shows the DeepLearning12 figures for the latency between the Gigabyte G481-S80’s eight GPUs:
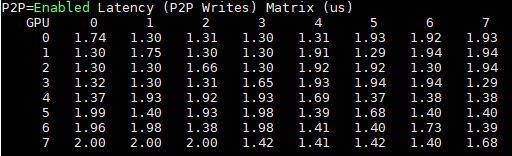
Comparing these to the dual root server’s P2P results, you can see a huge latency jump.
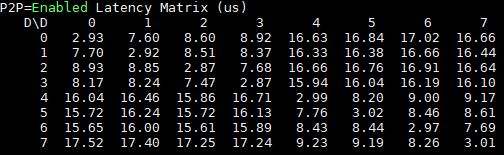
Even the single PCIe root server had a 2-3x increase in P2P latency over the DeepLearning12.
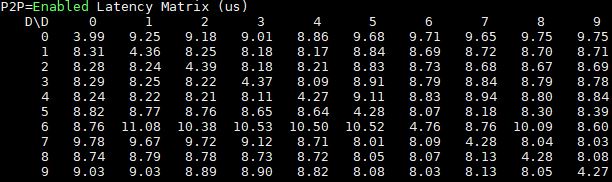
The key here is that the solution is vastly improved over the PCIe solutions, and that is a major selling point over single root PCIe systems. Looking at this, you can clearly see why NVLink users tout GPU-to-GPU latency benefits.
Gigabyte G481-S80 with 8x NVIDIA Tesla P100 GPU Linpack Performance
One of the other advantages of a solution like this is the double-precision compute performance. While many in the deep learning community are focusing on lower precision, there are HPC applications, and indeed many deep learning applications that still want the extra precision that dual precision offers. Linpack is still what people use for talking HPC application performance. NVIDIA’s desktop GPUs like the GTX and RTX series have atrocious double precision performance as part of market de-featuring. We are instead using some HPC CPUs for comparison from Intel, AMD, and Cavium.
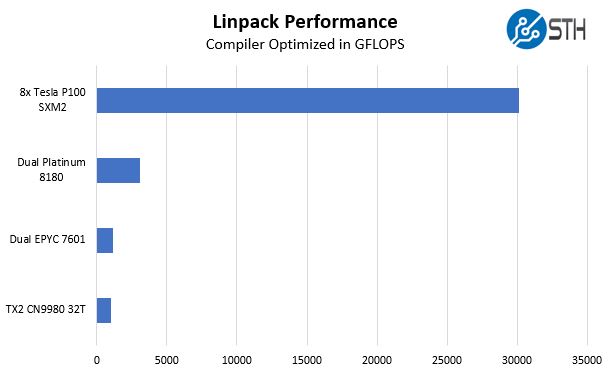
That is hugely impressive. Note here, each of these results probably has more tuning possibilities, but the improvement is immediately noticeable.
This is an area where the DeepLearning11 server with its 10x NVIDIA GeForce GTX 1080 Ti’s cannot compete due to its double precision compute performance being hamstrung. One can clearly see why Tesla GPUs are popular in the HPC world. While the deep learning crowd focuses on features like INT8 support and single or lower precision floating point performance, there is something to be said about deploying a box that can handle many types of compute. The NVIDIA Tesla P100 card also features ECC memory which can be important in large simulations.



{kind=link}
Gromacs would be a nice benchmark to see.
Thanks for doing more than AI benches. I’ve sent you an e-mail through the contact form on a training set we use a Supermicro 8 GPU 1080 Ti system for. I’d like to see comparison data from this Gigabyte system.
Another thorough review
It’s too bad that NVIDIA doesn’t have a $2-3K GPU for these systems. Those P100’s you use start in the $5-6K each GPU range and the V100’s are $9-10K each.
At $6K per GPU that’s $48K per GPU, or two single root PCIe systems. Add another $6K for Xeon Gold, $6K for the Mellanox cards, $5K for RAM, $5K for storage and you’re at $70K as a realistic starting price.
Regarding the power supplies, when you said 4x 2200W redundant, it means that you can have two out of the four power supplies to fail right?
I’m asking this because I’m might be running out of C20 power socket in my rack and I want to know if I can plug only two power supplies.
Sorry, my question’s reply is in the marketing video.
They are 2+N power supplies.
Interested if anyone has attempted a build using 2080Tis? Or if anyone at STH would be interested. The 2080 Ti appears to show much greater promise in deep-learning than it’s predecessor (1080Ti), and some sources seem to state the Turing architecture is able to perform better with FP16 without using a single many tensorcores as former Volta architecture. Training tests on tensorflow done by server company lambda also show great promise for the 2080Ti.
Since 2080Ti support 2-way 100Gb/sec bidirectional NVlink, I’m curious if there are any 4x, 8x (or more?) 2080ti builds that could be done by linking each pair of cards with nvlink, and using some sort of mellanox gpu direct connectX device to link the pairs. Mellanox’s new connectX-5 and -6 are incredibly fast as well. If a system like that is possible, I feel it’d be a real challenger in terms of both compute-speed and bandwidth to the enterprise-class V100 systems currently available.
Cooling is a problem on the 2080 Ti’s. We have some in the lab but the old 1080 Ti Founder’s edition cards were excellent in dense designs.
The other big one out there is that you can get 1080 Ti FE cards for half the price of 2080 Ti’s which in the larger 8x and 10x GPU systems means you are getting 3 systems for the price of two.
It is something we are working on, but not 100% ready to recommend that setup yet. NVIDIA is biasing features for the Tesla cards versus GTX/ RTX.
Comments are closed.