AMD EPYC 7003 Initial Performance Observations
This was an immensely challenging section to do. The benchmarking was the relatively easy part. The hard part was picking the comparison group. AMD specifically sent us sets of high-end SKUs. Also, since we have a lot of high-end GPU compute servers in the lab to review over the next few weeks, those are also using 64-core CPUs.

As a result, we are stuck with 128 core / 256 thread EPYC 7763 and EPYC 7713 CPUs along with the 32 core 280W TDP EPYC 75F3. With those, we had a choice on the Intel Xeon comparison. Either we use the Intel Xeon Gold 6258R/ Platinum 8280 2P configurations as top-end dual-socket, or we include the Cooper Lake 3rd Generation Intel Xeon Scalable 4-socket parts.
That was immensely challenging to decide on. The Cooper Lake parts are higher performing and have the same socket-to-socket bandwidth as the Cascade Lake Refresh parts, but are really for a different segment. Ultimately, we are largely going to include both. It felt unfair to exclude Intel’s most current and highest performance SKU since we had data for it. Also, with 112 cores in a 4P system, that is close to AMD’s 128 core 2P. We just wish we had more mainstream parts. One of the challenges with doing launch day reviews is that our selection is limited to what AMD wants to sample. As is understandable, AMD wants to highlight its top-end chips that it knows Intel will not challenge with Ice Lake. This is doubly hard when you have a good sense of how improved the Ice Lake Xeons are. Launch timing is what it is so we will circle back on the Ice Lake numbers when we can.
Python Linux 4.4.2 Kernel Compile Benchmark
This is one of the most requested benchmarks for STH over the past few years. The task was simple, we have a standard configuration file, the Linux 4.4.2 kernel from kernel.org, and make the standard auto-generated configuration utilizing every thread in the system. We are expressing results in terms of compiles per hour to make the results easier to read:
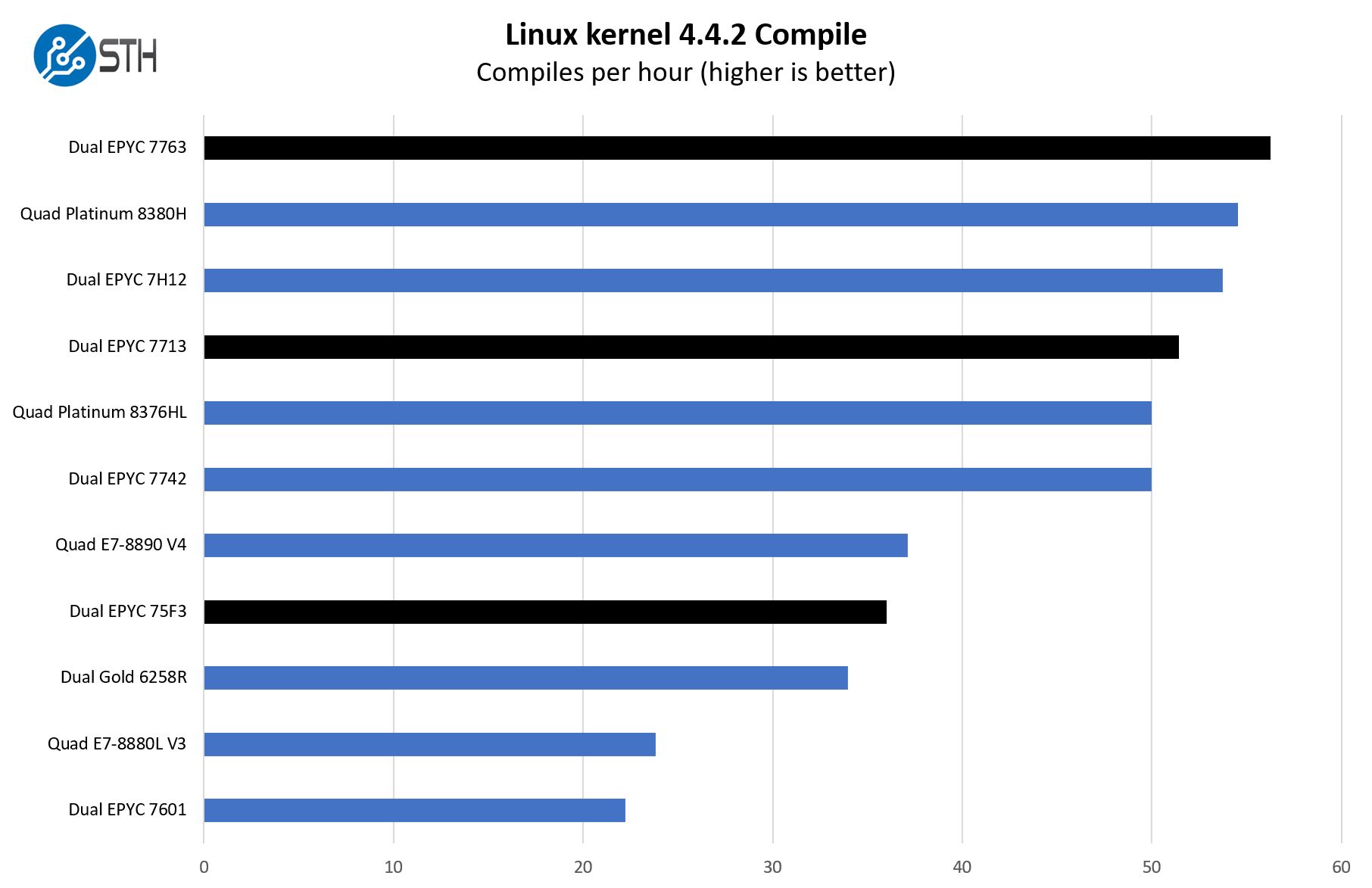
This is an interesting case. Here we can see that the dual AMD EPYC 7763 slightly edges out the quad Intel Xeon Platinum 8380H setup, but the dual EPYC 7713 is just below that figure. What this practically means is that with Cooper Lake’s higher TDPs, Intel is closer to the per-core performance, even if it is with a higher net TDP and twice the number of sockets. Still, if you need 18TB of memory or Optane PMem in a system, the delta is such that the Cooper Lake system is still very relevant.
7-zip Compression Performance
7-zip is a widely used compression/ decompression program that works cross-platform. We started using the program during our early days with Windows testing. It is now part of Linux-Bench.
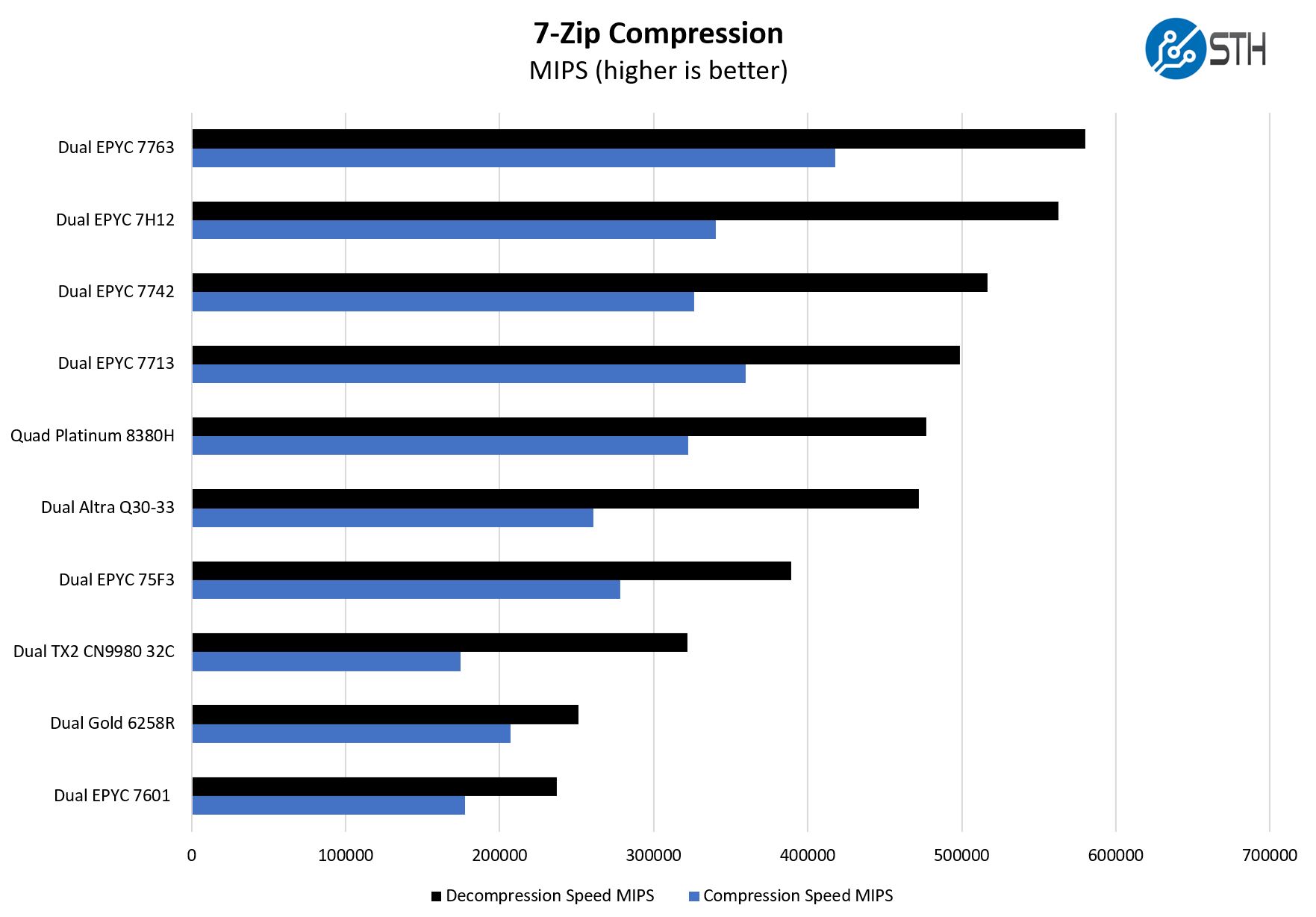
On the 7-zip compression side, we sort by decompression speed as we have done for what is getting close to a decade. There the AMD EPYC part does very well. We can finally see AMD pushing well beyond even the Ampere Altra Q80-33. Where Ampere was in the right performance arena for Rome, it will need the 128 core Altra Max to compete with Milan.
c-ray 8K Performance
Although not the intended job for these, we also just wanted to get something that is very simple and scales extremely well to more cores.
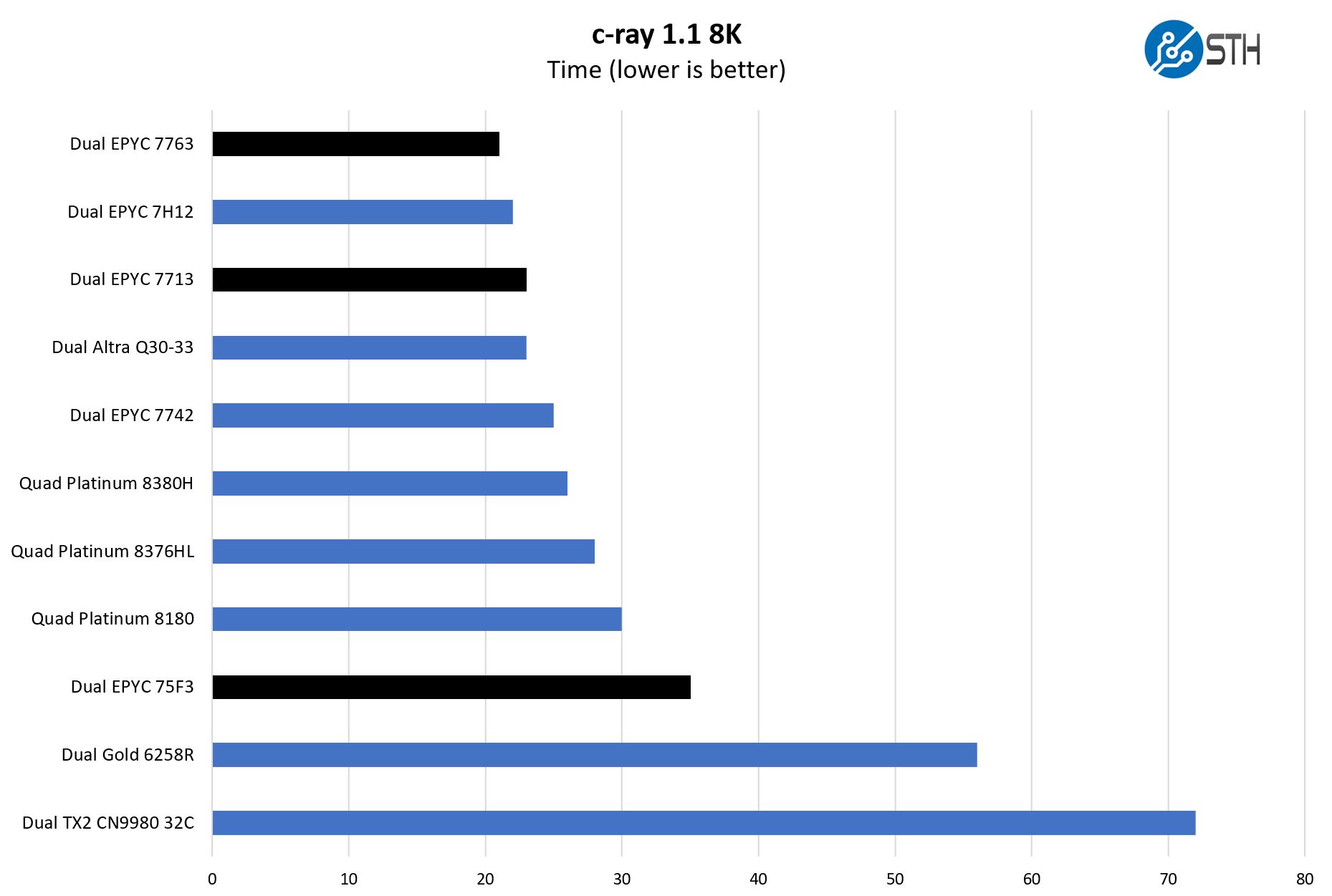
This is immensely fun. When we first incorporated c-ray, we used a 4K result and it would often take 15 minutes on high-end server hardware. Then we moved to a harder 8K setup, and again we saw long times on then-modern hardware. Now, modern processors absolutely crush this workload to the point where perhaps we need a 32K version given what we know about 2021-2023 CPU scaling.
OpenSSL Performance
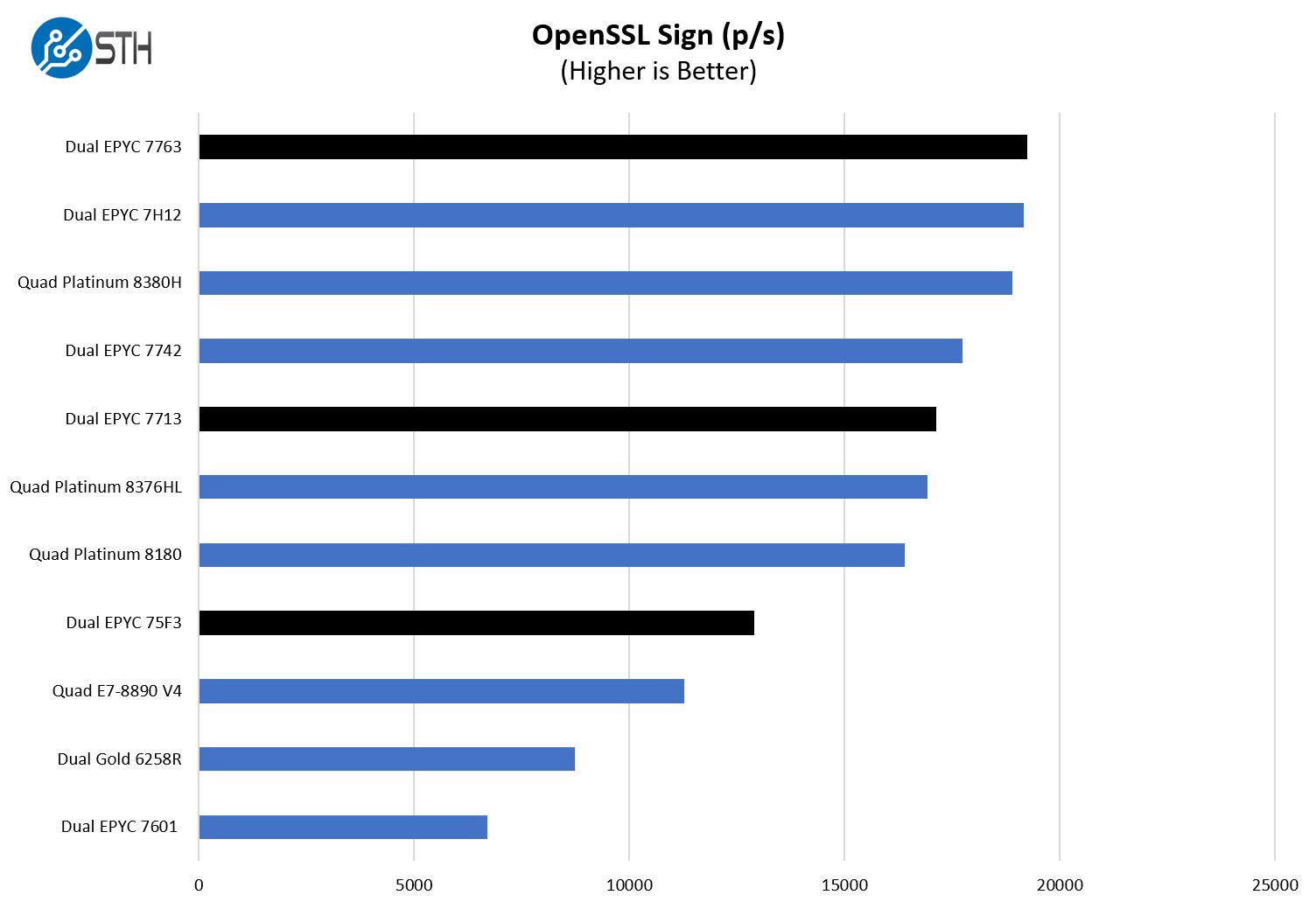
OpenSSL is widely used to secure communications between servers. This is an important protocol in many server stacks. We first look at our sign tests:
Here are the verify results:
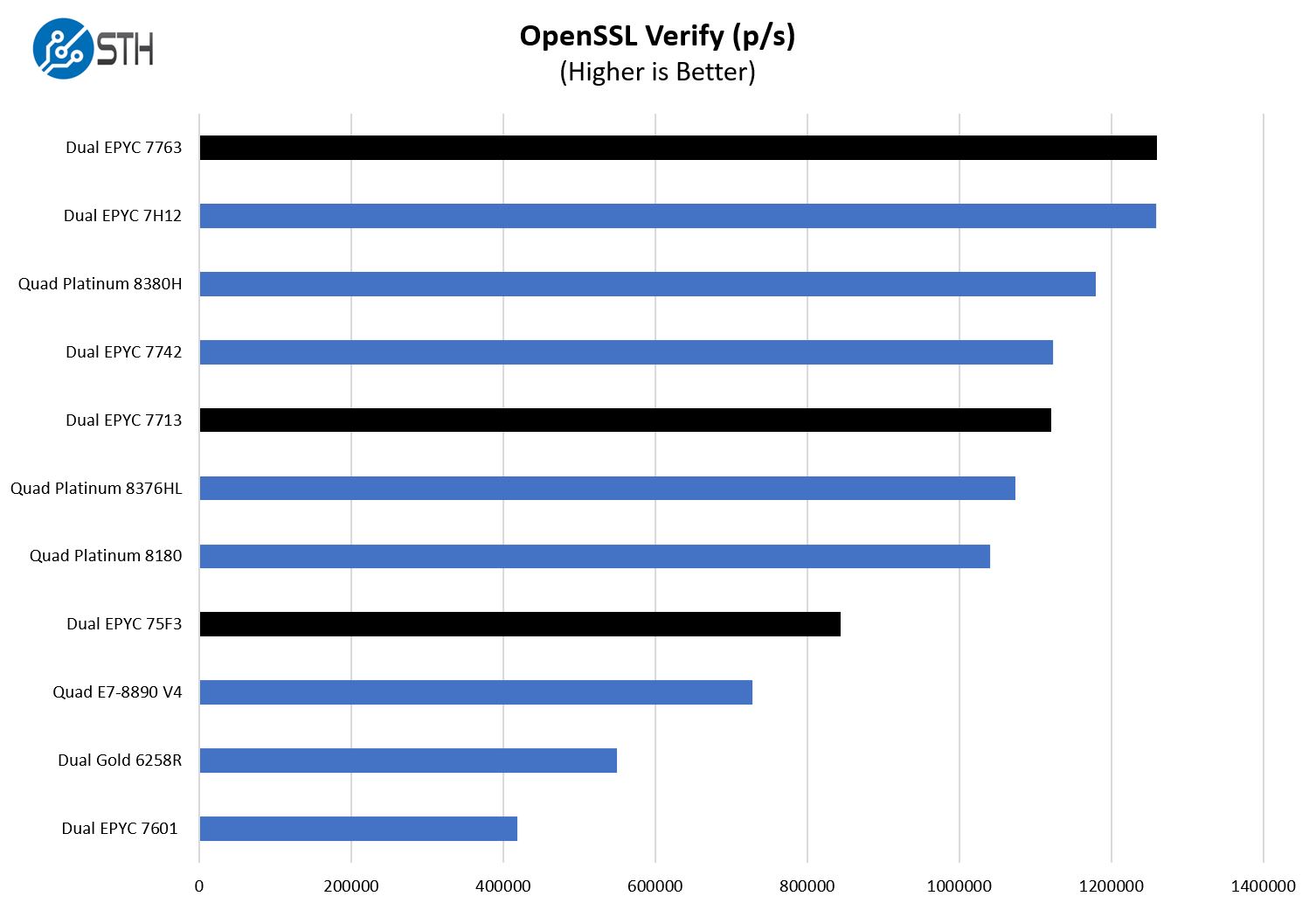
Here again, AMD is competitive with a 2:1 socket consolidation ratio for the Cooper Lake Xeons. If one has an older top-bin 1st Generation Xeon Scalable 8180, then even the EPYC 7713 will allow a greater than 2:1 consolidation ratio on a socket basis. We also see that the EPYC 75F3 is showing well over a 2:1 consolidation ratio over the quad Xeon E7-8890 V4 solution.
Chess Benchmarking
Chess is an interesting use case since it has almost unlimited complexity. Over the years, we have received a number of requests to bring back chess benchmarking. We have been profiling systems and now use the results in our mainstream reviews:
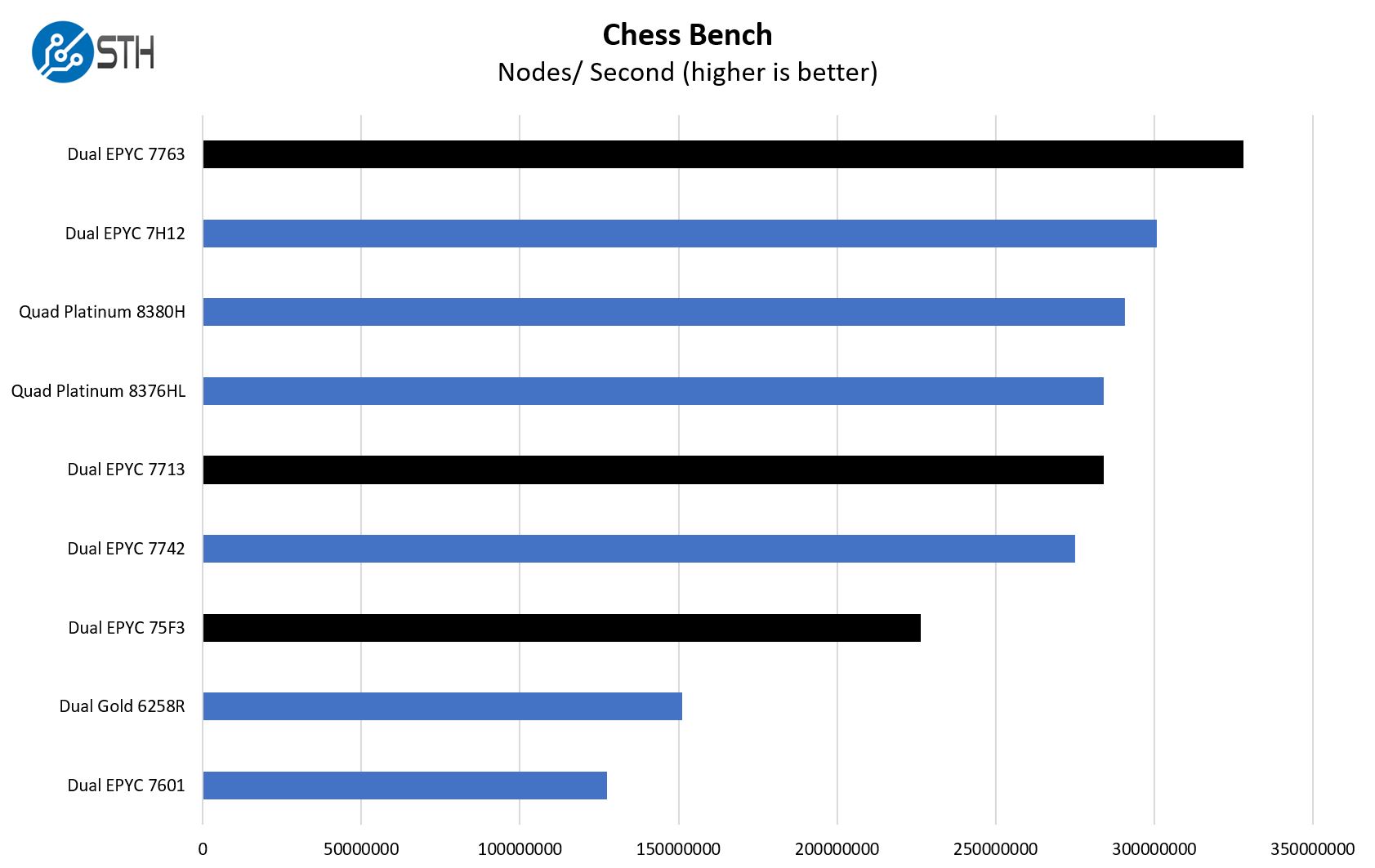
First off, one note here since this uses bmi2. This benchmark will utilize bmi2 or popcnt paths based on which is faster. With the EPYC 7601, it clearly used popcnt since bmi2 was a non-starter, as with many low-end Pentium/ Celeron CPUs on the consumer side. With the EPYC 7002 generation, bmi2 would run, but the popcnt performance would be higher than the bmi2 result. Generally, Xeon has run faster with bmi2 for some time. With Zen3 and the EPYC 7003 series, bmi2 is faster than the popcnt which represents a major performance improvement.
For us, this is a fun result because we are seeing an evolution from not working, to working, to optimized results in successive generations of CPUs.
MariaDB Pricing Analytics
This is a personally very interesting one for me. The origin of this test is that we have a workload that runs deal management pricing analytics on a set of data that has been anonymized from a major data center OEM. The application effectively is looking for pricing trends across product lines, regions, and channels to determine good deal/ bad deal guidance based on market trends to inform real-time BOM configurations. If this seems very specific, the big difference between this and something deployed at a major vendor is the data we are using. This is the kind of application that has moved to AI inference methodologies, but it is a great real-world example of something a business may run in the cloud.
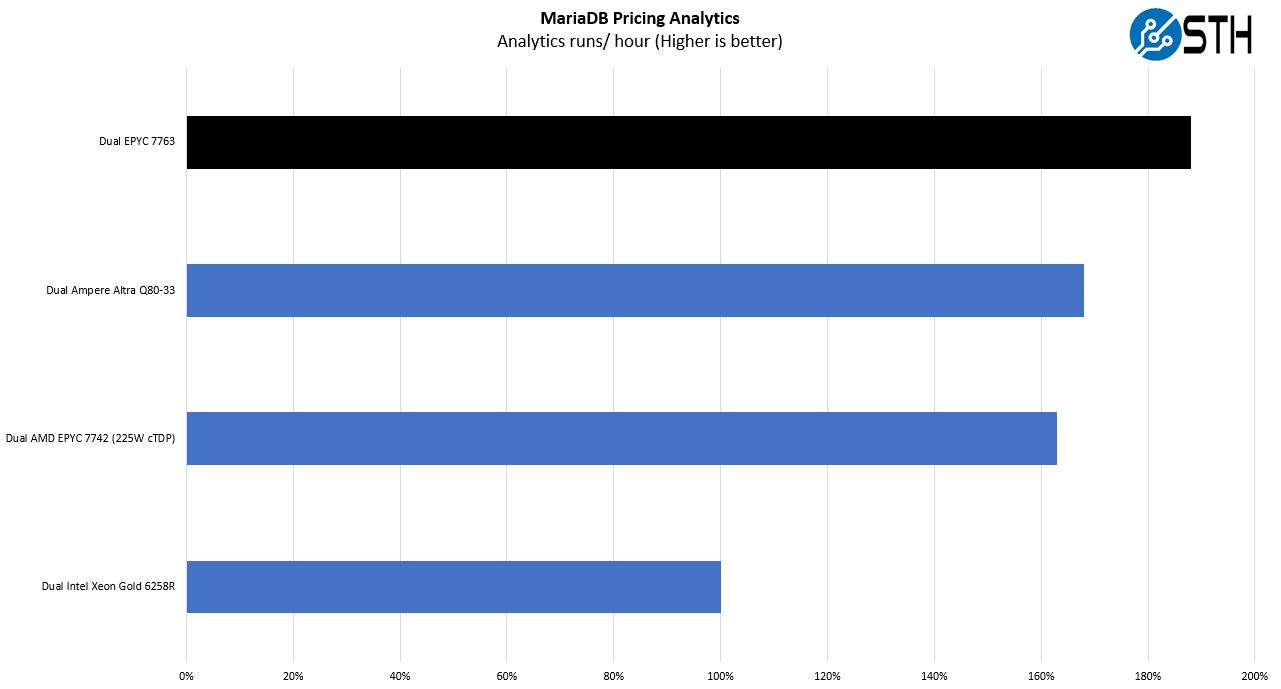
We wanted to push some higher-end results using the top-end standard 2P SKUs. Here we removed the 2P results and one can see that Milan offers an impressive performance boost. This is more of a real-world application rather than a micro-benchmark so we see a solid gain, but not what we have seen in the smaller benchmarks. This is a ~100GB dataset so it cannot fit within the 256MB L3 cache.
STH nginx CDN Performance
On the nginx CDN test, we are using an old snapshot and access patterns from the STH website, with DRAM caching disabled, to show what the performance looks like fetching data from disks. This requires low latency nginx operation but an additional step of low-latency I/O access which makes it interesting at a server-level. Here is a quick look at the distribution:
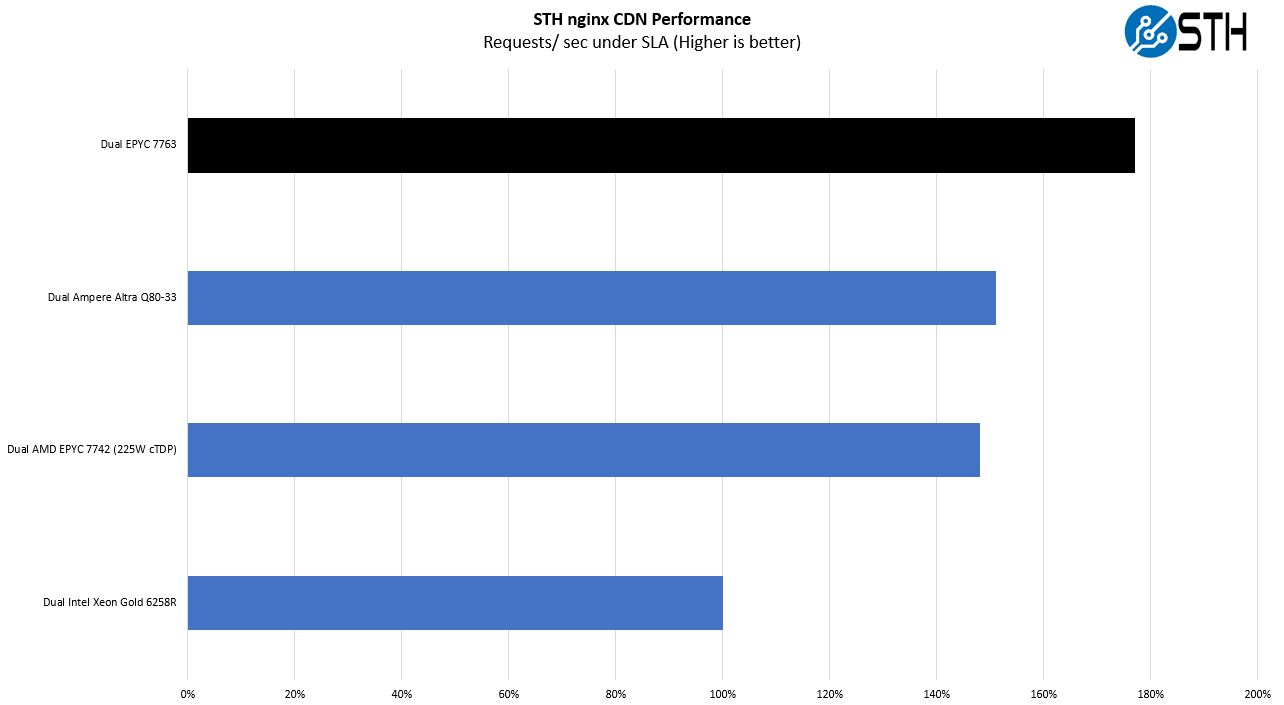
Again, higher clock speeds help here, but we also get great performance testing more than just CPU performance.
As a quick tip here, we have heard that pairing the AMD EPYC 7763 with the new Intel Optane P5800X PCIe Gen4 SSD is becoming an exciting combination. We are considering something like this for our next-next gen hosting nodes. Even without the new drives, this is an impressive performance and well beyond what we are using in our actual hosting environment.
STH STFB KVM Virtualization Testing
One of the other workloads we wanted to share is from one of our DemoEval customers. We have permission to publish the results, but the application itself being tested is closed source. This is a KVM virtualization-based workload where our client is testing how many VMs it can have online at a given time while completing work under the target SLA. Each VM is a self-contained worker.
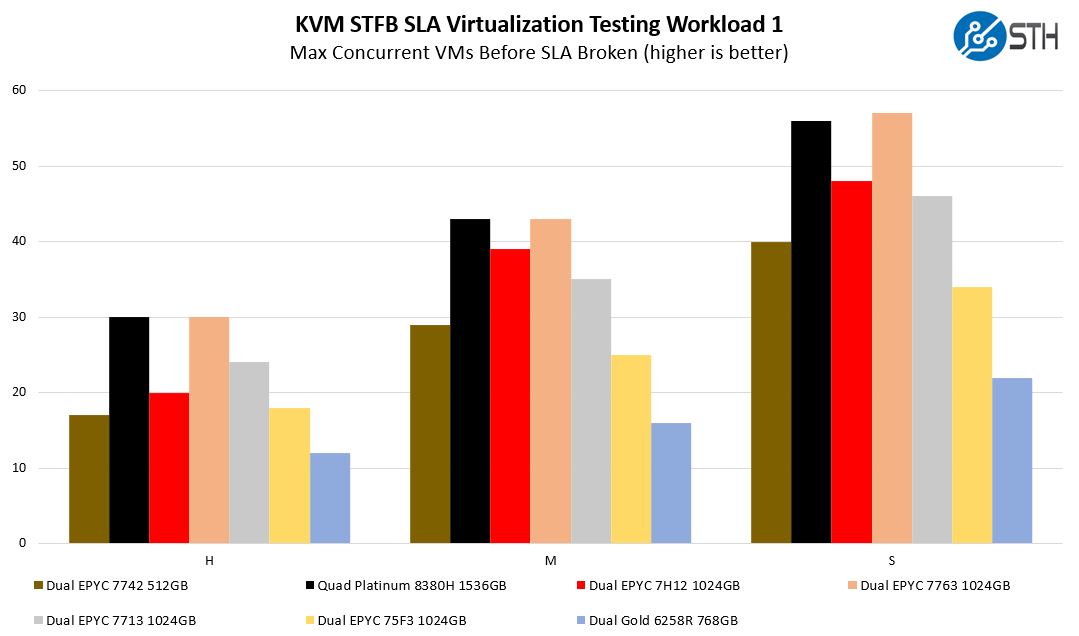
This result is very cool. Specifically, we wanted to draw your attention to the high and medium results. One can see here the 4P Cooper Lake topology does very well, but there is a more important change. The EPYC 7H12 to EPYC 7763 / 7713 relationship changes. As the VMs get larger, we start getting more cases of crossing the CCX domains on Rome which hurt performance. With Milan, and the larger 8 core / 32MB CCX, we see the platform is able to host more VMs before the SLA is broken. This is a huge deal, and not something that is readily apparent with microbenchmarks.
One can argue that micro-benchmarks are purer since they are testing one type of application/ operation, however, realistically many of the 64 core CPU nodes are going to be virtualized or running containers. At this core count, one almost wants to run different workloads just to fully utilize the hardware.
SPECrate2017_int_base
The last benchmark we wanted to look at is SPECrate2017_int_base performance. Specifically, we wanted to show the difference between what we get with Intel Xeon icc and AMD EPYC AOCC results and across a few generations.
Server vendors get better results than we do, but this gives you an idea of where we are at in terms of what we have seen:
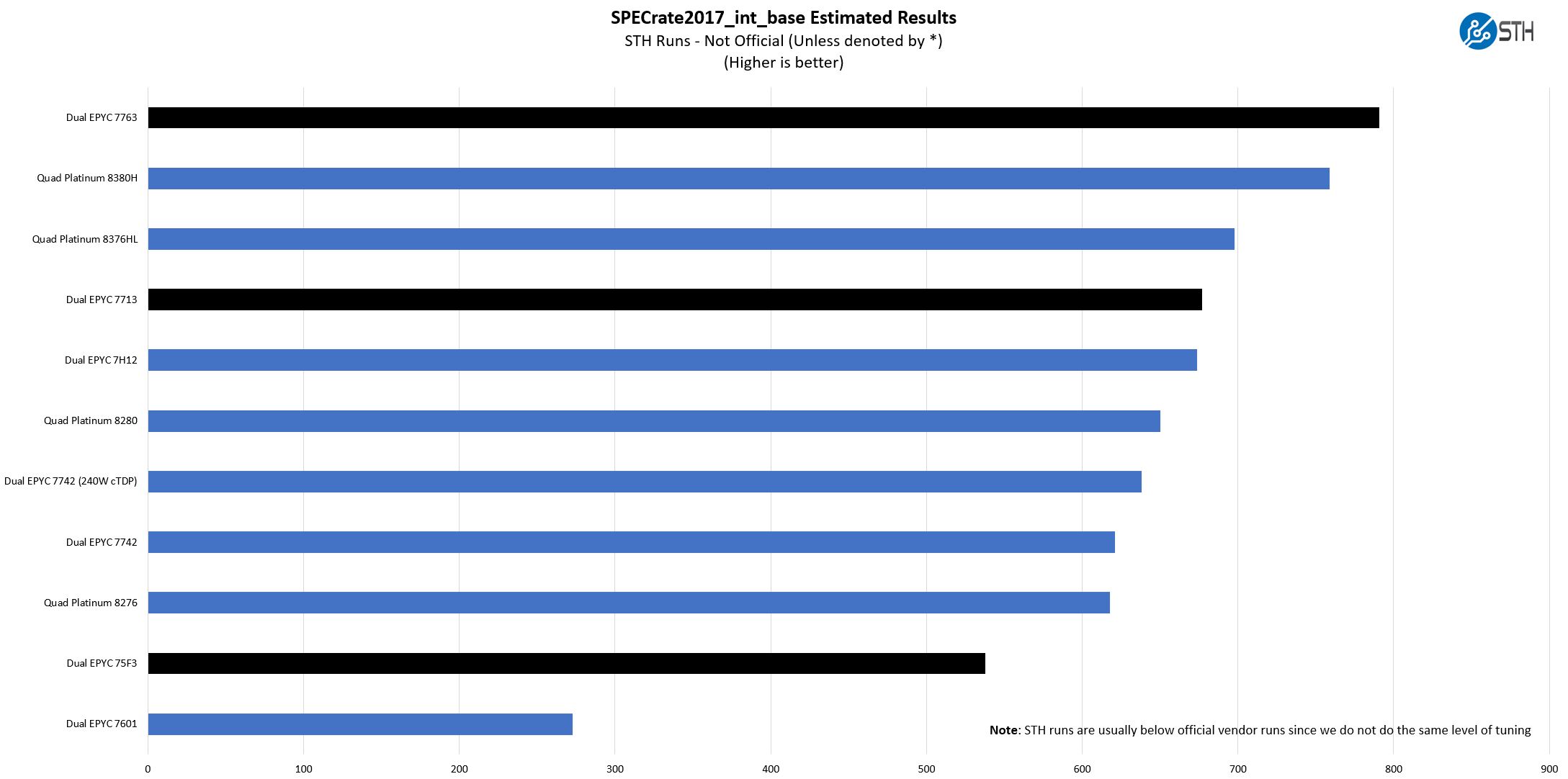
We are slightly behind AMD’s guidance here, but within a few percent. Realistically, our micro-benchmark suite test many of the same functions as we are testing here, so we see a similar ballpark of results. Perhaps the result that is most interesting is our legacy EPYC 7601 result. There may not have been a good reason to upgrade from the 2017 Intel Xeon Scalable generation to the current generation, but the gains between the EPYC 7601 and EPYC 7763 are such that one can legitimately have conversations on retiring the legacy systems and replacing them with newer larger Milan nodes.
A few quick and important notes here:
- These are not vendor official results. For official results, see the official results browser.
- We are often behind vendor results. So please look up official results, for RFP purposes. Vendors do more to get to extremely tight tunings for their official runs, so ours are comparable only to STH results, not the official data set.
Still, this should give some sense of overall performance.
A Note on Power Consumption
We typically do power consumption in shipping platforms. With modern servers, cooling, and peripherals have an enormous impact on power consumption. To get reliable power numbers, one must have servers sitting on the top and bottom of systems and run heat soaked burn-ins. In a real data center, having heat sources above and below a server is common when racked. Just given that, we did not have time to do our official runs as we did with the Gigabyte R292-4S1 Server Review. Still, we wanted to give some sense of where we are comparing the EPYC 7763 to the quad Intel Xeon 8380H’s that are close in performance.

In the AMD Daytona platform, we saw typical 100% workloads in the 900-950W range. We would compare this to the 1.6-1.65kW figure on the 4-socket platform, albeit that had more memory.

AMD clearly has a power consumption advantage at the top-end of the spectrum. It is very efficient for AMD to add 8 core CCDs to the Milan CPU to get more cores per watt.
There is a part of this story that is the low-end, or lack thereof for AMD. The AMD EPYC 7313 is a 16 core 155W TDP part and the lowest TDP part of the EPYC 7003 series. In contrast, AMD had at least eight parts in the 120-155W range with the EPYC 7002 series. AMD is retaining these low-end parts, but it is doing something else, it is effectively ceding the low power per socket market.

It seems the Milan I/O die is using enough power that realistically AMD would struggle to make a viable sub 100W part to compete with the Intel Xeon Bronze 3206R or something in the low-end Xeon Silver range.
AMD’s answer is simple: use a 1P server instead of 2P lower-end SKUs. Still, in Milan the lowest-cost part is the AMD EPYC 7313P at $913. That means the current Intel Bronze, Xeon Silver, and even some Xeon Gold parts are in direct competition in the $900-1000 range or less. If one just needs to “light the platform” to bring a few hard drives online, then AMD effectively has no answer with Milan. This is the gaping hole in the line that Rome parts are meant to partly fill.
Networking Performance Check 200GbE is Here
When we looked at previous generation systems, we have used 100GbE as our basis to see how fast the networking out of a system can get. Now, we have 200GbE NVIDIA Mellanox ConnectX-6 NICs capable of 200GbE per port.

We hooked these into two AMD platforms each with a pair of EPYC 7763’s (more on platforms on the next page) and we saw excellent performance of around 195Gbps. That is slightly lower than we expected, but we also did not spend a lot of time tuning. Still, we were within 3% of 200Gbps so that was excellent.
Overall here, we can see ultra-fast per-port connectivity. We think most servers with higher than 1/10GbE networking in this generation will use 25GbE/ 100GbE but we wanted to show that this was possible. With some of the older Arm solutions, we noticed that they were struggling to keep line rate. Now we just need to figure out how to get a 400GbE switch for the lab like the Inside an Innovium Teralynx 7-based 32x 400GbE Switch we just got hands-on time with:
Hitting this amount of traffic is no easy feat. 200GbE is not something that can be driven out of a single PCIe Gen3 x16 slot (although there are multi-host adapters) so this is currently a differentiator for AMD until Intel Ice Lake Xeons launch.
Next, we are going to take a look at some of the partner platforms before we get to a discussion on Ice Lake Xeons which we could not show the performance of, but we will discuss what is public about them.



{kind=link}
Any reason why the 72F3 has such conservative clock speeds?
The 7443P looks as if it will become STH subscriber favorite. Testing those is hopefully prime objective :)? Speed, per core pricing, core count – there this CPU shines.
What are you trying to say with: “This is still a niche segment as consolidating 2x 2P to 1x 2P is often less attractive than 2x 2P to 1x 2P” ?
Have you heard co.s are actually thinking of EPYC for virtualization not just HPC? I’m seeing these more as HPC chips
I’d like to send appreciation for your lack of brevity. This is a great mix of architecture, performance but also market impact.
The 28 and 56 core CPUs are because of the 8-core CCXs allowing better harvesting of dies with only one dead core. Previously, you couldn’t have a 7-core die because then you would have an asymmetric CPU with one 4-core CCX and one 3-core CCX. You would have to disable 2 cores to keep the CCXs symmetric. Now with the 8-core CCXs you can disable one core per die and use the 7-core dies to make 28-core and 56-core CPUs.
CCD count per CPU may be: 2/4/8
Core count per CCD may be: 1/2/3/4/5/6/7/8
So in theory these core counts per CPU are possible: 2/4/6/8/10/12/14/16/20/24/28/32/40/48/56/64
I’m wondering if we’re going to see new Epyc Embedded solutions as well, these seem to be getting long in the tooth much like the Xeon-D.
Is there any difference between 7V13 and 7763?
Comments are closed.