
At Intel Architecture Day 2021 we got a real treat. Specifically, we got to see the 2022 generation of Intel Xeon CPUs dubbed “Sapphire Rapids.” The new generation of chips will finally bring Intel’s mainstream server CPUs into the multi-die era. Intel will go from being a laggard on PCIe Gen4 and DDR4-3200 adoption to again moving at the industry pace for adopting key technologies such as DDR5 and PCIe Gen5. What is more, this will have an option to have onboard HBM further expanding capabilities. Let us get into it.
Sapphire Rapids High-Level Overview
Intel first discussed the improvements from today’s Ice Lake to tomorrow’s Sapphire Rapids at both a node and a data center level. At a node level, it focused on a number of new features, many of which we have covered previously such as new cores, more cores, DDR5, PCIe Gen5, CXL, and larger caches.

Intel also stated that its chips have technologies such as better telemetry and accelerators that will help them operationally run well in cloud and multi-tenant environments. Intel is calling this the “data center” performance.

Sapphire Rapids is where Intel will go full “glue” on its server CPUs. I was in the room during the Skylake workshop when the now-famous slide was shown accusing AMD of using “glue” to make CPUs.

Now Intel is changing its tune, and something is really interesting here. Intel’s approach is actually reminiscent of AMD’s Naples generation, just a lot fancier. Like Naples, we get four dies each with a full set of features. Unlike AMD’s 2017 implementation, everything is faster and the interconnect uses the higher-end EMIB technology. Intel says this approach provides more monolithic die-like performance yet with the benefits of multi-die.

Sapphire Rapids is unlikely to reclaim the core count crown over AMD’s Genoa offering. As a result, Intel took a page from the consumer playbook and cited how industry-standard benchmarks such as SPECint are not representative of CPU performance. There is some merit to this, especially on the server-side since a multi-tenant environment is a lot different from a perfectly scalable single application environment. Still, we are just going to point that out as we get into this. Intel is doing a bit of posturing in its disclosure.
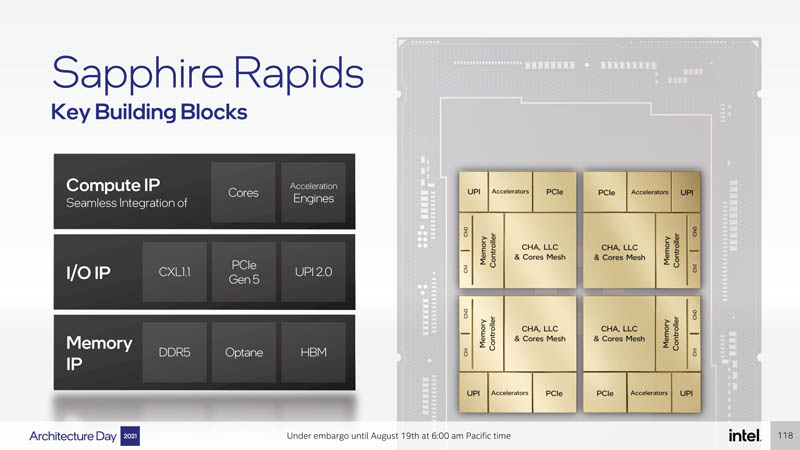
Intel Xeon Sapphire Rapids SoC Architecture
As one can see, we have four primary dies that each have cores, cache, memory controllers, I/O, accelerators, and interconnect. Intel did a deep dive in a number of these areas.

Intel buckets Sapphire Rapids IP into three main types of IP related to compute, I/O, and memory.
On the core side, we are going to do a bit of a deeper dive into Golden Cove, Intel’s high-performance core, along with Gracemont the company’s efficient core in the coming days. Effectively Intel is improving performance by over 15% on the desktop side with a wider architecture and a number of enhancements. An example that can be seen below, and that is different than the consumer Golden Cove, is the 2MB L2 cache per core. Intel is getting into the cache game in a big way so we expect Sapphire Rapids with over 100MB of L2 cache in 2022. This will help to keep cores fed with data so they do not sit idle.

Aside from the raw core upgrades, we are getting some feature upgrades such as matrix acceleration (primarily for AI) via Intel AMX. We will let you read through the list below.

On the acceleration engines side, Intel has a number of accelerators that will help with multi-tenant and multi-application architectures. A key theme in the industry for years has been adding more accelerators to constantly free up tasks that consume CPU cycles.

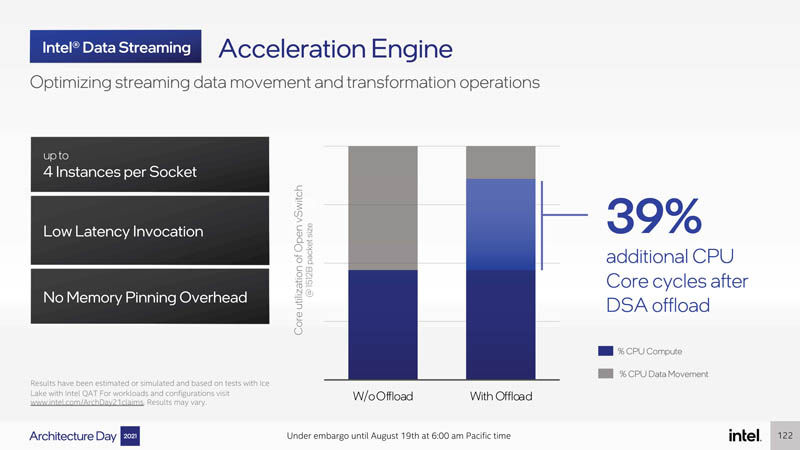
An acceleration engine example is Intel DSA for data streaming. Intel DSA is designed to unload some of the work for data movement and transformation from CPUs and onto accelerators.
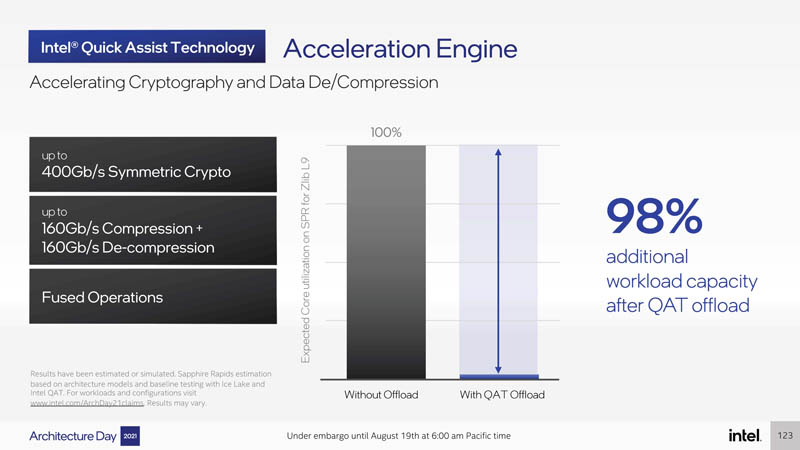
At STH we have been working with Intel QuickAssist Technology for years. With this generation, we get a 400Gbps crypto part. This has come a long way since 2013’s Intel Atom C2000 Rangely. 98% may seem like a huge improvement here, but it is basically the impact of moving a workload to a dedicated accelerator.
On the I/O side, we get a large number of enhancements. We get PCIe Gen5 and can expect more lanes than the 128 that we have today. With PCIe Gen5 we also will get CXL 1.1. We just covered the Intel Hot Interconnects 2021 CXL Keynote and have a Compute Express Link or CXL What it is and Examples piece. We also get UPI 2.0 with up to 4×24 UPI links at 16GT/s. This is important. Intel is likely assuming that AMD will continue scaling Infinity Fabric atop PCIe gains. As a result, AMD’s inter-socket Infinity Fabric bandwidth would effectively double as it moves from Gen4 to Gen5 without any other changes. UPI needed an upgrade after largely stagnating over the past few years with minor upgrades.
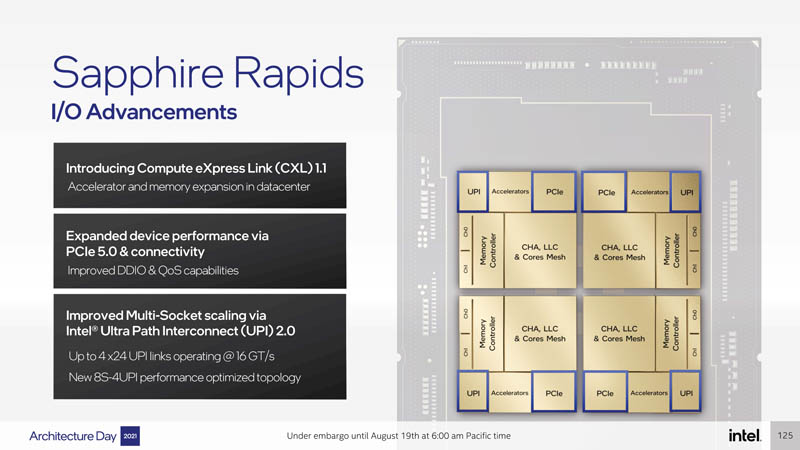
A quick one here is that with each die having UPI that gives four UPI termination points. As a result, we can see that Intel also has an 8 socket 4 UPI topology it is disclosing with the next generation. Ice Lake is dual-socket while Cooper Lake is 4S/8S. Sapphire will help to unify the line again.
Given the fact we expect to see 100MB+ of L2 cache Intel saying it will have 100MB+ of LLC is not a surprise. It will use EMIB to help efficiently and performantly share this cache among cores. We also get 8-channel DDR5 and each die has a memory controller with two channels. Incidentally, AMD EPYC 7001 had eight memory channels with two per die as well.
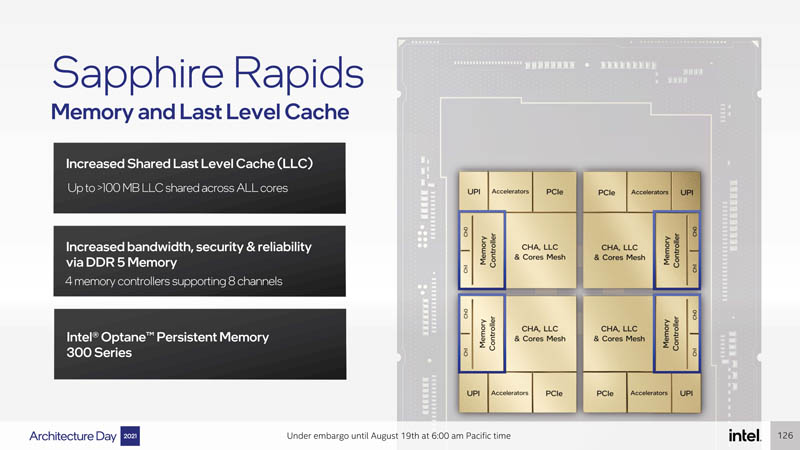
Intel is also signaling support for Optane DIMMs with the mention of the Optane Persistent Memory 300 generation.
Perhaps the cool one, but one that Intel already disclosed, is that Sapphire Rapids will have a HBM option. HBM is too expensive to put on all CPUs so this will be an option. As we saw with Knights Landing (Xeon Phi x200) the HBM will be capable of being used either as its own memory or as a cache for other memory.
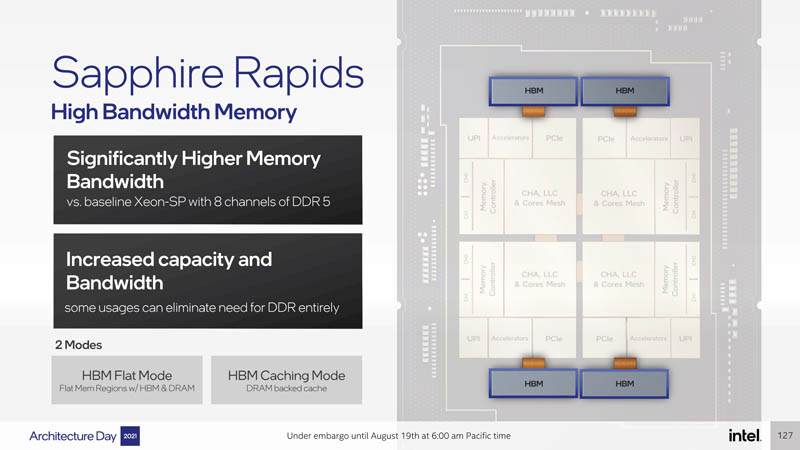
If you read our Server CPUs Transitioning to the GB Onboard Era this HBM announcement should know that getting more on-package memory capacity is going to be a focus in 2022.
Since this will be a 2022 CPU, we get AI acceleration. Using AI inferencing to effectively use estimates instead of doing computationally expensive tasks is continually becoming more practical. As a result, Intel needs to increase AI capabilities for its customers. Likewise, this is something that AMD needs to start doing in its CPUs as by 2022 this will be a larger component of the data center compute requirements.

Using EMIB versus a PCB bridge means that Intel is able to push higher bandwidth and lower latency helping with its QoS. That combined with its other accelerators and features like telemetry for cloud providers means that Intel is now marketing its CPUs for microservices.

We already knew quite a bit of this, but it was nice to get new disclosures in a nice package here.
Final Words
In 2022, AMD will be executing with the EPYC 7004 “Genoa” generation of much larger CPUs. Intel with Sapphire Rapids will have a more competitive part in the market but it is doing so with a bit more finesse with all of its acceleration technologies and fancier EMIB “glue”. Hopefully, by now, our readers will have a sense of why our Ice Lake Xeon launch piece was called Intel Xeon Ice Lake Edition Marks the Start and End of an Era.
By the time Ice Lake launched in Q2 2021, we knew that Sapphire Rapids would be a top-to-bottom upgrade. Hopefully, this piece shows a bit about why that is the case.

Overall, jesting on the “glue” aside (again, EMIB is vastly superior to Naples PCB interconnect) this is a huge upgrade. Hopefully, our readers will have a sense that with solid double-digit expected IPC improvement, more cores, more PCIe lanes, PCIe Gen5, CXL, DDR5, more acceleration, and even a HBM option, Sapphire Rapids is a top-to-bottom redesign of how Xeons are built. The reason we have been running a Planning for Servers in 2022 and Beyond Series over the past few months is to help our readers understand that big changes are coming.



{kind=link}
Regarding your Final words, just a small correction: Genoa = 7004.
Thanks Hetz. 2AM!
The war of the glue has begun.
Not bad, an improvement. However it looks like four NUMA domains and nonunified cache. Intel leaving itself room for improvements next iteration or it just ordered Lepages White Glue when it meant to order cyanoacrilyte Superglue?
Intel is using EMIB to connect the tiles instead of basic on package wiring like AMDs now old Naples.
These four Tiles are one Mesh Network like one big Skylake-SP.
Comments are closed.