
With the launch of the 3rd Generation Intel Xeon Scalable codenamed “Ice Lake” we start a new era for Intel in an awkward fashion. Intel has undoubtedly delivered a massive jump in performance. Indeed, this is likely the biggest architectural leap for Intel since the 2012 Intel Xeon E5-2600 V1 “Sandy Bridge” generation. At the same time, Intel’s messaging around this launch and the timing feels awkward since it also marks the end of an era for Intel. In this article, we are going to discuss some background on the third-generation Intel Xeon Scalable. We are then going to discuss what Intel is launching before we get into our performance discussion. Finally, we are going to get into the market impact section and discuss why this is really an end to an era for Intel.
The Accompanying Video
This is a quick update, we are going to link the video for this one which took a bit longer to process and did not make it for the embargo.
As always we have more detail in the written version, but we know some folks like to listen along. Feel free to open this is in a new YouTube tab for a better viewing experience.
What is the Third Generation Intel Xeon Scalable Scalable?
In this article, we are going to refer to the new chips as “Ice Lake”. When you read marketing materials from vendors, you are likely to see the product descriptor “3rd Generation Intel Xeon Scalable.” Today, April 6, 2021, is not the launch of the 3rd Gen Xeon Scalable. It is the launch of a 3rd Generation Xeon Scalable codenamed Ice Lake.
The third generation technically launched almost 10 months ago with “Cooper Lake”. This will undoubtedly cause confusion in the industry, so we wanted to provide some background about how we got to a situation where Intel is launching something with a similar name yet a completely different set of capabilities 10 months later.

Since this is a long article, we are going to make it easy for our readers:
- Cooper Lake – 1P to 8P scalability, driven by in-memory databases and Facebook
- Ice Lake – 1P and 2P mainstream series, this is what is launching today and will carry the mainstream market
To understand what is causing this naming convention challenge, that could be fixed if Intel had just called this the 4th Generation Intel Xeon Scalable, we have to get a bit of background.
The Odyssey of Ice Lake
If you have never read Homer’s Odyssey, it is a story of Odysseus trying to return home over 10 years. For Intel, this is a long journey to launch a 10nm part that may have involved more people and analogous trials and tribulations. Depending on which version of Intel’s roadmap you look at, Ice Lake was set to be Intel’s 10nm part in 2018 or 2019 at the end of a long journey to bring a new process and microarchitecture to its products.

By December 2018, Intel was fully enveloped in 10nm process challenges. The company showed off Ice Lake at Intel Architecture Day 2018, but manufacturing for the chips was still not where it needed to be.

Even as the 3rd Generation Intel Xeon Scalable launched in Q2 2020, this is the roadmap Intel shared showing Ice Lake in the Whitley platform in 2020. It is now Q2 2021 and we are seeing the launch of Ice Lake.

The point is, and let us be completely clear, Ice Lake is massively delayed. The key issue was the 10nm manufacturing node performance and yield. Intel has managed to largely overcome the challenge, but during three (or more) years of delay, the world effectively changed for Intel.
The World Changes During the Journey
When the AMD EPYC 7001 series launched in mid-2017 followed by the 1st Generation of Intel Xeon Scalable chips, codenamed “Skylake” Intel had a virtual monopoly on server chips. The AMD EPYC 7001 series was a good first attempt, but it was far from where AMD needed to be. What the EPYC 7001 did was simply to show the market that there was a new player, and get server OEMs comfortable with the idea of having a non-Intel x86 platform.

Early in 2018, we had news of Spectre and Meltdown. This put Intel into an interesting position. It had not delivered Optane DC Persistent Memory after pulling support from Skylake relatively late in the cycle. Also, Intel found that its chips had a higher level of susceptibility to this new class of attacks. At the same time, it was becoming apparent that Ice Lake was not launching in 2018/ early 2019. As a result, Intel revised Skylake with a few new features such as VNNI, Optane Persistent Memory support, and speculative execution mitigations. This revision became Cascade Lake launched about two years ago in 2019.
In 2019, the competitive balance shifted. Intel finally delivered its 3D XPoint Optane DC Persistent Memory, now called PMem 100, with Cascade Lake, but the 2nd Generation Intel Xeon Scalable was largely still Skylake. Intel still had 6-channel memory, DDR4-2933, 96x PCIe Gen3 lanes, and up to 28 cores while the rest of the industry started to move to a new level.

By July 2019, the AMD EPYC 7002 “Rome” series came out. Even by the time Cascade was launched in April, we knew AMD was going to have a bigger system:
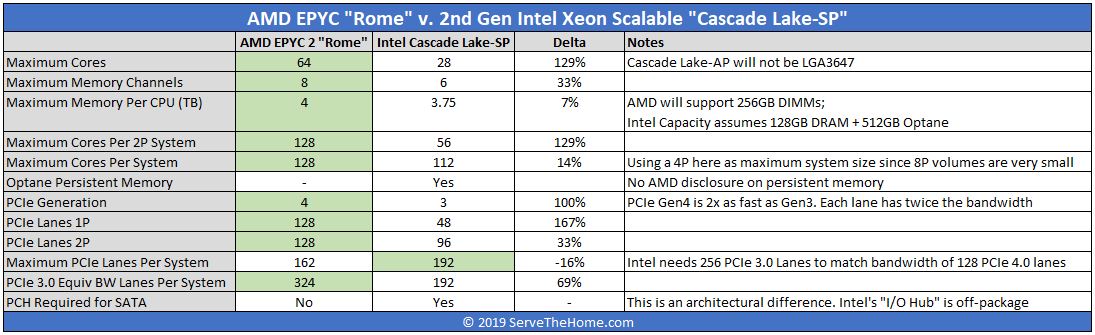
The AMD EPYC 7002 series was a wake-up call to those looking to buy servers. AMD had a second-generation Intel alternative that was bigger. It was not 10% bigger either, it simply had more capacity per socket than Intel had, and it was not even close.

Some may have wondered how this happened. The easy explanation is that 10nm was so far behind that Rome was targeted at Ice Lake. These chips and platforms have long development cycles so by the time Rome was launching, Intel would not have Ice Lake for another almost two years.
The Journey Almost Complete and the Need to Compete
In 2020, the market was taking notice. While Intel downplays AMD’s share gains, the fact is that to remain competitive Intel went from a posture of low discounts for general customers to cutting prices by ~60% with its Big 2nd Gen Intel Xeon Scalable Refresh. Intel has been subsidizing the shift to the cloud for years by offering massively discounted pricing to cloud providers while it was virtually a monopoly. Top-end SKUs that one may purchase from Dell or HPE at $10K+ before discounting, would often sell to hyper-scalers for under $2000. A major driving force for cloud economics is that Intel has subsidized its Xeon margins though selling less capable and more expensive chips to the enterprise/ SMB market.

Depending on how one views it, AMD either got lucky that Ice Lake did not launch on time, or it was fortunate that TSMC and its multi-chip architecture delivered. AMD ended up in 2019 with a platform designed to compete with what Intel is launching today. There was an interim period though where Intel was not planning to have Ice Lake and Rome compete.
Prior to the Cascade Lake refresh, the plan was for 2020 to be the year of Cooper Lake. There was the 1-8 socket Cedar Island solution that we have started to review (see: Gigabyte R292-4S1 Server Review 2U 4-Socket Cooper Lake) and that Facebook uses (Intel Xeon Platinum 8321HC 26C 88W TDP 1P Xeon D Competitor.) The other Cooper Lake part was designed as a more “EPYC like” solution for the Whitley platform that would be shared with Ice Lake.

In our Installing a 3rd Generation Intel Xeon Scalable LGA4189 CPU and Cooler piece we discuss how both Cooper Lake and Ice Lake share a similar socket with different keying. The Cooper Lake in Whitley line was designed to be used in the platforms that are being launched alongside Ice Lake. Intel used STH to confirm it canceled which we covered in Intel Cooper Lake Rationalized Still Launching 1H 2020. Intel decided to cancel Cooper Lake in Socket P4 and instead focus on cutting pricing on its 2nd Generation parts for 2020.
As one can imagine, sever vendors that had developed Whitley platforms for Cooper Lake then Ice Lake effectively were stuck selling previous-generation Cascade Lake platforms for another year. Some of the back-channel frustration from Intel that has spilled into the public domain stems from this. Imagine investing in designing platforms if you are a server vendor, then having only one generation of CPUs in the sockets instead of two and not being able to bring something new out to the market for another year. That is one of the big reasons we see things like unprecedented coordinated embargo breaks between a big vendor and a small review site. This frustration with Intel rarely gets that public, but the “Cooper Cancel” was a big topic a year ago.
Ice Lake and 10nm largely got to a sellable state but Intel was forced to introduce a new stepping late in the process. As a result, Intel’s early shipment is only around 200,000 units at this point (and STH probably has something like 0.0003% of that.) Based on its 50M Xeon Scalable processors sold figure, it sells over 1M Xeon Scalable CPUs/ month. Production ramps, but realistically we expect to see more Ice Lake in the market by May 2021 although vendors will announce early. The late stepping change meant that wafers still needed to make it through the fab which takes months.

From a competitive standpoint, three weeks ago we saw the AMD EPYC 7003 Milan launch. AMD had the opportunity to deliver a second-generation PCIe Gen4 part before Intel got its Ice Lake Xeon series out.

In the rest of this article, we are going to go into the impacts. There are a few key takeaways we want our readers to remember going through this article:
- Ice Lake is the biggest step forward in Intel’s server architecture since 2012’s Sandy Bridge introduction.
- Due to the delay, Intel is competing with EPYC 7003, not EPYC 7002.
- This is going to be a short-lived platform. Intel’s Sapphire Rapids next-gen platform will bring CXL and PCIe Gen5 along with a new socket.
- After the multi-year/ generation delay due to a monolithic 10nm processor, Intel’s stated direction moving forward is to not sell monolithic die CPUs as it has with Ice Lake. 2021 Intel is telling the market that this is the wrong way to build this class of product, but Ice Lake is a 2019 chip.
Next, we are going to get into these topics, along with how the system performs.



{kind=link}
@Patrick
What you never mention:
The competitor to ICL HPC AVX512 and AI inference workloads are not CPUs, they are GPUs like the A100, Intinct100 or T4. That’s the reason why next to no one is using AVX512 or
DL boost.
Dedicated accelerators offer much better performance and price/perf for these tasks.
BTW: Still, nothing new on the Optane roadmap.it’s obvious that Optane is dead.
Intel will say that they are “committed” to the technology but in the end they are as commited as they have been to Itanium CPUs as a zombie platform.
Lasertoe – the inference side can do well on the CPU. One does not incur the cost to go over a PCIe hop.
On the HPC side, acceleration is big, but not every system is accelerated.
Intel, being fair, is targeting having chips that have a higher threshold before a system would use an accelerator. It is a strange way to think about it, but the goal is not to take on the real dedicated accelerators, but it is to make the threshold for adding a dedicated accelerator higher.
“not every system is accelerated”
Yes, but every system where everything needs to be rewritten and optimized to make real use of AVX-512 fares better with accelerators.
——————
“the inference side can do well on the CPU”
I acknowledge the threshold argument for desktops (even though smartphones are showing how well small on-die inference accelerators work and winML will probably bring that to x86) but who is running a server where you just have very small inference tasks and then go back to other things?
Servers that do inference jobs are usually dedicated inference machines for speech recognition, image detection, translation etc.. Why would I run those tasks on the same server I run a web server or a DB server? The threshold doesn’t seem to be pushed high enough to make that a viable option. Real-world scenarios seem very rare.
You have connections to so many companies. Have you heard of real intentions to use inference on a server CPU?
Even Facebook is doing distributed inference/ training on CPUs. Organizations 100% do inferencing on non-dedicated servers, and that is the dominant model.
Hmmm… the real issue with using AVX-512 is the down clock and latency switching between modes when you’re running different things on the same machine. It’s why we abandoned it.
I’m not really clear on the STH conclusion here tbh. Unless I need Optane PMem, why wouldn’t I buy the more mature platform that’s been proven in the market and has more lanes/cores/cache/speed?
What am I missing?
Ahh okay, the list prices on the Ice Lake SKUs are (comparatively) really low.
Will be nice when they bring down the Milan prices. :)
@Patrick (2) We’ll buy Ice Lake to keep live migration on VMware. But YOU can buy whatever you want. I think that’s exactly the distinction STH is trying to show
I meant for new server application, not legacy like fb.
Facebook is trying to get to dedicated inference accelerators, like you reported before with their Habana/Intel nervana partnerships, or this:
https://engineering.fb.com/2019/03/14/data-center-engineering/accelerating-infrastructure/
Regarding the threshold: Fb is probably using dedicated inference machines, so the inference performance threshold is not about this scenario.
So the default is a single Lewisburg Refresh PCH connected to 1 socket? Dual is optional? Is there anything significant remaining attached to the PCH to worry about non-uniform access, given anything high-bandwidth will be PCIe 4.0?
Would be great if 1P 7763 was tested to show if EPYC can still provide the same or more performance for half the server and TCO cost :D
Sapphire Rapids is supposed to be coming later this year, so Intel is going 28c->40c->64c within a few months after 4 years of stagnation.
Does it make much sense for the industry to buy ice lake en masse with this roadmap?
“… a major story is simply that the dual Platinum 8380 bar is above the EPYC 7713(P) by some margin. This is important since it nullifies AMD’s ability to claim its chips can consolidate two of Intel’s highest-end chips into a single socket.”
I would be leery of buying an Intel sound bite. I may distract them from focusing on MY interests.
Y0s – mostly just SATA and the BMC, not a big deal really unless there is the QAT accelerated PCH.
Steffen – We have data, but I want to get the chips into a second platform before we publish.
Thomas – my guess is Sapphire really is shipping 2022 at this point. But that is a concern that people have.
Peter – Intel actually never said this on the pre-briefs, just extrapolating what their marketing message will be. AMD has been having a field day with that detail and Cascade Lake.
I dont recall any mention of HCI, which I gather is a major trend.
A vital metric for HCI is interhost link speeds, & afaik, amd have a big edge?
Patrick, did you notice the on package FPGA on the Sapphire Rapids demo?
Patrick, great work as always! Regarding the SKU stack: call me cynical but it looks like a case of “If you can’t dazzle them with brilliance then baffle them with …”.
@Thomas
Gelsinger said: “We have customers testing ‘Sapphire Rapids’ now, and we’ll look to reach production around the end of the year, ramping in the first half of 2022.”
That doesn’t sound like the average joe can buy SPR in 2021, maybe not even in Q1 22.
Is the 8380 actually a single die? That would be quite a feat of engineering getting 40 cores on a single NUMA node.
I was wondering about the single die, too. fuse.wikichip has a mesh layout for the 40 cores.
https://fuse.wikichip.org/news/4734/intel-launches-3rd-gen-ice-lake-xeon-scalable/
What on earth is this sentence supposed to be saying?
“Intel used STH to confirm it canceled which we covered in…”
Comments are closed.