A Quick Word on Power
We just want to note here that we typically would use the following for our lab planning based on what we observed under loads with just memory and a single SSD installed.
- Dual Intel Xeon Gold 6330: 700-745W
- Dual Intel Xeon Platinum 8352Y: 725-750W
- Dual Intel Xeon Platinum 8380: 900-950W
We may not have hit maximum power, but these ranges we could hit in different systems and we have confirmed on platforms from at least two vendors.
So the key takeaway here is that technically a dual Xeon Platinum 8380 we would say uses less power than an AMD EPYC 7763. However, at a similar general-purpose performance/ core count level, Intel is using (very) roughly 30-40% more power due to having to scale to additional nodes. AMD also has chips like the EPYC 75F3 which is a high TDP 32-core part.

We did not test the Platinum 8362 which is Intel’s closest competitor
A Challenging View of Performance
We are going to get to this later, but Intel offered an update comparing AMD EPYC 7763 to Xeon platinum 8380. Effectively it is saying that if AMD EPYC 7003 “Milan” parts find data in first or second level caches, AMD will be faster. It then says that if AMD cores can find data in local L3 caches AMD is faster, but if it has to go to remote dies then it is potentially slower.

Likewise, Intel says it has better memory latency.

We just wanted to call this out since our readers may see this on other sites after Intel distributed it. The challenge with this way of thinking is simple. In most AMD EPYC 7003 SKUs, there is 32MB of local L3 cache to any given core. There is additionally up to 256MB of L3 cache per socket and 512MB on full SKUs across both sockets. This 256MB figure can go down, but on the performance SKUs, AMD even has 256MB with 8 cores where each core has a dedicated 32MB of L3 cache.
Saying a cache misses can be slower when AMD has 8 core parts with 256MB of cache and 4MB/ core or more is strange when Intel has a maximum of 60MB L3 cache and that scales down with core counts. Intel’s 8-core parts have 12MB L3 cache with the Gold 6334 at 18MB. Comparing latencies when a single AMD core can have ~2-3x the entire cache of Intel’s 8-core chips seems strange.
That also brings us to the bigger challenge with this mental model. AMD can scale to 128 cores/ system and 160 PCIe Gen4 lanes per system. If Intel-based systems need to scale out to make up these large deficits, then the latency incurred is not local within a box, but the latency of going to the network card, over a cable, to a switch, and then to another node which is an order of magnitude slower. In Intel’s example, cores 1-80 may follow the above, but cores 81-120 would add a hop to an external node, and likely 121-128 would add a hop to an external node plus a cross socket hop.
With microbenchmarks, the model Intel offers can make some sense, but it is comparing AMD’s chips designed to have a bigger radix which is the true value.
Intel also offers that it has new instructions which is fair.
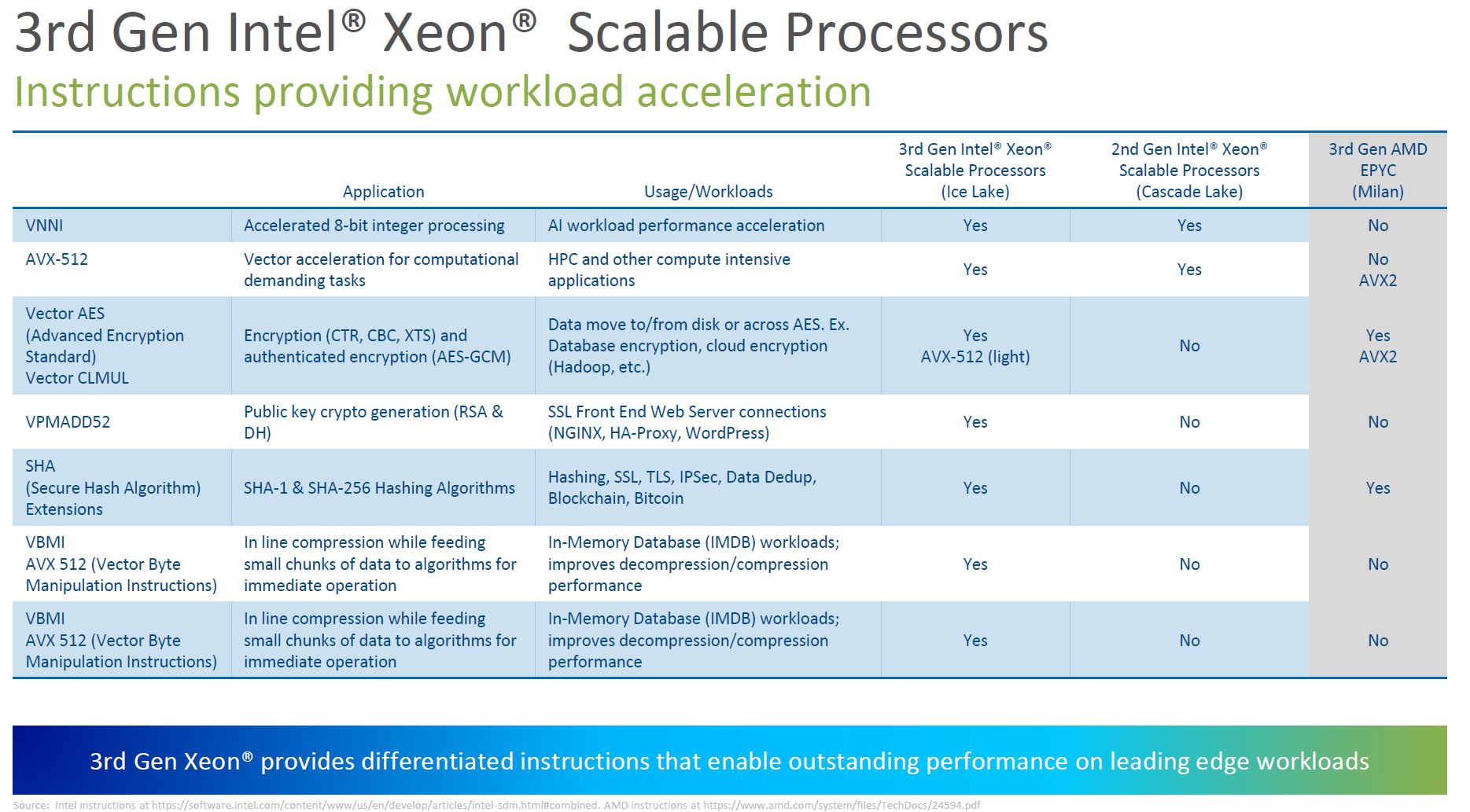
We are going to note that the “Blockchain, Bitcoin” may be fair, but AMD EPYC CPUs are far superior for CPU-based miners that currently utilize even AVX-512 (and it is not close.)
On the HPC, Cloud, and AI performance, we can see that Intel is focused on comparisons where it is using AVX-512, DL boost, and crypto accelerators.
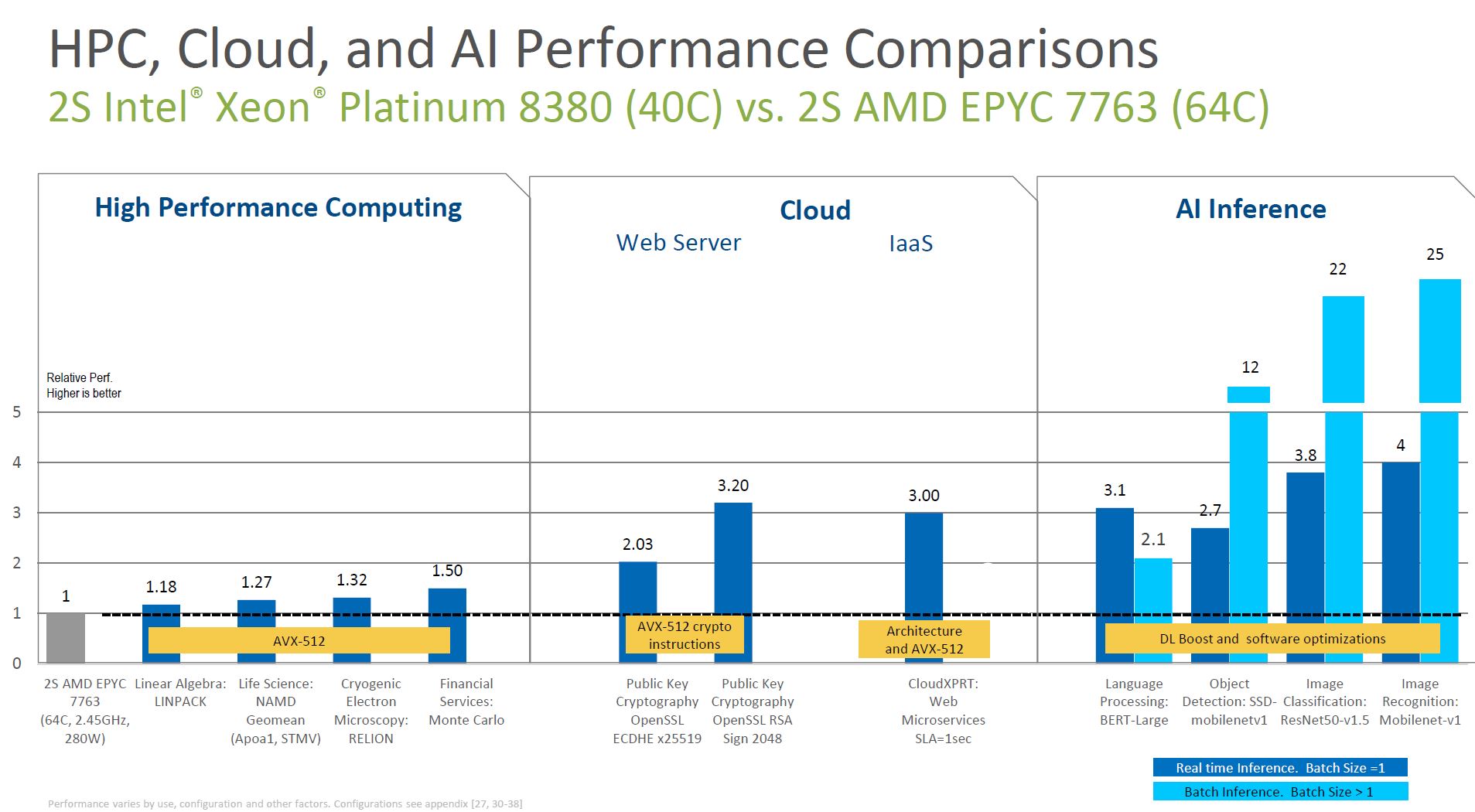
Again, if one is not changing to utilize accelerators, then the story flips so one must keep that in mind. CloudXPRT one can see is being accelerated by AVX-512. That is a benchmark that is created by Principled Technologies which Intel funds. Workloads such as NGINX work (very) well on Arm processors that do not have AVX-512 and are a key reason that cloud providers are designing their own Arm chips or using those from Ampere.
Next, we are going to discuss the market impact, followed by our final words.


{kind=link}
@Patrick
What you never mention:
The competitor to ICL HPC AVX512 and AI inference workloads are not CPUs, they are GPUs like the A100, Intinct100 or T4. That’s the reason why next to no one is using AVX512 or
DL boost.
Dedicated accelerators offer much better performance and price/perf for these tasks.
BTW: Still, nothing new on the Optane roadmap.it’s obvious that Optane is dead.
Intel will say that they are “committed” to the technology but in the end they are as commited as they have been to Itanium CPUs as a zombie platform.
Lasertoe – the inference side can do well on the CPU. One does not incur the cost to go over a PCIe hop.
On the HPC side, acceleration is big, but not every system is accelerated.
Intel, being fair, is targeting having chips that have a higher threshold before a system would use an accelerator. It is a strange way to think about it, but the goal is not to take on the real dedicated accelerators, but it is to make the threshold for adding a dedicated accelerator higher.
“not every system is accelerated”
Yes, but every system where everything needs to be rewritten and optimized to make real use of AVX-512 fares better with accelerators.
——————
“the inference side can do well on the CPU”
I acknowledge the threshold argument for desktops (even though smartphones are showing how well small on-die inference accelerators work and winML will probably bring that to x86) but who is running a server where you just have very small inference tasks and then go back to other things?
Servers that do inference jobs are usually dedicated inference machines for speech recognition, image detection, translation etc.. Why would I run those tasks on the same server I run a web server or a DB server? The threshold doesn’t seem to be pushed high enough to make that a viable option. Real-world scenarios seem very rare.
You have connections to so many companies. Have you heard of real intentions to use inference on a server CPU?
Even Facebook is doing distributed inference/ training on CPUs. Organizations 100% do inferencing on non-dedicated servers, and that is the dominant model.
Hmmm… the real issue with using AVX-512 is the down clock and latency switching between modes when you’re running different things on the same machine. It’s why we abandoned it.
I’m not really clear on the STH conclusion here tbh. Unless I need Optane PMem, why wouldn’t I buy the more mature platform that’s been proven in the market and has more lanes/cores/cache/speed?
What am I missing?
Ahh okay, the list prices on the Ice Lake SKUs are (comparatively) really low.
Will be nice when they bring down the Milan prices. :)
@Patrick (2) We’ll buy Ice Lake to keep live migration on VMware. But YOU can buy whatever you want. I think that’s exactly the distinction STH is trying to show
I meant for new server application, not legacy like fb.
Facebook is trying to get to dedicated inference accelerators, like you reported before with their Habana/Intel nervana partnerships, or this:
https://engineering.fb.com/2019/03/14/data-center-engineering/accelerating-infrastructure/
Regarding the threshold: Fb is probably using dedicated inference machines, so the inference performance threshold is not about this scenario.
So the default is a single Lewisburg Refresh PCH connected to 1 socket? Dual is optional? Is there anything significant remaining attached to the PCH to worry about non-uniform access, given anything high-bandwidth will be PCIe 4.0?
Would be great if 1P 7763 was tested to show if EPYC can still provide the same or more performance for half the server and TCO cost :D
Sapphire Rapids is supposed to be coming later this year, so Intel is going 28c->40c->64c within a few months after 4 years of stagnation.
Does it make much sense for the industry to buy ice lake en masse with this roadmap?
“… a major story is simply that the dual Platinum 8380 bar is above the EPYC 7713(P) by some margin. This is important since it nullifies AMD’s ability to claim its chips can consolidate two of Intel’s highest-end chips into a single socket.”
I would be leery of buying an Intel sound bite. I may distract them from focusing on MY interests.
Y0s – mostly just SATA and the BMC, not a big deal really unless there is the QAT accelerated PCH.
Steffen – We have data, but I want to get the chips into a second platform before we publish.
Thomas – my guess is Sapphire really is shipping 2022 at this point. But that is a concern that people have.
Peter – Intel actually never said this on the pre-briefs, just extrapolating what their marketing message will be. AMD has been having a field day with that detail and Cascade Lake.
I dont recall any mention of HCI, which I gather is a major trend.
A vital metric for HCI is interhost link speeds, & afaik, amd have a big edge?
Patrick, did you notice the on package FPGA on the Sapphire Rapids demo?
Patrick, great work as always! Regarding the SKU stack: call me cynical but it looks like a case of “If you can’t dazzle them with brilliance then baffle them with …”.
@Thomas
Gelsinger said: “We have customers testing ‘Sapphire Rapids’ now, and we’ll look to reach production around the end of the year, ramping in the first half of 2022.”
That doesn’t sound like the average joe can buy SPR in 2021, maybe not even in Q1 22.
Is the 8380 actually a single die? That would be quite a feat of engineering getting 40 cores on a single NUMA node.
I was wondering about the single die, too. fuse.wikichip has a mesh layout for the 40 cores.
https://fuse.wikichip.org/news/4734/intel-launches-3rd-gen-ice-lake-xeon-scalable/
What on earth is this sentence supposed to be saying?
“Intel used STH to confirm it canceled which we covered in…”
Comments are closed.