
AMD had its Milan-X announcement today, but there are two more big ones. Specifically, it has its next-generation “GPU” called the AMD Instinct MI200, the successor to the AMD Instinct MI100 32GB. AMD split its GPU line into more traditional gaming and workstation display-focused GPUs and compute-focused accelerators. The MI200 is a compute accelerator using the company’s CDNA 2 architecture. As a result of this split, AMD has the performance and efficiency to make a huge jump over the previous generation. This is an exascale-era accelerator.
AMD Instinct MI200
Let us get to the hardware. Specifically, AMD has a dual-die part. This dual-die part is compared to the single compute die NVIDIA A100, so AMD is doing something different here.

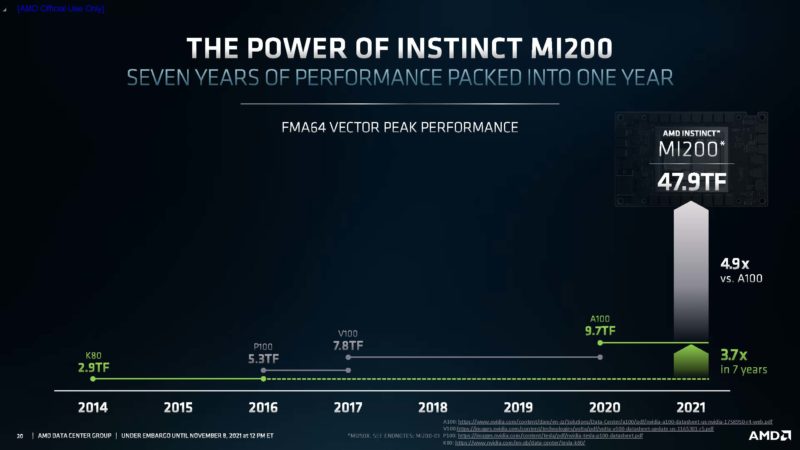
Just for some specs, AMD is saying this is a 58B transistor 6nm GPU, and that is a big chip (although smaller than a Cerebras WSE-2.)

One also gets more HBM2e. When The MI100 was launched, I asked the AMD team if 32GB felt small given NVIDIA’s move to 40GB then 80GB. Now, AMD is back with 128GB bringing a huge amount of on-chip memory. There are AMD EPYC 7003 single-socket servers that do not have 128GB of DDR4 as some sense of scale.
How AMD is bridging the dies is that they are using a 2.5D silicon bridge (Elevated Fanout Bridge) between the two dies. This takes up less space and is easier to manufacture than some of the other options on the market and AMD says that helps make these chips more manufacturable.
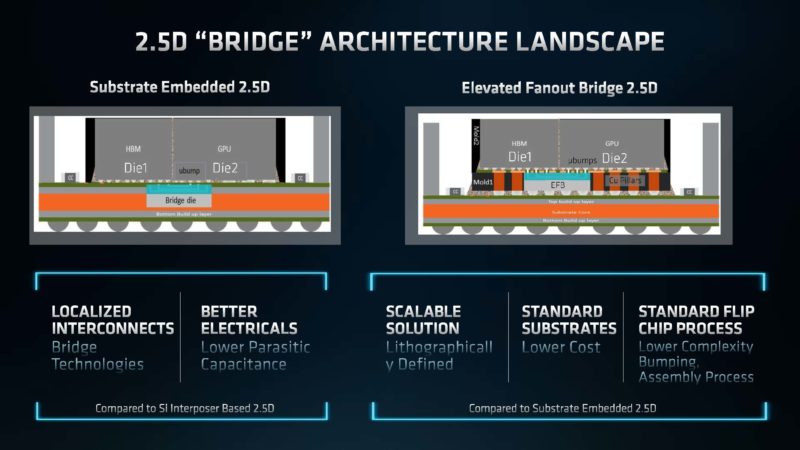
Something that is worth noting here is that AMD is doing to NVIDIA right now what it did to Intel years ago on the CPU side. It is going multi-die against a monolithic die competitor.
The performance impact is, well significant.

We asked AMD about this and I was told that AMD is comparing its OAM module (rumored to be ~550W) to the NVIDIA A100 SXM4 at 400W. If you saw our Liquid Cooling Next-Gen Servers Getting Hands-on with 3 Options you will note there are 500W A100’s that we tested, but most of the systems we focus on like the Dell EMC PowerEdge XE8545, Inspur NF5488A5, and another system we will review this week are using 400W SXM4 modules.
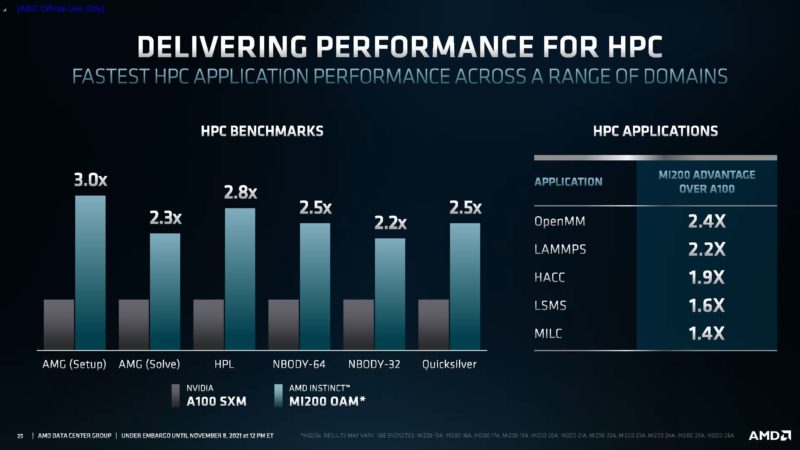
Here is the big leap that AMD is showcasing.
AMD also has a GPU to CPU and GPU to GPU interconnect that can hit 800GB/s using 25G lanes.

AMD seems focused on HPC FLOPS instead of AI at this point which is interesting. The company is highlighting that ROCm 5.0 will have support for AI/ ML frameworks as well. What is very distinct here is that while NVIDIA mostly is talking AI/ ML, AMD is conversely (more) focused on HPC.

The MI200 numbers are mostly from the MI250 OAM modules. We covered this a bit last week in AMD’s CEO Teases the OAM Accelerator Era on Twitter last week, and what OAM means.

The PCIe MI210 is a secondary focus for AMD. A PCIe configuration is more flexible, but it is also stuck at a lower power/ thermal envelope. So bigger customers are looking more towards the higher-power form factors like OAM. You can learn more about OAM from our 2019 Facebook OCP Accelerator Module OAM Launched. At the same time, we are going to have two reviews and videos of NVIDIA PCIe-based 8-10x GPU servers in the next week or so on STH.
Final Words
At the end of the day, NVIDIA will release a new set of GPUs to compete with the MI200. What we do know, however, is that AMD’s solution was strong enough to win Exascale with Frontier. A big part of that seems to be the performance of the AMD Instinct MI200 solution. Hopefully, we will get hands-on with these in the not-too-distant future.


 performance boost){kind=link}
Thanks for pointing out that the comparisons are against NVIDIA A100 SXM4 at 400W. So assuming MI250’s wattage at ~550W is ~1.375X which makes number like FP16, BF16 Matrix at 1.2X straight bad and MILC at 1.4X not that noteworthy.
Comments are closed.