
Today we have the answer to the NVIDIA A100 GPU from its chief (current) competitor, the AMD Instinct MI100. While the NVIDIA A100 GPU is getting a bump from 40GB to 80GB today, AMD is touting a new architecture specifically to deliver a lot of HPC flops at a low cost. Let us get into the new CDNA offering. Update: AMD let us know there is no “Radeon” in the product name since it is CDNA so we are updating the article to reflect that.
AMD Instinct MI100 Background
Keeping the background brief, the AMD Instinct MI100 is an architecture designed differently. AMD realized that traditional GPUs, insofar as they are “graphics” processing, are inefficient by including the logic that helps quickly render games. As a result, AMD split their GPU efforts into RDNA for the gaming community, as we covered in the recent AMD Radeon RX 6900 XT 6800 XT and 6800 Launch. For the data center, we have CDNA.

In all of these background slides, there are not so subtle jabs at NVIDIA. For example, above, we have “General Purpose” which is effectively NVIDIA’s Ampere design. Below, AMD is pointing out that it has public DoE exascale wins. Intel does as well (although perhaps HPE-Cray was the big winner here) and NVIDIA did not win in that first round of exascale contracts.
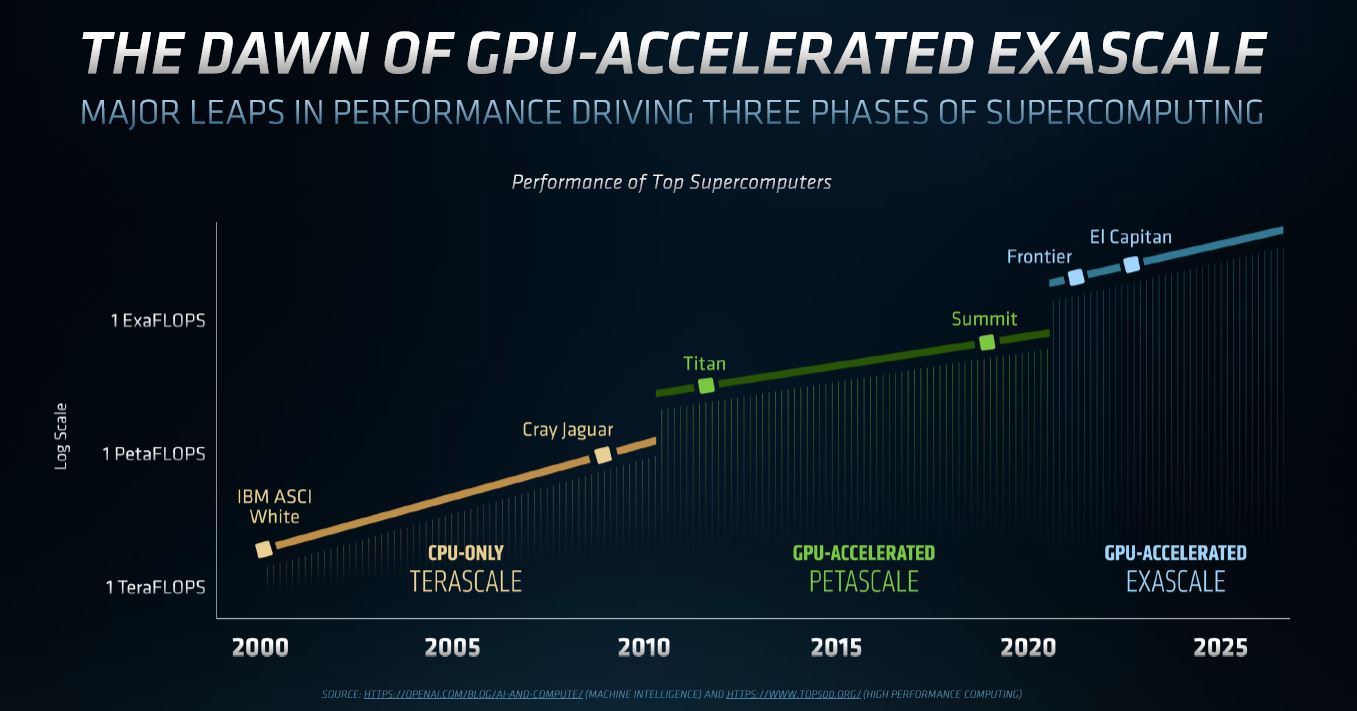
NVIDIA is doing more than high-performance computing for supercomputers with its chips, instead of focusing on AI acceleration with features such as supporting sparsity. As a result, the raw FP64 performance gains are not as large enough to meet exascale needs per AMD.
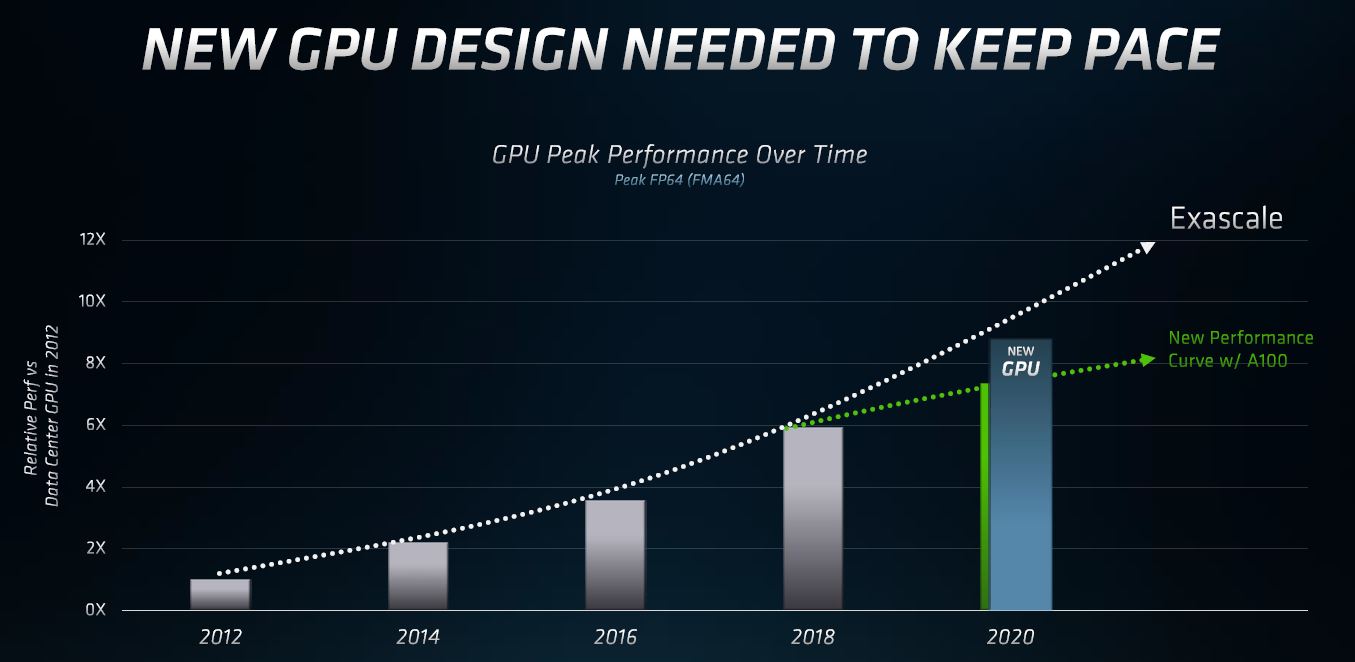
Intel for its part is saying the same thing, but AMD has its new product in the space today while Intel is releasing video transcoding server GPUs.
AMD Instinct MI100 Overview
The AMD Instinct MI100 GPU is the company’s new offering in the HPC compute space for GPUs. We are going to discuss the “Peak Performance / $ Compared to A100” in a moment, but let us get to the main specs first.

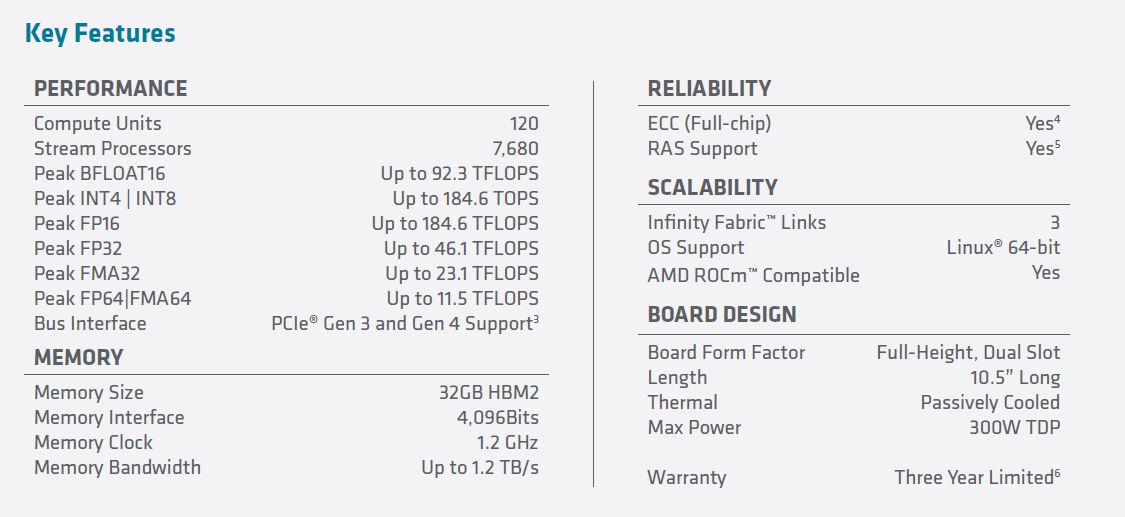
This is a 32GB HBM2 memory GPU with more memory bandwidth and higher compute density than the previous generation.

Here are the specs per the marketing slide:

We can see that we have a 11.5 TFLOP (peak) GPU that fits into a standard PCIe Gen4 x16 slot. Something that we wanted to mention is that Infinity Fabric Link. The Instinct MI100 is designed to run in four GPU “hives” as shown in this article’s cover image. AMD is using Infinity Fabric to provide more performance than PCIe Gen4 for GPU-to-GPU communication much like NVIDIA NVLink. We asked AMD about the 32GB HBM2 capacity given NVIDIA was already at 40GB before the 80GB is being simultaneously announced with the MI100. AMD said it was a sweet spot to control costs for HPC customers much like HPC customers often care more about filling memory channels than with hitting high memory capacity on CPUs.
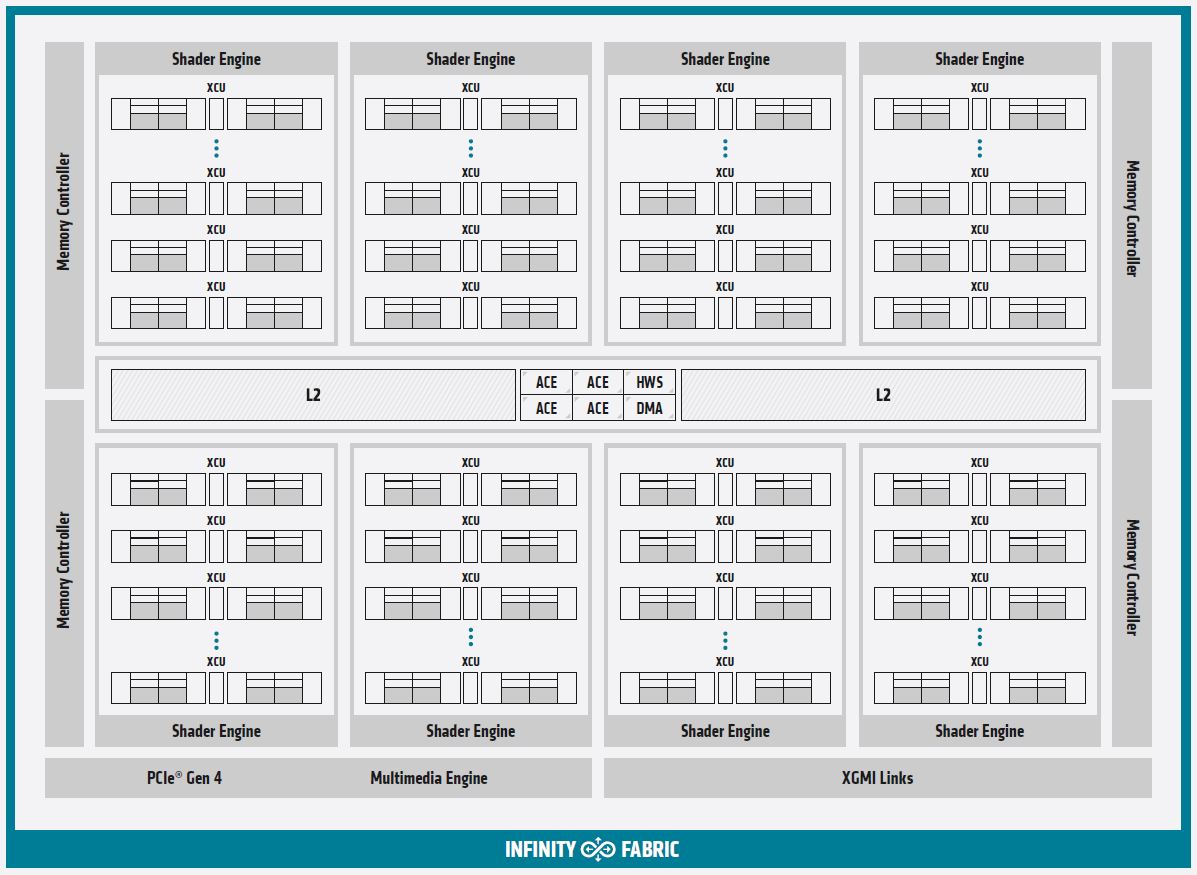
Here is a quick layout of the new Instinct MI100 via the company’s block diagram:
A lot of the speedup comes from the new pipeline. Here is what the “Enhanced Compute Unit” looks like. We have some readers that will skip this, other that will want to see details. AMD has a new whitepaper out with more details but otherwise, feel free to read the chart if you want to understand more about what AMD is doing at a very low level.
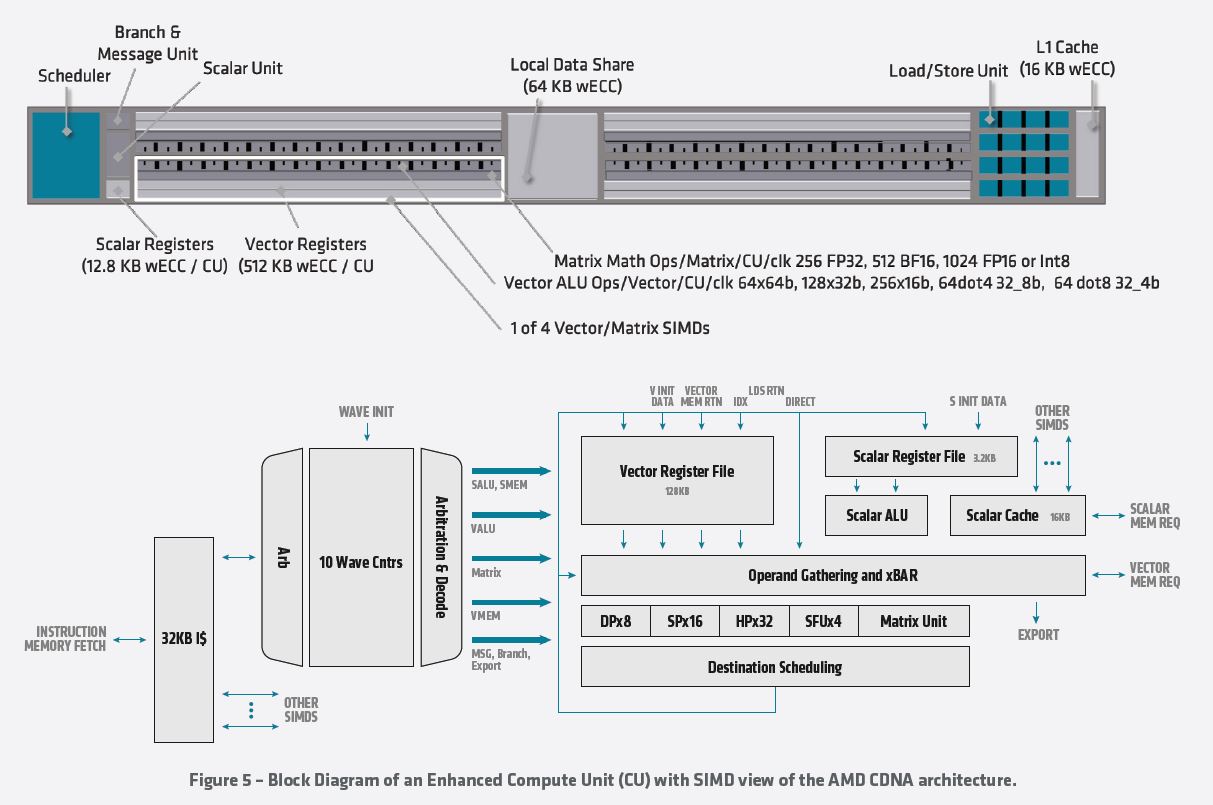
The net impact is that the AMD Instinct MI100 is a single 300W PCIe card that is 11.5 TFLOPs peak. AMD did an obligatory comparison of its new 300W PCIe GPU to the 2000 #1 supercomputer using 6MW and occupying many racks. 2000 was a long time ago in computing terms and back when Intel Pentium was still a premium brand.

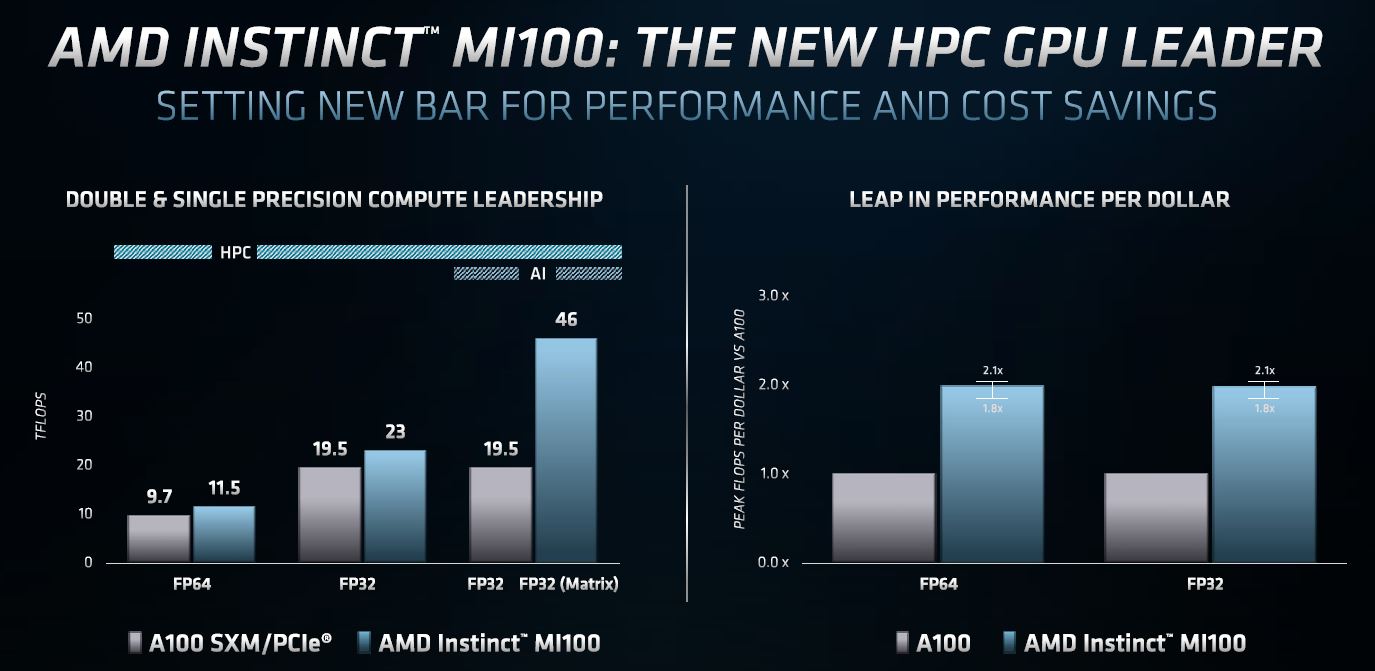
A bit part of what AMD is discussing is compute per dollar and performance per dollar. Having less memory onboard its new 7nm GPU helps with 32GB of HBM2 versus 40GB or 80GB from NVIDIA. At the same time, with the new NVIDIA A100 80GB, NVIDIA can push the 40GB model pricing down which will have a big impact on the chart below.
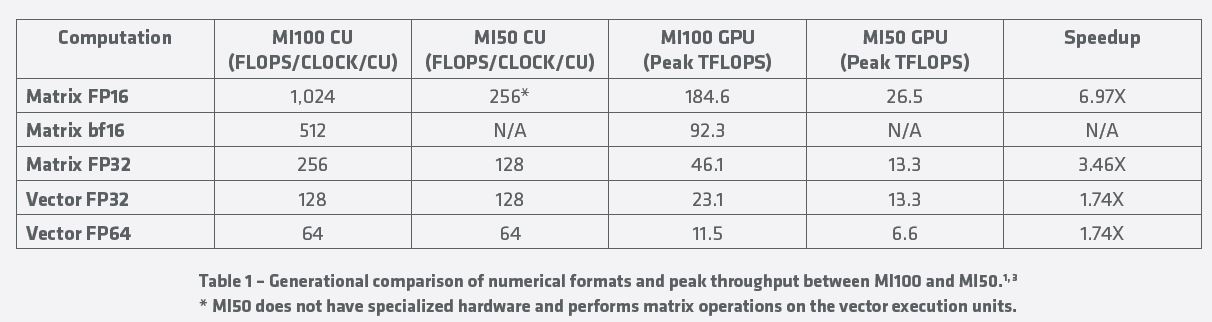
AMD is not just comparing to NVIDIA, it is also giving a comparison of its new chips versus its current-generation Instinct MI50. This table shows some of the massive performance gains which get close to 7x in the popular FP16 format.
Since we know AMD has won several Exascale computer contracts such as the El Capitan 2 Exaflop Supercomputer, we see ORNL as an early adopter discussing performance increases. We will note that AMD is comparing to the MI60 here not the MI50 as it did above. AMD is also comparing to the NVIDIA V100, not the current generation A100.

What we do know is that the buyers of these supercomputers are very smart individuals. Clearly what AMD showed them with the MI100 and future generations was good enough that NVIDIA did not win these contracts. Of course, AMD is looking to future generations of GPUs for its exascale plans, but it needs to get industry software running on its GPUs. For that, AMD has ROCm which is updated as well.
AMD ROCm 4.0 Updates
Part of the news is that AMD ROCm 4.0 is out. With each generation of ROCm, the company is covering more use cases and scenarios. The company has a big task where GPU compute was largely pioneered on CUDA and NVIDIA GPUs. ROCm allows AMD and its customers to easily port CUDA applications and other components to run on AMD GPUs.

Next year with ROCm 5.0 we will likely see a bit more about how ROCm 4.0 is incomplete but ROCm 5.0 has complete coverage. At least that is what we have been trained to expect over the past few generations. ROCm 4.0 is delivering larger performance gains which makes porting less painful for existing GPU compute users.

This is an area where those exascale DoE contracts are helping. Part of the contracts were going beyond hardware but also for developing tooling around the next-gen systems. AMD is investing in ROCm to ensure the software can run on its flagship systems as they start arriving. Intel has been talking about the benefits of OneAPI, but there is a good chance AMD will power the first exascale system.
AMD Instinct MI100 Partners
As mentioned earlier, AMD’s design centers around a 4x GPU to CPU ratio. Here AMD is showing four AMD Instinct MI100 GPUs per “hive” and one hive per AMD EPYC 7003 “Milan” CPU.

If you look at the cover image as well as the above, you can see that the bottom of the cards have PCIe Gen4 connectors but the top of the cards have a special bridge allowing GPU-to-CPU communication. NVIDIA has NVLink and the custom SXM4 form factor NVIDIA A100 4x GPU HGX Redstone platform.

Supporting these designs are systems from HPE, Dell, Supermicro, and Gigabyte. The Dell EMC PowerEdge R7525 you may have seen in our Dell and AMD Showcase Future of Servers 160 PCIe Lane Design article. We expect these platforms to support the AMD EPYC 7003 “Milan” generation as well.
Final Words
AMD is a few quarters behind NVIDIA launching the MI100 but well ahead of Intel’s Xe HPC part. With the big headliners of two major exascale supercomputers moving to AMD, we can imagine other smaller installations will look at what AMD is offering more seriously. It is good to see that AMD has a plan to close the software and capability gap with NVIDIA.


{kind=link}
“supercomputer using 600MW”
Its 6 MW, not 600. That would be the output of a medium-large nuclear reactor.
Patrick, so no word if these will have “AMD Smart Access Memory” and Infinity Cache; like their recently announced 6000 series consumer video cards.
“AMD is also comparing to the NVIDIA V100, not the current generation A100.”
Uhhh no they are not… You can CLEARLY see in the performance comparison slide right above this statement that AMD are comparing it to the “A100 SXM/PCIe” on the raw performance comparison half of the slide (left) and “A100” on the price/performance half (right).
In terms of simple raw compute performance, AMD appears to have an absolute MONSTER on their hands here. The sheer amount of FP64 & FP32 performance per card we’re talking about here is straight up crazy-town. And even more so if multi-GPU Infinity Fabric setups work as well as AMD is saying they will. ESPECIALLY at this price point.
Though in specialized AI workloads, & those that rely almost EXCLUSIVELY on matrix operations (rather than a more mixed FP32/matrix workload) Nvidia will definitely still have to upper hand thanks to their dedicated “Tensor Cores”, which are still pretty much incomparable in their ability to push matrix multiplication operations, but ofc come with a significant die space penalty for their inclusion (vs AMD’s approach of instead beefing out their standard CU’s with new “Matrix Core” accelerator blocks rather than spending a lot of their die space budget to spin such operations off to their own 100% dedicated hardware like Nvidia did. Die space which AMD chose instead to use to add more CU’s).
Cooe the image after that line you are quoting has 3 MI100 to V100 charts from ORNL. I think that’s what they’re talking about
Comments are closed.