
In April 2019, we broke the news regarding why AMD EPYC Rome 2P servers will have 128-160 PCIe Gen4 lanes. In 2020, Dell EMC and AMD are showcasing the flexibility of EPYC in a way that Intel Xeon servers can only fantasize about even in the upcoming 2020/2021 Ice Lake generation. In this article, we are going to show you how the Dell EMC PowerEdge R7525 is enabling 160x PCIe lanes to connected devices yet retaining even more flexibility than we see on Intel Xeon systems. This is an article we have wanted to do for over 18 months, so we are excited to get to show you Dell EMC’s design and implementation of AMD’s technology, and discuss why it is the future of servers.
Video Version
Since we know some of our readers like to listen along here is a video version with additional commentary.
If you want to listen along, we suggest opening this on YouTube and playing it in the background as you read this article.
Background How AMD EPYC 7002 “Rome” Dual-Socket Works
We could go all the way back to the “Naples” generation for the AMD EPYC 7001 series. In that generation, there were four dies which each had I/O and compute resources. Each die had thirty-two lanes that could be used as PCIe lanes in single-socket configurations. In dual-socket configurations, each die used sixteen of these lanes to connect to its counterpart on the second socket.

The AMD EPYC 7002 Series Rome series made a fundamental, and important change. With the introduction of the AMD EPYC 7002 I/O die, the x86 cores and their caches are now separated from the I/O die which has the external I/O. With the new generation, one can still have 128 PCIe Gen4 lanes using all eight of these 16-lane blocks as PCIe Gen4. In a dual-socket configuration, to match the Naples EPYC 7001 series, each CPU uses four of these sets of these x16 blocks to connect socket to socket.

Next, is where some of the magic happens. These links may be the same in quantity, but not in speed as on the AMD EPYC 7001 series “Naples” systems. Remember, AMD’s Infinity Fabric uses the same I/O as PCIe which is how we get that dual personality. Since we moved from the PCIe Gen3 to Gen4 in the EPYC 7002 series, the link speed needed to double. As a result, the Infinity Fabric in Rome is not just going into a single piece of silicon in the I/O die, but it is also benefiting from a faster link speed.
While AMD was competitive with Intel UPI inter-socket interconnect with its PCIe Gen3 Naples generation, AMD effectively got a 2x with Rome. For its part, Intel tends to increment by 10% or so per generation so this is a massive shift. We also saw Intel cut socket-to-socket bandwidth in its Big 2nd Gen Intel Xeon Scalable Refresh. As we found in our Intel Xeon Gold 6258R Review losing a third of the socket-to-socket bandwidth was noticeable in our virtualization workloads over the Platinum 8280, but it was nowhere near the point that it has as much impact as the price delta would have one assume. Effectively, AMD doubled bandwidth while in many ways Intel has positioned dual-socket systems for 33% less socket-to-socket bandwidth.
AMD and its partners realized this early on and have an intriguing solution. Since AMD has a more trans-personality socket-to-socket Infinity Fabric/ PCIe system what one can do is re-purpose some of these lanes as PCIe Gen4 lanes instead of using them as socket-to-socket links. In the diagram below, we have that case depicted.
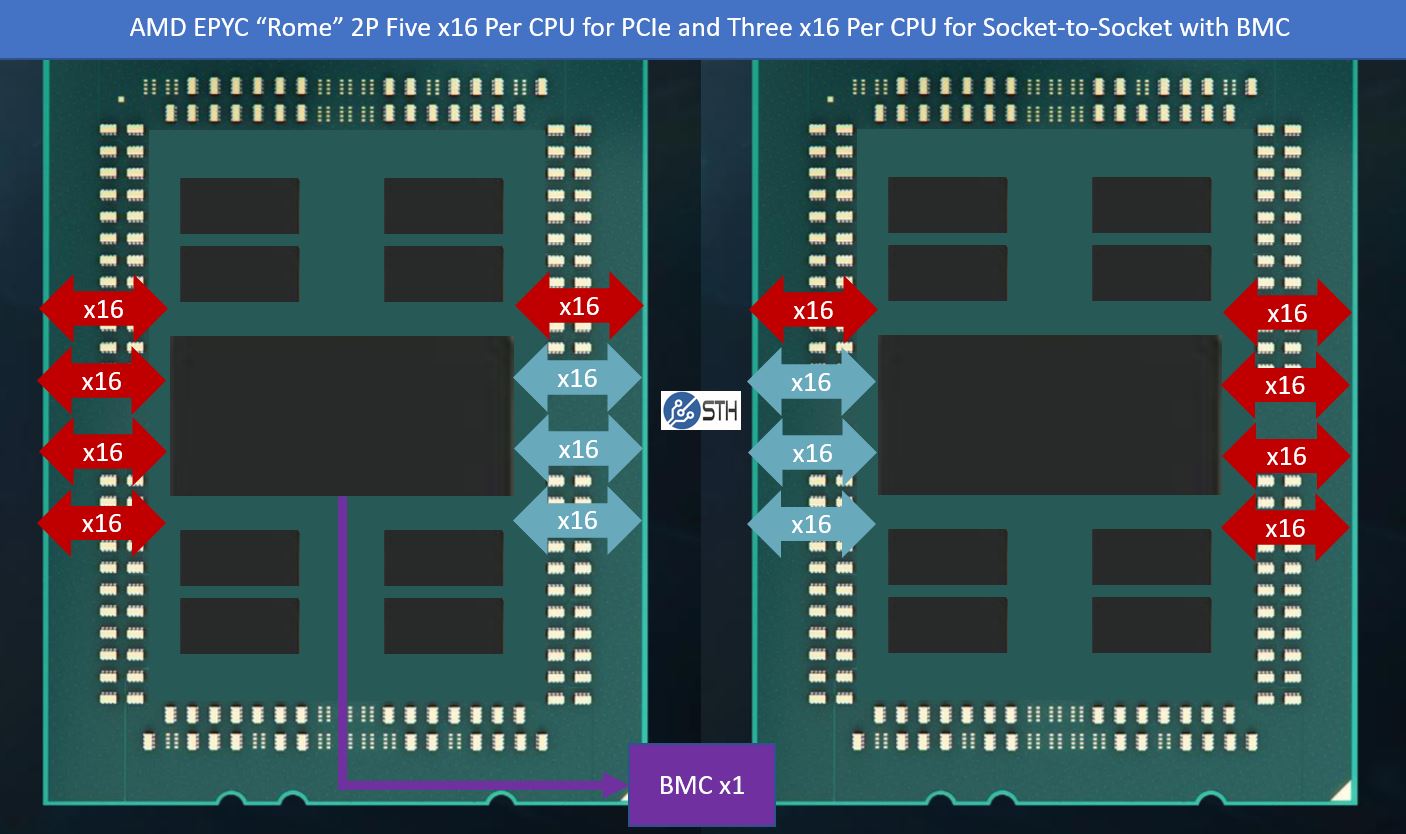
This yields a total of 160x PCIe lanes and still gives one around 50% more socket-to-socket Infinity Fabric bandwidth than in the Naples generation. For those wondering, we have seen 192x PCIe Gen4 lane designs, but from what I have been told the 160x PCIe lane configuration is all that AMD officially supports.
Until now, the majority of designs we have seen use either 128 or 160 PCIe lanes. Dell EMC, however, has a way to have the best of both worlds with more flexibility.
Enter the Dell EMC PowerEdge R7525 160x PCIe Gen4 Lane Configuration and Flexibility
The Dell EMC PowerEdge R7525 is the company’s dual-socket AMD EPYC 7002 (and likely EPYC 7003 “Milan”) generation platform. It supports the best of current-generation AMD EPYC with PCIe Gen4 and a ton of flexibility. As we were working on our review we realized we had too many PCIe Gen4 lanes available. Let us count.
First, we are going to start with the risers. We have two PCIe Gen4 x16 and two x8 electrical slots. That is a total of 48x PCIe Gen4 lanes. As an aside, since these are Gen4 not Gen3, these provide the effective bandwidth of an entire current-gen dual-socket Intel Xeon Scalable system. Of course, we had more which we fully expected.

Under the riser, we have an OCP NIC 3.0. Here we have an Intel X710-based dual SFP+ 10GbE NIC, however, these slots are designed for Gen4 and up to x16 electrical so they can handle up to dual 100Gbps port NICs. If you saw our recent “What is a DPU?” article, we have a BlueField 2 option that fits in an OCP NIC 3.0 slot pictured. In the future, this can potentially run VMware ESXi as part of Project Monterey which allows control/ management and application plane disaggregation. With 16 lanes here, we are up to 64 lanes total which is equal to an Ice Lake Xeon generation processor’s worth.

Then things get a bit wild. On the front of the system, we have 24x NVMe SSDs each with a PCIe x4 connection. 24 drives with 4 lanes each require 96 lanes. We double-checked the system, and there are no PCIe switches for these drives, they are all direct cabled.

Here is a topology map with the OCP NIC and 96 lanes in 24x NVMe devices.

How Dell is doing this is actually a bit of clever engineering. We removed the PowerEdge R7525 fan partition to get a better view. As one can see there are four cables in the middle of the system. Each cable connects two NVMe SSD bays and carries 8x PCIe lanes. Four of these cables give us one-third of the connectivity or eight of the 24x NVMe SSDs on the front of the system.
When we looked at the 24-bay option on the dell configurator we saw it says “without XGMI.” For the high-level translation, think of XGMI in this case (or xGMI) as equivalent to Infinity Fabric links.
As we looked again at the cables, one can see that the cables are very close to the CPUs, much closer than the other PCIe Gen4 riser and cable headers on the PowerEdge R7525 motherboard.

From reading the service manuals, it turns out that these can be connected to provide CPU to CPU connectivity or, as we see in our test system, used to route PCIe lanes elsewhere in the chassis. A design like this is quite amazing in its simplicity and flexibility. Instead of having to do multiple different motherboard spins, Dell has taken a pair of those x16 links we showed as changing from Teal to Red in our diagrams above and made that a configurable option.
Final Words
As you may have figured out by now, this was originally part of our upcoming Dell EMC PowerEdge R7525 review. It became so long that we had to pull this section out into its own piece.
Beyond the PowerEdge R7525 itself, it also shows the flexibility of using these high-speed lanes as either CPU to CPU or PCIe interconnects. Intel would struggle in AMD EPYC 7002’s counterpart, the Cascade Lake Xeon generation to do the same because it is using dedicated UPI and PCIe link IP blocks. One could, perhaps, cable UPI, but it is not a simple BIOS flip to turn it into PCIe.
The other item it shows us for the future of servers is just how much motherboards are changing. On the PowerEdge we are showing the motherboard does not have a traditional PCIe x8 or x16 connector. Instead it has one OCP NIC 3.0 connector, then high-density connectors for risers, and cables for the NVMe drives. These cables can re-direct PCIe lanes from front-panel NVMe storage to risers as an example. AMD EPYC Rome motherboards require more layers and higher-quality PCB to ensure signal integrity because of PCIe Gen4 but there are still limits. Building more modular systems with cables to devices is a much more scalable and flexible model as we move to PCIe Gen4 and into PCIe Gen5 eras. We are rapidly approaching a period where systems have more cables than we saw in the previous generation since we cannot simply rely upon long PCB traces.
Again, kudos to Dell EMC here for showing us what is possible using an elegant design to achieve flexibility on their flagship 2U dual-socket AMD EPYC platform.



{kind=link}
You’re now like a professor of this stuff. Nobody’s talked about this feature and yet you’ve found it, then showed how it works. Now bring us the full review of this beast so I can bring it to our procurement team. We use STH’s reviews when they’re available in our procurement process.
Is it also available in the R6525 ?
It would be really something in the future when Dell transition from U2 to E1L or similar.
This makes the R740xd look old fashioned.
The 4124GS-TNR from supermicro does something similar with its 160 PCIe lanes. Either all of the lanes can be routed to the 10 PCIe slots on the daughterboard, or some of them can be connected via SlimSAS cables to the storage slots. Its an interesting concept that increases the flexibility of the system.
Patrick,
Definitely cool stuff!
Finally, a solution/product which doesn’t really on PCIe->NVMe Adapters which use expansion slots for drive connectivity, along with universal drive bays which support SATA/SAS and NVMe devices.
Ice Lake SP will be extremely short lived – and will offer 128 PCIe4 lanes, while Sapphire Rapids will have 80 PCIe5 lanes per CPU – and since it’s not limited to 2 sockets… even a 2S vs 2S is 160 PCIe4 lanes AMD vs 160 PCIe5 lanes Intel.’
More interesting on Sapphire Rapids is the 4 HBM stacks on die… Not that you understand what CXL is or what it will allow – but keep on fluffing AMD – you are good at it.
Can these flexible lanes connect one motherboard to another motherboard?
Were you able to do any testing or benchmarking of the read/write of the NVME drives, particularly in a RAID config?
Think of these like socket-to-socket in 2P or PCIe lanes rather than a way to extend to more sockets in a system for now.
I’ve always thought STH has had crazy amounts of CXL coverage. Sapphire isn’t set to compete against Rome or Milan. That’s Genoa and a new platform from AMD right? Intel’s already been announcing delays in Sapphire.
I mean, it’s not really fair to compare Rome to Ice since it will be Milan and Ice, Genoa and Sapphire. I don’t think what they’re doing is unreasonable since Milan shares Rome platforms and they’re talking PCIe while Ice is a new platform
Bob – where did you get that information for Sapphire Rapids? I haven’t seen anything saying how many PCIe lanes it will have.
Having 160 lanes could make for an impressive vSAN setup. All NVMe capacity drives & Optane Cache drives running off of dual dual port 100GbE iSCSI. Too bad there aren’t 4x x16 risers. You could have done quad 200GbE if there were.
Mind completely blown. Thank you Patrick, this just went on the buy list.
So, if move the cable back to CPU to CPU, no change on the BIOS or any other hardware setting ???
Is it make sense to buy intel Xeon based server in 2020 or wait for 1-2 years to Arm based server to come ? Thanks for advise.
Comments are closed.