
A few months ago, AMD teased its 3D V-Cache solution. Today, that demo Ryzen chip’s technology is going mainstream with the AMD Milan-X. The easiest way to think of Milan-X is that it is the AMD EPYC 7003 series, with a huge pile of L3 cache added to it. By “huge pile” we do not mean 30% or 50% more. AMD is instead tripling L3 cache which has a big impact on many applications.
Some Background
A few months ago we covered that Server CPUs are transitioning to the GB onboard era. This is not quite there at 768MB of L3 cache, but we are now at 0.75GB. Here is that video:
It is pretty clear that we are headed in this direction overall. Intel already announced Sapphire Rapids with HBM in 2022.
AMD Milan-X
Instead of making this overly complex, let us get to the basics of AMD Milan-X. Effectively AMD uses its based Zen3 Milan chips, the ones found in the AMD EPYC 7003 series, and then adds cache die space atop the main logic/ cache die in existing chips.

AMD is using direct copper connections to get high performance and density in the chip-to-chip stacking interconnect.

The benefit of AMD’s methodology is that it is able to add cache while also minimizing the power used to add that cache. It is also able to get a lot of performance out of this solution.

AMD is saying it has 804MB cache per socket, but that is adding L2 cache which now seems extremely diminutive in scale compared to L3.
AMD also said that Milan-X is socket compatible with SP3. We know there will be a TDP impact of more cache, but we do not have the exact extent yet.
For those wondering, on a call AMD’s executives told us Milan-X and “Trento”, the CPU used in Frontier are not the same. Trento is designed more for all-out throughput and feeding the MI200 series GPUs used for the Exascale system.
Microsoft Azure HBv3 Upgrade
We also had the opportunity to chat with the Microsoft team about its HBv3 instances. Here is what is really cool: it is upgrading its instance pool to Milan-X. Although initially getting a HBv3 instance meant one would get Milan, the company has already been deploying the Milan-X chips, for what sounded like some time. As a result, the entire instance family is switching over to the new chips which is really interesting.
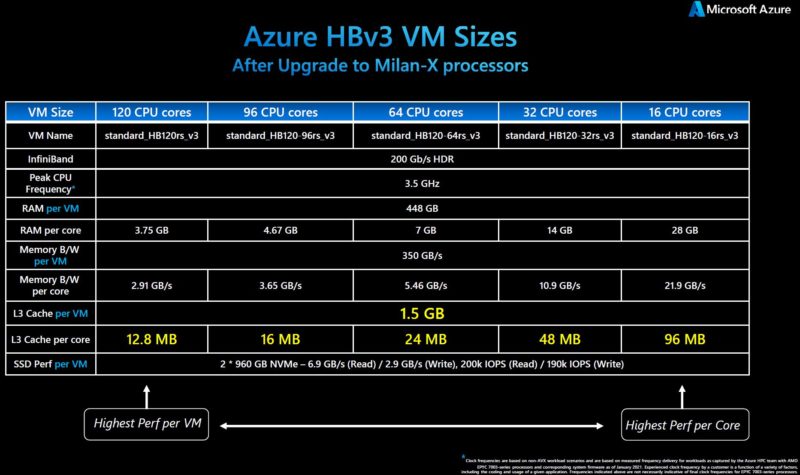
The Microsoft team also told us that some of the gains here are enormous. I asked specifically about the additional latency for the stacked cache segments. The response I got was very simple. The base case cache is basically the same. There is a very small latency to go to the stacked cache. On the other hand, that small latency to go through the interconnect up to the stacked die is so much smaller than going off the CCD, through the IO hub, then out to memory and back, that it is effectively irrelevant from a performance penalty perspective. Instead, one gets a ton of performance if the application can use this cache.
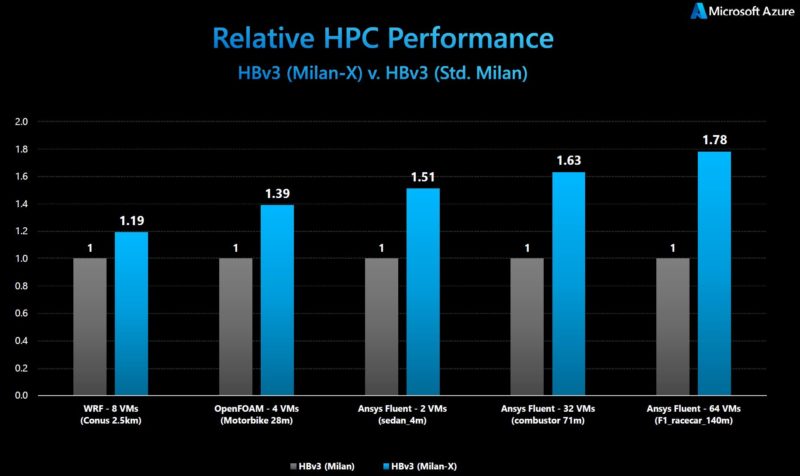
Microsoft also said that there were applications that naturally are not memory bound and do not really benefit from the larger caches and so in those cases one is left to simply similar performance to its standard Milan offering. Basically, Microsoft’s viewpoint is that Milan-X is somewhere between neutral to a huge positive just depending on the workload. It just so happens many of the memory-bound workloads are HPC workloads. As a result, the Azure HPC offering was quick to jump on the new chips.
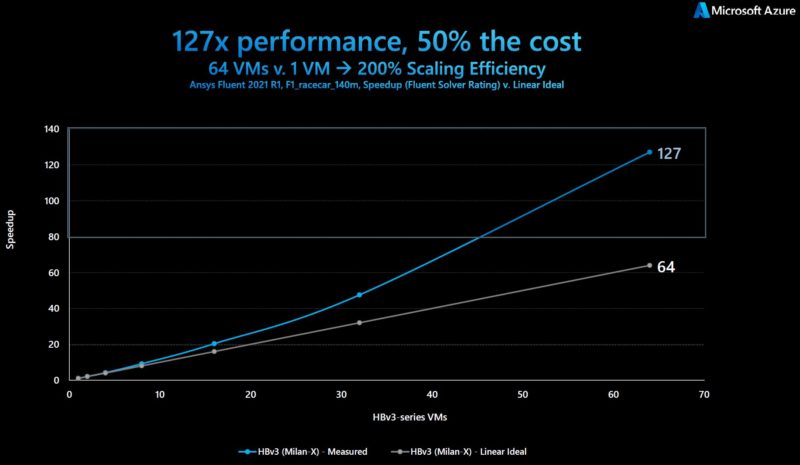
Perhaps the coolest data point was the scaling that happened due to being able to cache more.
What is more, Microsoft is going to start making instances available to some customers starting with today’s announcement.
Final Words
This is a huge deal in the industry. AMD did a great job here. For those wondering, the new chips will have 7__3X model numbers to denote they are AMD Milan-X CPUs not the standard CPUs.
When we discuss 0.75GB of cache per chip, that is certainly a lot. That also means in a dual-socket server, one can now get 1.5GB of L3 cache, entering the GB era. Microsoft’s instances are already being upgraded to this spec which is absolutely awesome.



{kind=link}
Was there any public statement on price delta and retail availability?
Retail is like early 2022 or at least then for OEMs like Dell and Supermicro
@Patrick
“…We know there will be a TDP”
End of sentence missing?
I wonder how this will work for in RAM databases.
Back when L1-3 cache first hit 64KB, there was a semi-joke that went: if I only plan to run DOS, do still need to buy DRAM?
Not having checked in on the matter in many years, is it the case that a system needs to have at least as much RAM as the largest L# cache? With L3 approaching a GB, this isn’t a serious question for production configurations, by might be for ad-hoc bench-testing & trouble-shooting.
0.75GB … if the first number is a zero, maybe you are using the wrong Prefix. why not just say 750mb ? This is an old be winning AMD play. The first time I saw it was on the AMD K6-III At that time L2 cache was on the motherboard. when AMD added l2 to the chip, you got the onboard as L3. at the time the AMD K6-III 450 was the fastest x86 chip around.
Comments are closed.