
Many readers at STH will know that we have been running a series around the future of data center technologies. Today, we are going to take a look at the impact of liquid cooling in the data center. Specifically, we are going to take a look at some of the common options, and then get a hands-on look at some of the impacts. Indeed, we are even going to show off 8x NVIDIA A100 80GB 500W GPU performance a part that is not even officially listed by NVIDIA. Let us get to it.
Video Version
As we have been doing with this series, you can check out a video version here:
We always suggest opening the video in a YouTube tab or window for a better viewing experience.
Also, we wanted to point out that the way we were able to do this is that we managed to get to stop by Supermicro in June where there were two 8x NVIDIA A100 systems setup. Luckily, we had the ability to check out some of the other interesting items in the lab. A quick thank you to Supermicro for making this happen.
Liquid Cooling Methods Overview
First, let us get into liquid cooling methods and why we should care. Starting with the why is perhaps the easiest to work through so we are going to start with that.
Why Data Center Liquid Cooling is Inevitable
Data center liquid cooling is going to happen. Today we commonly see CPUs in the 200-280W range and GPUs in the 250-400W range. In 2022, we will start to see CPUs use well over 300W, more than most GPUs today, and GPUs/ AI accelerators hit 600W and higher. Against that backdrop, one must also remember that PCIe Gen5 and features such as the EDSFF revolution will put more pressure to create larger systems with higher-power needs on devices away from the CPU and GPU. We recently did a E1 and E3 EDSFF to Take Over from M.2 and 2.5 in SSDs article and video you can see here:
There are effectively three primary challenges with higher power servers:
- How to keep the data center cool
- How to keep the rack cool
- How to keep the chips cool
Many coming from an enthusiast workstation background may immediately think of liquid cooling as a way to keep chips cool. That is true, but it is not the only place cooling matters.
At the data center level, liquid cooling is actually in fairly widespread use. Liquid is commonly used to move heat from the data center floor to chillers or other parts of the data center. We recently did a piece: Touring the PhoenixNAP Data Center with a video here:
In that piece, one can see liquid being used to remove heat from the facility and keep the data center cool. There are many data centers that have more extensive use of liquid cooling and with different methods, but at a data center facility level, liquid is in use quite regularly. It needs to be simply because the amount of heat being generated is increasing and moving heat in liquid that can transfer more heat faster and more efficiently is the best option.

At the rack level, there is a major challenge as well. For years, the typical power delivery to North American racks has been via 208V 30A circuits. Those only provide 208V * 30A * 80% loading for safety = ~5kW of power. The servers we will be showing later in this article each use over 5kW in single 4U servers.

This has enormous implications. At higher power levels, containment can help, but at some point, racks designed to house servers at around 120W/U need to handle cooling at >1kW/U. While cooling may seem like a simple task, or just moving to lower densities, that has follow-on impacts as well. If only a few servers are in a rack, then interconnects are most likely to be optics and perhaps sometimes over a longer range. If many servers are in a rack, then an inexpensive and low-power DAC connection to the top-of-rack switch can make sense. Likewise, two PDUs for 20 servers may not seem like a huge cost, but two PDUs for a single server increases costs. Finally, many organizations are limited in the number of racks that can be used. As a result, building a GPU cluster with 100 GPU servers can be impractical to do if that requires 100 racks because of power and cooling.
Heat must be extracted from the rack quickly to maintain the performance of the servers and keep servers running at their maximum performance levels. At STH, we are the only site that tests servers with machines above and below to simulate real-world usage. For example, the 2U 4-node form factor we started testing in 2017 using the “STH Sandwich” where the top and bottom of a system under test was being heated by systems above and below.
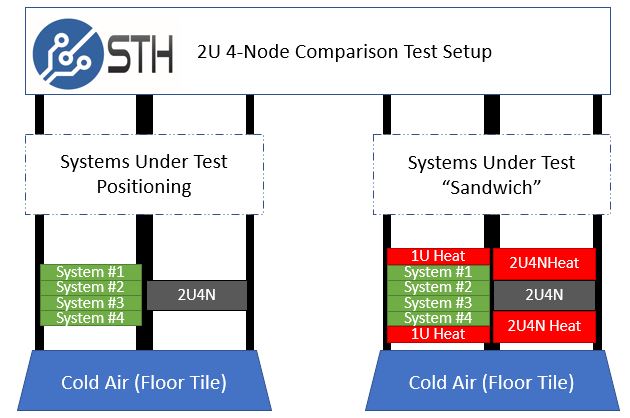
This is critical to modern server testing. Modern servers often perform better if they do not have servers above or below since they get better cooling. In actual deployments, most want to get the maximum amount of performance per rack. Cooling at a rack level is a big deal as servers get hotter.

This practically means that many facilities designed around 5-15kW racks are now faced with situations where standard 1U servers are using 1kW each. Cooling for these facilities is simply not designed to keep up with the pace of newer servers. We have already passed the era where a dual-socket (plus accelerator) standard server is using more than the 208V 30A rack, and that form factor will likely increase by at least 1kW next year and then continue to rise after that.
At the chip level, we have just started to hit a point where liquid cooling is effectively required. With the 500W NVIDIA A100, the vast majority of 8x GPU designs need to be liquid-cooled. Some 4x GPU designs with half of the rack density can cool 500W GPUs, but require stringent and low facility ambient temperatures for air cooling to be effective. This is because, at a chip level, heat must be removed from the surface of the package. With only a limited amount of surface area, the rate of heat removal needs to increase over that surface area. We are starting to see that the only practical way to remove heat from modern chips is to use some sort of liquid cooling.

The bottom line is that liquid has a higher capacity to move heat quickly and efficiently than air.

With that background, I had the opportunity to take a look at two systems, one air-cooled and one liquid-cooled. Around those two systems while at Supermicro there were actually a few of the company’s efforts highlighting three key methods for removing heat. There was an older rear door heat exchanger, a liquid immersion cooling tank, and finally a direct-to-chip liquid cooling solution.
First, we are going to look at the rear door heat exchanger solution.



{kind=link}
The kiddies on desktop showed the way.
If data centers want their systems to be cool, just add RGB all over.
I’m surprised to see the Fluorinert® is still being used, due to its GWP and direct health issues.
There are also likely indirect health issues for any coolant that relies on non-native halogen compounds. They really need to be checked for long-term thyroid effects (and not just via TSH), as well as both short-term and long term human microbiome effects (and the human race doesn’t presently know enough to have confidence).
Photonics can’t get here soon enough, otherwise, plan on a cooling tower for your cooling tower.
Going from 80TFLOP/s to 100TFLOP/s is actually a 25% increase, rather than the 20% mentioned several times. So it seems the Linpack performance scales perfectly with power consumption.
Very nice report.
Data center transition for us would be limited to the compute cluster, which is already managed by a separate team. But still, the procedures for monitoring a compute server liquid loop is going to take a bit of time before we become comfortable with that.
Great video. Your next-gen server series is just fire.
Would be interesting to know the temperature of the inflow vs. outflow. Is the warmed water used for something?
Bonjour
Je sui taïlleur coudre les pagne tradissonelle ect…
Je ve crée atelier pour l’enfant de demin.
Merci bein.
Hi Patrick.
Liked your video Liquid Cooling High-End Servers Direct to Chip.
have you seen ZutaCore’s innovative direct-on-chip, waterless, two-phase liquid cooling?
Will be happy to meet in the OCP Summit and give you the two-phase story.
regards,
Comments are closed.