
This is a pretty cool one. AMD is adding a new HBM3E to the MI300X to create an MI325X for 2024. It also is talking about its next-generation MI350 with CDNA 4 in 2025. The AMD Computex 2024 keynote is going to have some cool AI details.
Please excuse typos. We are covering this live.
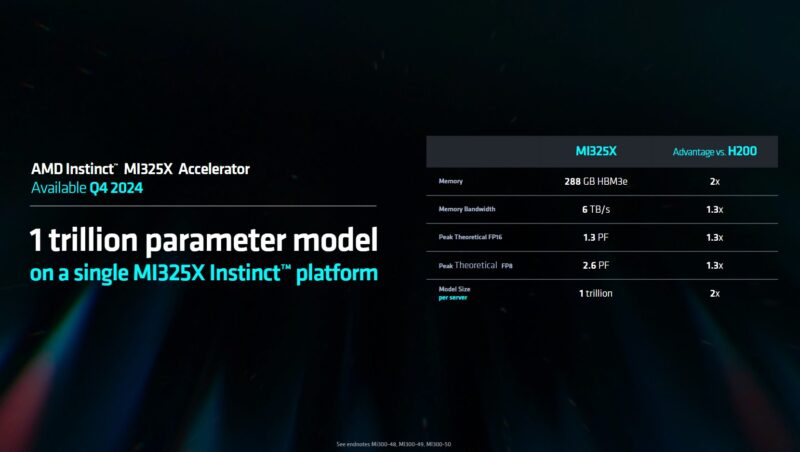
288GB AMD Instinct MI325X Coming this Year MI350 Next Year
AMD showed off the new AMD Instinct roadmap. This is an annual cadence. Something that is really interesting here is that it is going from CDNA 3 in 2023-2024 to CDNA 4 in 2025, but the model number is still a MI3xx part. 2026 has a CDNA Next and a MI400 designation so perhaps 2026 is going to be something wild from AMD. I do wonder why AMD is calling this CDNA Next instead of CDNA 5. Maybe it will pull a fast one with CDNA Cinco? For now, we have to wonder after CDNA 1-4 what will be Next.

For 2024, we have the AMD Instinct MI325X. This uses HBM3E memory for up to 288GB. More memory means bigger models on a GPU or in a chassis.

AMD is pushing its MI325X versus the NVIDIA H200 here. AMD is using the H200 part here as a 2024 part, but the Blackwell platforms will also start to come out this year.
What seems like the Blackwell era competitor is the AMD Instinct MI350X. This will support FP4 and FP6 and be a 3nm part. It will also offer CDNA 4 versus the MI300X and MI325X era CDNA 3.

Here is the crazy slide, AMD is saying that it will offer 35x the inference performance with CDNA 4.

Taking a step back here, 35x? Part of that is coming from the FP4 support, but that is a big number to dangle out there for a single-year gain.
Final Words
AMD also covered that it is all-in on Ultra Ethernet Consortium (UEC) for scale out AI networking. We just covered how UALink will be the NVLink Standard Backed by AMD Intel Broadcom Cisco and More for scale-up so we are not going to cover those yet again.
Still, AMD is pushing it against NVIDIA on the AI side. That seems to be why AMD is trending to more extensive sales than Intel on the AI accelerator side in 2024.
What we did not get is a MI300A update here, which is surprising given how NVIDIA is pushing Grace Hopper, then Grace Blackwell so heavily.
If you want to see more about the Ryzen desktop and AMD EPYC announcements at the keynote, you can check out those pieces.



{kind=link}
Saw a shitload of abbreviations and model names here with absolutely no idea what they mean. I know AMD but honestly, you might want to start the article with an ontroduction summary of what the hell you are talking about as people might become more interested if the assumption wasnt that its for coming from a nerd that thinks everyone else is a nerd too who knows 1000 abbreviations.
With LLM inference, actually utilizing the compute throughput has been challenging as it is hard to get batch sizes big enough to get good compute utilization due to how big the models are, and therefore not having enough memory for the needed KV cache to handle concurrent requests.
Most GPUs right now don’t get within 50% compute utilization due to that.
More memory per GPU means mainly the ability to increase the number of concurrent requests that can be handled (the batch size). That in turns improves the GPU utilisation, moving from it being memory bandwidth bound to compute bound.
For MI350, Most likely the 35x perf increases is based on a case where the model is too big for current GPUs to be well utilized. And the gains therefore probably come from:
* ~2x more memory capacity or more, increasing compute utilisation by as much thanks to batch size increase
* Fp4 instead of fp8 increasing compute utilization by 2x as well by increasing batch size by 2x as well
And they most likely have to increase compute throughput as well, but not as much:
* Maybe ~8x compute throughput per compute unit with Fp4 compared to fp8
* ~2x more compute units or/and some frequency increase for the rest
The MI325X is coming out this year and the MI350 is coming out next year. The MI350 will offer 35x the inference performance of the previous generation. This is due to the use of CDNA 4 and FP4 support.
Performance on paper ? actual performance.
MI300X VS H100?
MI350X VS B200
MI400X VS ?
Comments are closed.