
Today we get the launch of the new Intel Data Center GPU Max series. The “Max” branding is what Intel is rolling out for its HPC families of CPU and GPU products. While we have seen the new GPUs, codenamed Ponte Vecchio before, Intel is now talking about specific products ahead of SC22 in Dallas next week.
New Intel Data Center GPU Max at SC22 Including PCIe and OAM
Here is the Intel Max series summary slide. We are going to focus on the right side of this diagram for covering the new GPU series.
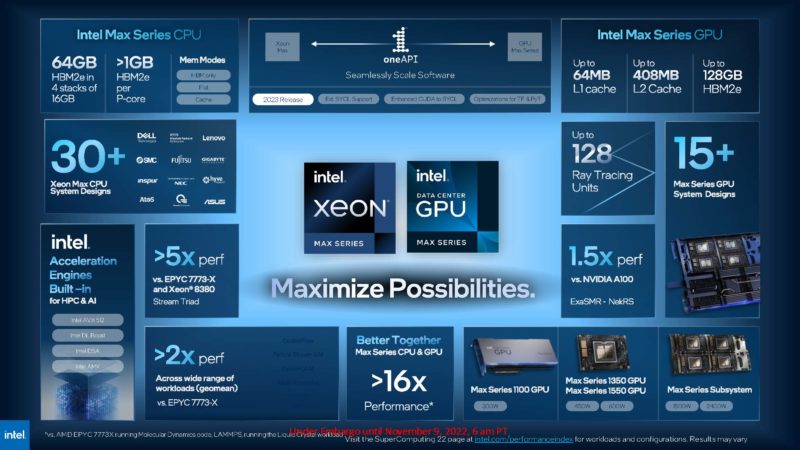
The new Intel Max series GPU, formerly “Ponte Vecchio”, scales to two stacks of Intel’s Xe GPU cores, 8 HBM2e controllers, and 16 Xe links.

Since we first heard the name Rambo Cache name at SC19, it was clear that this is a major feature. Each of the new Max GPU series stacks has 204MB of L2 cache meaning that the full package can have up to 408MB of L2 cache.

When we talk about “stacks” they are important. Ponte Vecchio is a next-generation accelerator so power targets for the industry are now well beyond PCIe power and cooling capabilities. Still, PCIe form factors are popular since they are easy to integrate. Intel plans to offer the Data Center GPU Max 1100 as a PCIe accelerator. This is a single stack solution so it has less compute, cache, and HBM2e memory, but it fits into a 300W TDP envelope.

Intel also said it will have Xe Link bridges to connect up to four GPU Max 1100 units.
The full GPU Max series packages will be the OAM modules. Intel will have the Max Series 1350 GPU with a 450W TDP and 96GB of HBM2e. The larger OAM module is the full 600W 128GB of HBM2e and the full 128 Xe cores and will be called the Max Series 1550 GPU.

Those individual TDPs are important. Like we have seen with NVIDIA and its A100 “Redstone” platform in reviews like the Dell EMC PowerEdge XE8545 review, Intel is going to be selling OAM subsystems with these modules. 450W x 4 = 1.8kW while 600W x 4 = 2.4kW. Intel did not discuss larger OAM subsystems, but it has solutions like the 8x OAM solution with the Habana Labs Gaudi2.

Between the different OAM modules, Intel has a 4x Xe Link solution so that each can address the other GPUs directly. It took until the V100 generation for NVIDIA to fully embrace this type of SXM-to-SXM NVLink topology (while eventually adding NVSwitch in that generation.)

We re more focused on products in this piece, so we are not going to get too deep in Xe Link.

Intel also showed its next-generation “Rialto Bridge” Data Center Max GPU series. These will feature 800W per OAM and be liquid cooled while offering features like 25% more Xe cores. Rialto Bridge is the refinement generation of Ponte Vecchio.

Intel expects the new GPUs to be in the same subsystem making system design easier for server vendors.
Final Words
It is great that we are getting actual product names and specs for Ponte Vecchio. Intel said that it will not have a Top500 linpack run for SC22 in Dallas next week with Aurora, but it does have a test system installed. A few things are worth noting here. First, the industry is moving towards the XPU design which is Falcon Shores for Intel. We already covered that in our Intel Falcon Shores XPU Update at SC22 piece. Still, current computing models will be around for some time. Second, the PCIe form factor is proving challenging for GPUs as power and cooling requirements increase. PCIe is easy to deploy in standard servers, but it is not ready for the future.

Finally, we have been talking about the product for years, it is good to see Ponte Vecchio take the next step in becoming a product by getting specs and model numbers.


{kind=link}
Sounds promising! Now if Intel and AMD can break CUDA’s deathgrip on GPGPU applications, that’ll be a real game changer!
Rialto bridge is now a 2024 product:
https://www.intel.com/content/www/us/en/newsroom/news/introducing-intel-max-series-product-family.html
was intended to sample in 2023:
https://www.intel.com/content/www/us/en/newsroom/opinion/accelerated-innovations-sustainable-open-hpc.html
At what point does a SMR (Small Modular Reactor) become a standard subsystem for a new data center buildout?
The more interesting thing about the 408MB of L2 cache is that 288MB of it is on the base tiles, along with the fabric. Any more detail on that feature? It is mentioned on the slides you show.
Don’t get me wrong, the above article depicts some exciting new Intel gear…But how does the ever increasing Wattage per server, per GPU etc play out for pre-existing data centers.
In the ~14 year old data center that I spent almost a decade in the solution was two pronged 1) Open up a new server room using immersion cooling, 2) when replacing old gear in an air-cooled server room install less gear per rack
Strategy #2 eventually leads one to have to decide on a very expensive and invasive upgrade of the power systems for the given server room, or perhaps accept that it may only be populated less than 50% full.
IIRC the number of server nodes per air-cooled server room rack dropped by at least 25% from perhaps 2010 to 2018 (and that was before the hockey stick power-per-server uptick really go under way.)
What does the software story look like?
NVIDIA’s hardware has been strong but the real story is that AMD has been weak. With NVIDIA I can start out with Tensorflow, Keri’s, PyTorch, and many others — and think right away about my model, my data, etc.
I am looking at building a new PC and I am going w/ NVIDIA precisely because of this. I want something that is good for games and VR development but I do some AI work and for projects I do on my own I have no time for another systems development effort. In a real business, the extra cost of the right kind of programmer for the time it would take would add $120,000 or more to the cost of a project which can buy a lot of hardware. A national lab can screw around with off-brand GPU but not most organizations,
Comments are closed.