
Microsoft was at the AI Hardware Summit in Mountain View, California this week and brought with them an interesting box that we did not cover previously at OCP Summit. The Microsoft HGX-1 is a “DGX-1 class” solution that Microsoft designed to scale up. While each 4U server is designed for 8x NVIDIA Tesla SXM2 GPUs plus 4x 75W expansion cards, the design is meant to be more scalable. Using a PCIe switch fabric, the company designed the Microsoft HGX-1 to scale up to 32x GPGPUs and be deployed in clusters of thousands of GPUs. Since we missed this previously, we are going to take some time to show the solution as we move towards our DeepLearning12 8x NVIDIA Tesla Server setup.
The Microsoft HGX-1
At the AI Hardware Summit, we saw a Microsoft HGX-1 that was pulled from a lab. You can see four SXM2 modules with large heatsinks covered by an air shroud. There are another four behind this. We could not find a screwdriver at the show, but the design documents show that they are there and we lifted the shroud to verify.

Those large black heatsinks are for the Broadcom PLX PCIe switches. Microsoft’s innovation was creating a large PCIe switch fabric to help the solution scale.
At the rear of the unit, we have room for 4x full-height PCIe expansion slots for up to 75W devices. These devices can be anything from NICs to ASICs. Another interesting use that Microsoft mentioned is M.2 SSDs that can locally feed data to pairs of GPUs. The rear I/O is dominated by external PCIe connectors. To give you an idea of why these heavily shielded connectors are for, here is a diagram from Microsoft:
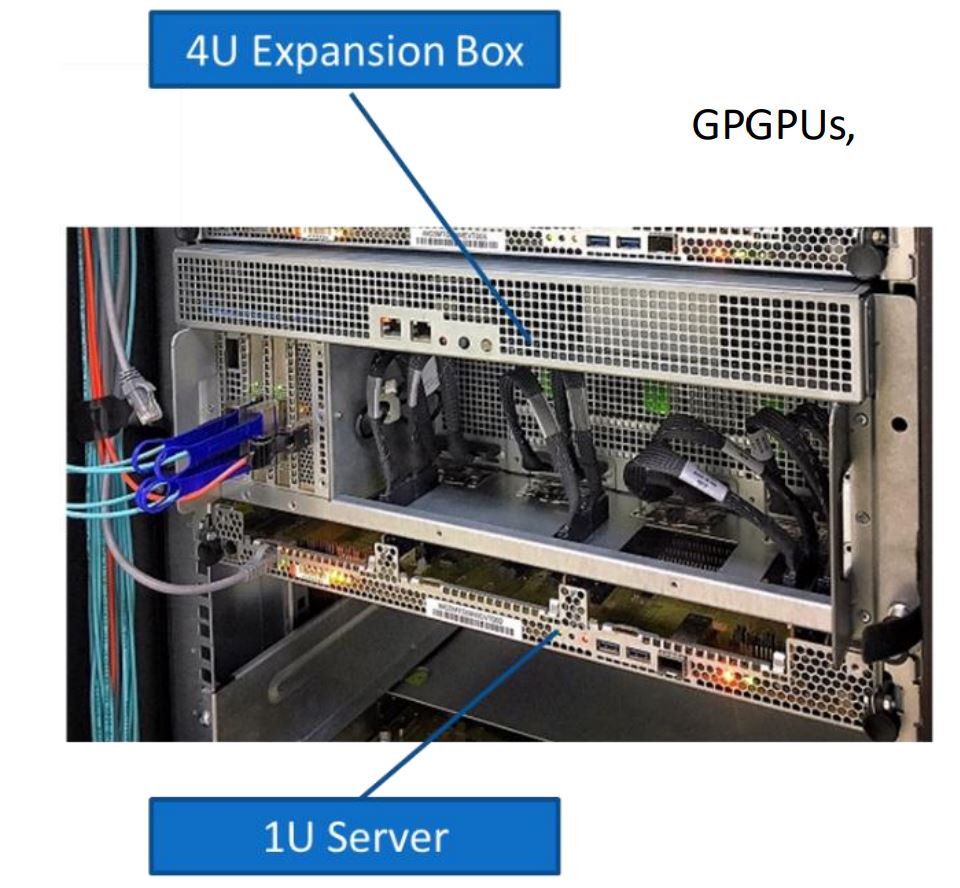
You can see that the sheet metal cutouts are designed to easily cable to a 1U server below the chassis. These external connectors can be used to cable to a host system or to other GPU chassis to form larger clusters. In the topology diagram from Microsoft, each x16 from the 96 lane PCIe switches to the external connectors can split into two PCIe 3.0 x8 connections.
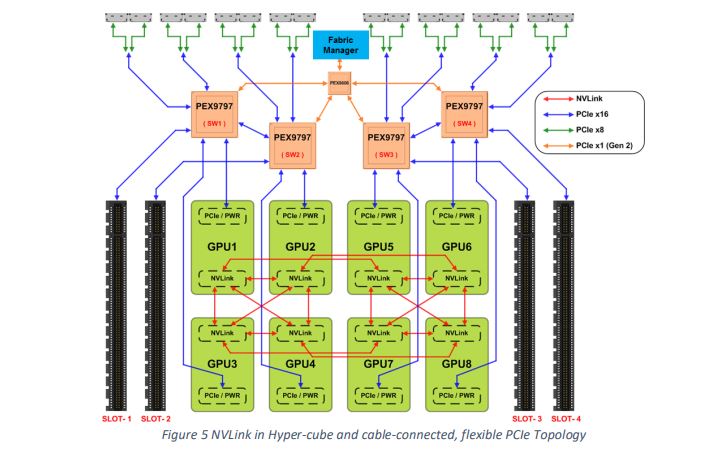
Within the chassis, we see a similar NVLink GPU-to-GPU setup, along with a PCIe x16 slot per PCIe switch. This PCIe slot is on the same PCIe switch complex as two GPUs, similar to the NVIDIA DGX-1 and DeepLearning12.
Microsoft HGX-1 Key Specs
Here is a quick high-level feature set of Microsoft HGX-1:
- 4U Chassis Form Factor
- Six 1600W PSUs (N+N)
- Twelve Fans (N+2)
- Four 96-Lane PCIe Switches from Broadcom (PEX9797)
- Eight bifurcatable x16 Links (Cables for External PCIe Interconnect: 8×16 or 16×8)
- 4 x FH¾L PCIe Cards + 8 x 300W GPGPUs (SXM2 or double-width FH¾L PCIe Form Factors)
- Node Management (AST2500/2400 BMC family, 1GbE Link to Rack Manager)
- Rack Management Sideband : 2x RJ45 Ports for out-ot-band Power Control
- PCIe Fabric Management for multi-Chassis Configurations, multi-Hosting, and IO-Sharing
- Four general-purpose PCIe Cards in addition to configurable and flexible Accelerators
- Eight nVidia Pascal P100 and V100 SXM2_NVLink
- Flexible choice of GPGPUs in PCIe Card Form Factor
- Various GPGPUs in double-width, 300W PCIe Card form factor
- nVidia GPGPUs Such as V100, P100, P40, P4, M40, K80, M60
- AMD Radeon
- Intel Xeon-Phi (now discontinued by Intel)
- Other FPGA or ASIC Accelerators
- High PCIe Bandwidth to Host Memory and for peer-to-peer
- Up to 4 PCIe-interconnected Chassis (with a dedicated PCIe Fabric Management Network)
- Expandable to Scale UP
- From one to four Chassis
- Internal PCIe Fabric Interconnect
- Scale Out via InfiniBand or Ethernet RoCE-v2 Fabric
- Host Head Node Options
- 2S Project Olympus Server
- 1S, 2S, 4S Server Head Nodes (eight x16 PCIe Links)
- Up to 16 Head Nodes (sixteen x8 PCIe Links)
Final Words
NVIDIA is clearly moving to bigger systems with NVSwitch and the DGX-2. At the same time, these 8-way GPU systems are a well-known quantity. Microsoft was solving scaling architecture with PCIe switches well before NVSwitch was released using off-the-shelf PCIe. Much like the Facebook Big Basin did. That is a major engineering accomplishment.



{kind=link}