
A few weeks ago, we completed what we are calling our “DeepLearning12” build. DeepLearning12 is an 8x NVIDIA Tesla P100 (SXM2) server designed for deep learning, AI, and HPC workloads. We wanted to share some of the hardware details on what we are using, and give an overview of the Gigabyte G481-S80 server we are using prior to our formal review.
DeepLearning12 the DGX-1.5 Build
We are calling DeepLearning12 the DGX-1.5. That is because the system has a number of updates to the original DGX-1 including using a newer processor architecture.
- Barebones: Gigabyte G481-S80
- CPUs: Intel Xeon Gold 6136 (N.B. we are swapping to Gold 6148’s this week.)
- RAM: 12x 32GB Micron DDR4-2666
- Networking: 4x Mellanox ConnectX-4 EDR/ 100GbE adapters, 1x Broadcom 25GbE OCP, 1x Mellanox ConnectX-4 40GbE
- SSDs: 4x 960GB SATA SSDs
- NVMe SSDs, 4x 2TB NVMe SSDs
We are calling this a DGX-1.5 because DeepLearning12 is based on the Gigabyte G481-S80, Intel Skylake-SP platform. Although for low-cost single root PCIe servers Skylake was a step backward, for the larger NVLink systems, Skylake-SP has a number of benefits. These benefits include an increase in memory bandwidth of over 50%, and better IIO structure for PCIe access, and more PCIe lanes for additional NVMe and networking capabilities.
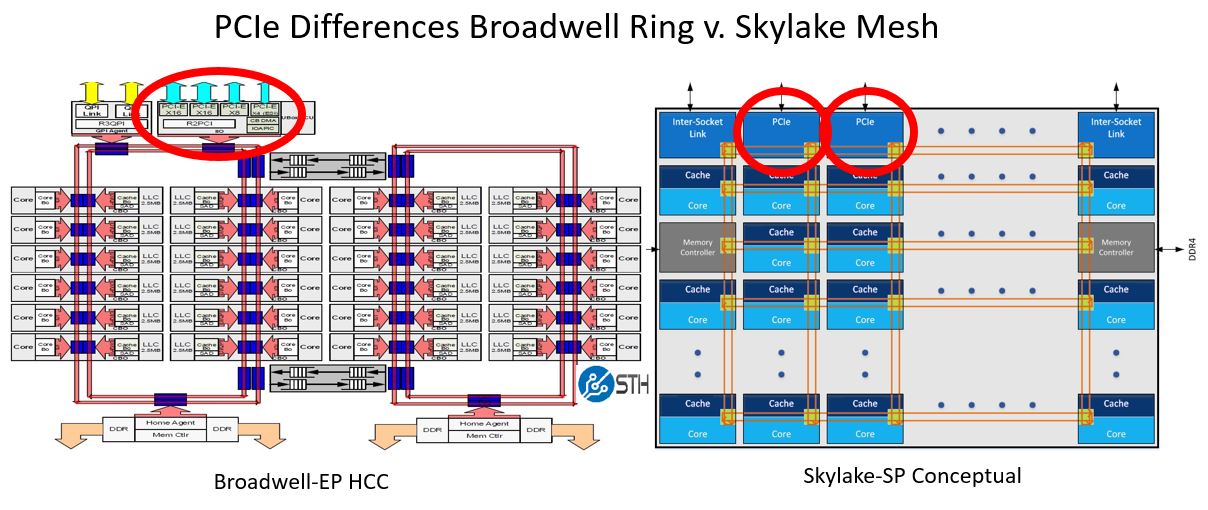
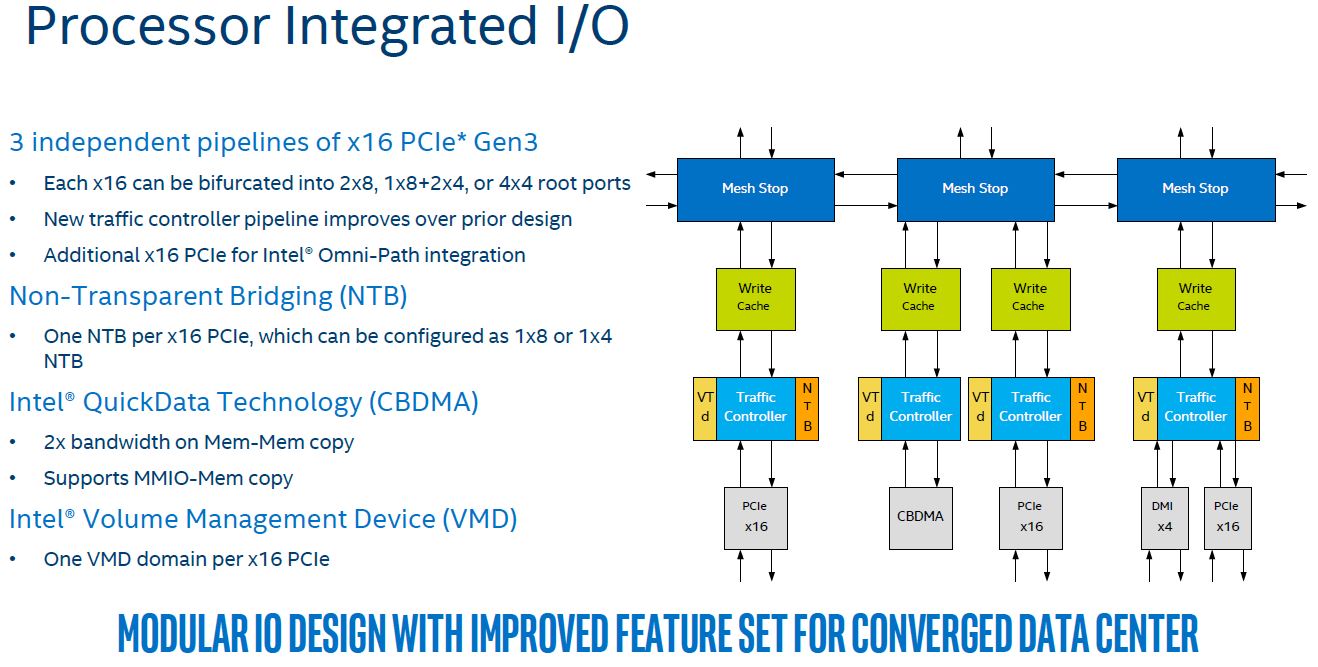
The new Intel Xeon Scalable processors are better suited to the NVLink style machines than the single root PCIe architectures of the Xeon E5 generation because the new IIO structure has additional mesh stops and dedicated caches and traffic controllers for each mesh stop. The Intel Xeon E5 generation processors utilized a single stop on the legacy ring architecture. For the better processor to PCIe I/O, Skylake is an improvement.
We had to build DeepLearning12 ourselves. Gigabyte sent the G418-S80 server but we had to buy and pull from the lab all of the NICs, SSDs, NVIDIA Tesla P100 16GB SXM2 GPUs, RAM, and CPUs.

All told, this is around ~$65,000 worth of gear sitting on the table at Element Critical in Sunnyvale, California waiting for installation.
For those who want to know more about SXM2 GPU installation, here is our installation video. NVIDIA SXM2 GPUs utilize NVLink, but they are very difficult to install.
We have more on the installation in our guide How to Install NVIDIA Tesla SXM2 GPUs in DeepLearning12.
DeepLearning12 Hardware Overview
Here is the overview video including our thoughts on the Gigabyte G481-S80 platform and some of its features.
There are a number of features beyond the NVLink enabled NVIDIA Tesla P100 GPUs which make this an awesome platform. These include the four NVMe 2.5″ U.2 bays on the front of the chassis. A major industry challenge is how to feed the Tesla GPUs which are voracious for data. Each pair of GPUs has its own Mellanox 100GbE/ EDR Infiniband NIC. Common solutions to feed this class of systems over a network can range from the open source distributed NVMe Ceph powered storage clusters to high-end Pure Storage arrays. Having four local NVMe bays allows for either large local cache arrays or high-speed cache arrays (e.g. Intel Optane NVMe SSDs) to be used locally. With DeepLearning11 class designs, one would often see a single NVMe SSD sitting locally in the server.
In terms of networking for the system, we like the inclusion of the OCP mezzanine slot. We were able to use our lab’s standard 25GbE Broadcom OCP NICs to provide basic provisioning and network services for the machine. One strange part about the Gigabyte G481-S80 is that the dual 1GbE NICs and management NIC ports are located on the front of the chassis. In a data center, that means it is in the cold aisle which can be challenging if you do not have cold aisle networking.
Final Words
We have had this system under load for some time and will have a full review of the DeepLearning12’s base server, the Gigabyte G481-S80 later this month. Stay tuned to STH for more on this awesome platform.



{kind=link}
What kind of support contracts are offered with this? We use DGX-1’s but the annual support costs are enormous and so it’s an item we’re looking to close on future purchases.
@Timothy J: Always ask yourself first, “do we need a support contract”?
Thanks for sharing this post,
is very helpful article.
Comments are closed.