
Meta announced a new large-scale AI research cluster. The new cluster is called the Meta AI Research SuperCluster or RSC for short. The goal of the new cluster is to accelerate AI research in areas like NLP that are training ever-larger models. Meta gave us a quick look at the inside of the system before its announcement today via a video shared under embargo.
Meta RSC Selects NVIDIA and Pure Storage for AI Research Cluster
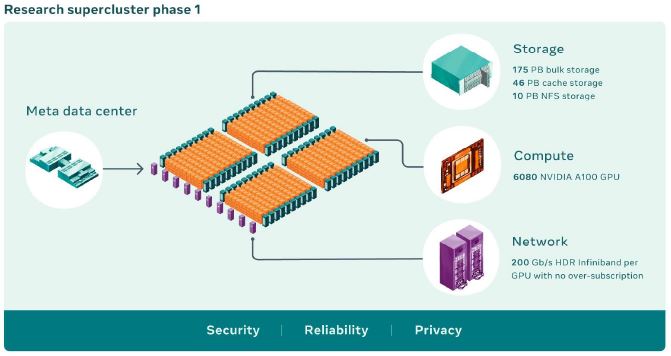
Instead of getting into the lofty AI research goals, let us instead get into the hardware that was shown. Meta says its RSC uses 760 NVIDIA DGX A100 systems (pictured in the cover image.) Each of these has eight NVIDIA A100 GPUs.
The fact that these are NVIDIA DGX systems, not HGX partner systems is significant. NVIDIA says that it is supporting its partner OEMs, but this is a solution well into the tens of millions of dollars that NVIDIA is using its own boxes instead of a partner system like the Inspur NF5488A5 8x NVIDIA A100 HGX platform we reviewed. Especially given NVIDIA’s pending Arm acquisition that is under fire for potentially stifling competition, winning a large deal like this by taking it directly rather than letting partners get a win is certainly not helping NVIDIA’s case that it is enabling ecosystems.
This might be a deal that NVIDIA adds revenue for, but becomes a new example for global antitrust regulators to point to. NVIDIA says it enables an ecosystem but is showing that it is going further into total system integration pushing partners out. NVIDIA is going directly after its partner ecosystem with these new supercomputer wins, and regulators will take note of that. It is a hard place for NVIDIA as it wants to bundle its technologies and drive revenue. At the same time, NVIDIA’s competitors will point to deals like this as examples of why NVIDIA cannot be trusted to stifle competition with the pending Arm acquisition.
Networking is provided by NVIDIA Quantum 200Gb/s HDR InfiniBand in a two-level Clos fabric. This fabric is not oversubscribed. We can see that there is a CDU and liquid cooling distribution in the network racks. Here the red nozzles on the left are the warm liquid while blue on the right is the cooler liquid side.

Something else that we see is that Meta has fiber distribution that is above the rack infrastructure.

We found a shot of the MPO/MTP distribution block here:

It appears as though Meta is also running multi-mode MPO/MTP to the nodes. You can learn more about that in our Guide to Indoor Fiber Optic Cable Color Coding.

Aside from the GPU compute and networking, we also saw a few non-compute elements.

For storage, there is a 175PB of Pure Storage FlashArray for bulk storage and a 10PB Pure Storage FlashBlade array for NFS storage.

In addition, there is a total of 46PB of cache storage in Penguin Computing Altus systems. Altus is Penguin’s AMD EPYC server line.

We can see that there are non-GPU compute racks as well.

While this is the initial phase, Meta plans to expand by more than 2x this phase 1 footprint in the future.
Final Words
Meta has been one of the cloud companies pushing against NVIDIA for quite some time. An example of this is with the Facebook OCP Accelerator Module OAM that was designed to push back against proprietary form factors like SXM4. Going with the A100 here instead of an OAM solution seems to be an action in the opposite direction. For some reason, it feels like Intel is the big loser in this one. Intel acquired Habana Labs (an OAM solution) partly based on Meta’s feedback. Now, Meta is going NVIDIA for its research cluster. Other AI players like Cerebras and Graphcore also lost out on this one.

This is a big deal. Meta’s choice of technology will have an impact elsewhere as others seek to follow the technology used by a leading AI research company. Perhaps this highlights what we have been seeing lately. MLPerf Training has become a NVIDIA affair. Now it seems like a large hyperscale research cluster is going NVIDIA and will continue to expand to more nodes and further solidify the company’s stranglehold on the AI market.
For Pure Storage and Penguin Computing, this is certainly a big win as well. That is a fairly large storage cluster for Pure to deliver.



{kind=link}
Yes, interesting that this was purchased rather than OCP equivalents, though this was certainly ordered some time ago? Was it specified if Meta integrated everything themselves or did they use a 3rd party?
“NVIDIA’s competitors will point to deals like this as examples of why NVIDIA cannot be trusted to stifle competition”
A shallow conclusion if there ever was one. It sounds like this could have come from the lips of AMD or Intel.
For proper perspective, all one needs to look at Nvidia’s graphic board business. Do 3080 founder edition boards lock out Asus or Gigabyte from building their own? No. They simply ask their partners for more value add than solder. And guess what, they have.
Meta’s move was the big single finger salute to Intel who has been stringing FB along for years with lame Nervana and Habana Labs AI solutions. No one offers the Omniverse/metaverse solution Nvidia has, and that’s more likely why Meta got on board with DGX. This is going to be a long and important relationship for them both.
So this is going to be one of the homes of future big AI conditioning generation-z from potatoes into peas?
Love technology, but the power this brings it just a handful of men and women over the masses is immense.
In the words of Elon Musk, ‘AI will become dangerous if we don’t regulate’ – reading between the lines, *those behind the input of AI datasets and algorithms will become dangerous to what we today class human-civilisation.
Still searching for a refurbished A100 to play with, anyone here worked with the hardware yet?
Comments are closed.