
At Intel Architecture Day 2018, there was a lot of great information. Intel spent a lot of time on hardware but the most important bit may have been on the software side. Intel laid out a vision for One API which takes the company’s 15,000+ software developers and will align their efforts to make it easier for the software ecosystem to use the company’s products. If you think about Intel as a CPU company, it is time to re-align that belief. Instead, think of Intel tomorrow as a company proactively chasing a growing total addressable market (TAM) with the best products it can offer. If you think about Intel as a company who wants to get the biggest share of the biggest TAM, One API becomes extraordinarily powerful and essential.
Background on Intel One API
Here is the setup. Intel has CPUs, and despite what others want to say about Intel or x86, their CPUs have an enormous installed base and are going to be around for generations to come. As part of Intel’s Core Strategy, those CPUs will get specific accelerators over generations to help performance on specific workloads. Every time Intel introduces a new instruction, there are really two cases. One for legacy platforms that do not have the instruction and another for new platforms which have the capability. One of the biggest barriers to adopting new instructions (e.g. AVX-512) is that software developers need to take advantage of the new instructions.

Going beyond the CPU to the Intel chasing the biggest share of the biggest TAM, one may next stop at Intel’s FPGA business acquired from Altera years ago. One way to look at FPGAs is in their traditional roles doing tasks like network processing. The newer way to look at FPGAs is in their role bringing AI to everything. Having a configurable and flexible compute unit is handy in many different environments where an ASIC is too constraining, or where models will rapidly evolve. It is no secret why Xilinx is chasing this market with Versal.

Where does that FPGA live? Is it a PCIe device in a larger system? Is it a network attached a device as we saw with Microsoft Project BrainWave? Intel’s vision is much more than PCIe cards and embedded FPGAs, it also encompasses FPGAs alongside x86 cores. We saw demos of this years ago such as with Broadwell-EP with FPGA On-package at SC16. That brings some ultimate accelerator flexibility to the CPU.

For AI and deep learning, Intel has the Nervana NNP which is not productized in its first generation, but I spoke to Naveen Rao this summer and he said they are still planning to have a commercial version in 2019.

Intel has other products like Movidius sticks for inferencing while at the same time building AI inferencing acceleration into its CPUs.
Next are the Intel iGPU and dGPU offerings. Intel is serious about going after the GPU market as competitors like NVIDIA are encroaching on its CPU platforms, such as with the recently launched NVIDIA Jetson AGX Xavier Module for Robotics Development.
Beyond just these compute resources, Intel makes a lot of stuff. Examples include Omni-Path fabric, Ethernet NICs, chipsets with security processors, silicon photonics, NAND SSDs, Optane SSDs, Optane Persistent Memory, and the list goes on. Not only does Intel design these products, but they also build them, and support them after release.

Remember, Intel as a company who wants to get the biggest share of the biggest TAM and that requires a lot of products to do so.

Having a lot of products is great, but supporting a lot of products can be hard on teams. From the outside, a FPGA RTL programmer may not care about x86. A data scientist armed with Tensorflow may be focused on their code and does not want to know about the GPU or TPU it runs on. If you are Intel, you want to enable both the low-level access to your hardware, but the higher value is really in making it seamless for data scientists and other programmers to use their higher-level frameworks and not care about which Intel part it is running on. That is how you get to chase a bigger part of a bigger TAM and is the problem that One API is targeting.
One API to Rule Them All
A key tenant in the One API solution is unifying all of the hardware, SDKs, and middleware used to deliver optimized software experiences to users of Intel hardware, whether that is x86 CPUs, AI accelerators, GPUs, or FPGAs.
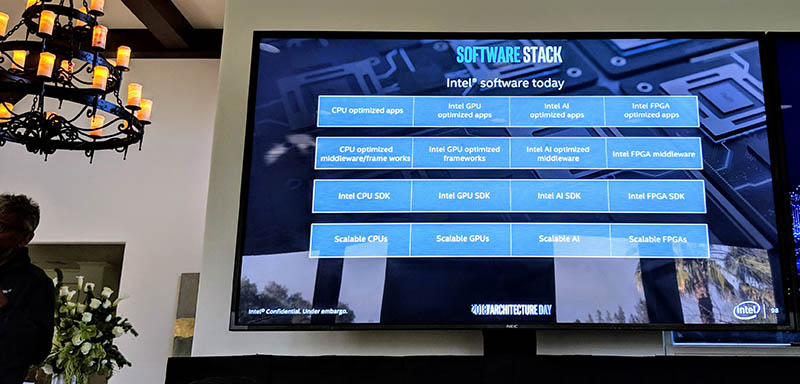
Intel is branding this effort and using OpenVINO as its model in the process. With OpenVINO, Intel was able to hide the complexity of the different hardware and software backends from developers.
As a quick note, you will see oneAPI listed here. Other places we saw One API, some OneAPI, and finally one API. We asked for clarification and did not get a firm response on any of them so we are going with One API here.
Intel plans to use its army of over 15,000 developers to optimize software stacks from top and bottom. For example, if a new machine learning framework becomes popular, Intel plans to use its developers to get tools like Intel MKL embedded in the process as early as possible.

The reason Intel is going the route of using a common API across products is that the company’s complexity would soon get out of hand. It already works on everything from drivers, to libraries and middleware, to application optimization throughout a number of product lines and categories. Instead of having to maintain very different APIs for different hardware, it can focus on developing software with a common API, and hiding hardware complexity at the back end.

Here is an example of the “One API” instead of oneAPI. The bigger part of this slide is that Intel believes this will make compute available to everyone. Bring your Tensorflow problem, and One API will help efficiently use hardware resources you may have available.

This is where companies are heading, and moving Intel’s large software team is going to be an organizational challenge.
Final Words
Conceptually, One API is what Intel needs to do. It is the way that the company can continue to chase larger TAM using different architectures. The next 10 years of computing will not be as x86 dominated as the last 10 years. Intel knows this and is why we are seeing a dGPU project along with Altera FPGAs and Nervana NNPs join the Intel silicon family. What we now have is an excellent, and much-needed vision for Intel to continue to add new architectures to its portfolio. What we need next is to see Intel’s execution on this vision.



{kind=link}
From a programmers perspective that sounds pretty vague and not at all useful. It would be far better to contribute to existing software, as it is usually done, instead of coming up with new, NIH libraries. Intel has done a lot of good work here, for example for OpenSSL, glibc and zlib. Getting these optimizations upstreamed is far more helpful to the whole installed base and developers who are already familiar with them. Find what people already use and then make it easy to accelerate it with Intel solutions. It’s a far better value proposition if you can just add an accelerator to your system, use your existing code (maybe link in or preload a new library that implements the same function calls) and have everything go faster.
Beta is out now. They didn’t reinvent the wheel. Looks like they extend Khronos Sycl and SPIRV.
One near term benefit will be that they’ll port several of their products to work on top of this so that, for example, OSPRay will get GPU backend.
They announced both Eclipse and Visual Studio development environment support, as well as a DevCloud environment where you can target the new accelerators.
Comments are closed.