
We are in Santa Clara today at the Intel Data-Centric Innovation Summit. We are going to take some live notes. Tune in here for updates and commentary as the summit kicks off. The event is going to cover a number of topics, so we are going to break each out into major categories.
Introduction
Navin Shenoy is on stage giving an overview of the day. The company is going to talk about next-gen processors, FPGAs, connectivity, AI plans.

Navin is saying that the company now has a 20% market share and expects that the company will have a $200M TAM by 2022 growing at 9% CAGR. Cloud TAM will make up 2/3 of the new TAM. Intel says 50% of cloud CPUs are now “custom CPUs”.
5G opportunity is a $20B+. There are over 1.5M cellular base stations sold per year. Intel is investing in a Xeon D rugged design with an Intel NIC and SSD to be deployed at mobile tower sites.

Intel Smart NIC is being announced today. Infrastructure offload features are being added.

Storage is going to move to QLC NAND for capacity tier storage (see Intel SSD D5-P4320 Data Center 7.68TB QLC SSD.) The bigger piece is going to be Optane Persistent Memory. We have started a section on this later in this article.
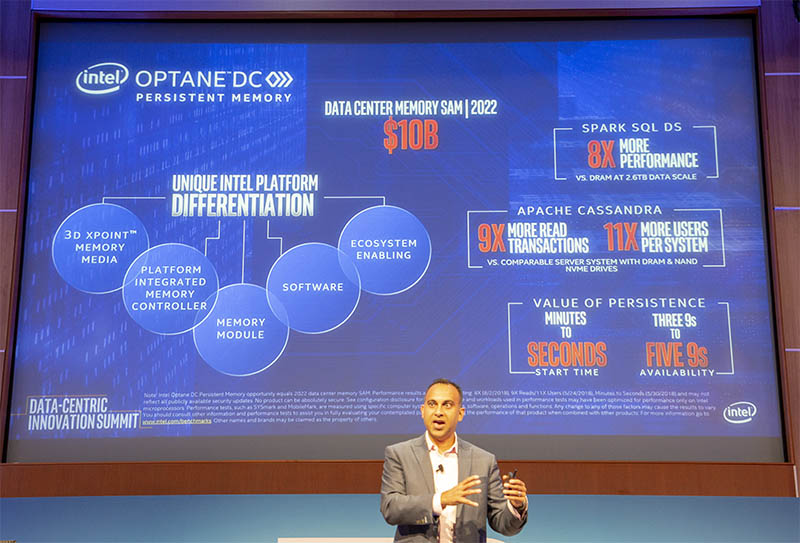
First production units of Optane Persistent Memory left the factory yesterday and is on its way to Google’s Cloud.
Intel Xeon is now 20 years old. Intel Xeon Scalable is 50% of Xeon volume today. Over 2M Xeon Scalable CPUs in Q2 2018. “This leadership is greater than a process node of leadership.”
Intel is investing in software framework updates to make CPU inferencing better. The idea is that if everyone has Xeon CPUs, they can use them instead of installing additional GPUs.
Jim Keller is on stage saying that the Intel 10nm and 14nm technology is good, but challenging to get out the door in production. We have more about the 14nm and 10nm products under Cascade Lake and Ice Lake.
Intel Self-Driving Car Update and Mobile Eye
End of 2018, Intel will have 2 million consumer vehicles on the road. It believes that this will lead to cloud sourced mapping. Current generation cars can only handle about 40km of maps. That will drive edge computing and storage so that automobiles will need to constantly download maps.
Next-Generation Intel Xeon Cascade Lake Shown
Already on stage is the next-generation Intel Xeon Scalable Processor codenamed “Cascade Lake” that we expect will be launched in Q4 2018 for large hyper-scale customers and Q1 2019 general availability.

We expect Intel’s Cascade Lake generation will still have 28 cores but bumped up clock speeds, additional Spectre and Meltdown fixes, and a higher price tag.
Intel Deep Learning Boost will be in Cascade Lake. Intel is showing inferencing performance increasing by 11x over Skylake generation servers.

This demo is showing an 11x increase in Resnet-50 performance over the Skylake-SP generation. This appears to be VNNI which Intel had on its Knights Mill HPC chips. You can read more about VNNI here: Intel Xeon Phi Knights Mill for Machine Learning.
Intel Cooper Lake Late 2019, Ice Lake 2020 10nm
Intel Cooper Lake is slated for late 2019 release. BFLOAT16 is a new instruction shared with Intel Xeon and Nervana NNP that will be in Cooper Lake. Cooper Lake, as we knew, will be a 14nm part.

Intel Ice Lake is confirmed as a 10nm part for 2020. We were told, although not on this slide, that Intel has the ability to add features such as PCIe Gen4 if its customers demand it outside of this roadmap.
Naveen Rao on Intel AI Portfolio
Naveen is discussing the Intel AI strategy. AI TAM in 2022 in $8B to $10B. Intel’s vision is that AI is going to be so big that “One Size Does Not Fit All.”

The majority of the work today is to work with training data. NVIDIA has a lead with the GPU, but Intel is aggressively moving in that direction. Naveen says most of the world’s inferencing happens on Intel Xeon. Naveen also says that the benefit of GPU there is more like 3x not 100x.
Intel Deep Learning Boost with Vector Neural Network Instructions (VNNI). These new instructions allow data to be processed with a lower precision. BFLOAT16 was originally published by Google. Intel is not saying this, but perhaps Google is a major Cooper Lake customer.

First commercial NNP in 2019. This will be the Intel Nervana NNP-L1000. 3-4x training performance over first-generation NNP. High-bandwidth low latency interconnects. bfloat16 numerics. Intel also just disclosed that there is an inferencing NNP coming as well. Intel is focusing on scale and actual performance over “theoretical Tops.”

50% of Intel’s AI products group is dedicated to software. Here is Intel’s view of software.

Intel says that the foundational libraries are not where most developers work. Instead, these are where the hardware vendors play, e.g. NVIDIA cudnn. Libraries are where data scientists play. Higher-level toolkits are for the application developers will play. As the abstraction level rises, it is accessible to more developers. nGRAPH is a deep learning compiler that Intel is focusing on to help developers.
As you move to larger images, you become I/O limited not parallel compute limited. Intel is working with Google to get MKL upstreamed.
Inferencing is often embedded in a workflow that runs on Intel Xeon instead of dedicated inferencing hardware. That dig at NVIDIA GPUs aside, Naveen earlier said that Intel is building a NNP for inferencing.

More on the next page. Breaking this up a bit to aid in loading times.



{kind=link}
The Ice Lake goal sounds pretty ambitious, given that Cannon Lake has been delayed again and again.
“This leadership is greater than a process node of leadership.”
I almost loled on that statement … they making this statement now when they are struggling with 10nm is a bit amusing.
So far this is just all marketing stunt, I’ll get excited when they’re about to roll it out.
AMD FTW!
Comments are closed.