
What happens when DRAM is too slow? To be more precise, what happens when going off silicon is too slow? Microsoft has a novel approach to doing high-speed inferencing: load a persistent model, using microservices, onto Intel FPGAs (Altera). If you are thinking “that is really cool”, it is. At Hot Chips 29, Microsoft showed a few of the tricks it uses to deliver high-speed inferencing from its infrastructure. One can also see why Intel bought Altera after the presentation.
Microsoft Deep Learning on Intel Altera FPGA
One of the first slides Microsoft presented was the overview of why they are doing deep learning on FPGAs.

The key here is that Microsoft is using FPGAs, and an architecture built around them, to deliver significantly faster inference performance. Here is how Microsoft views FPGAs:
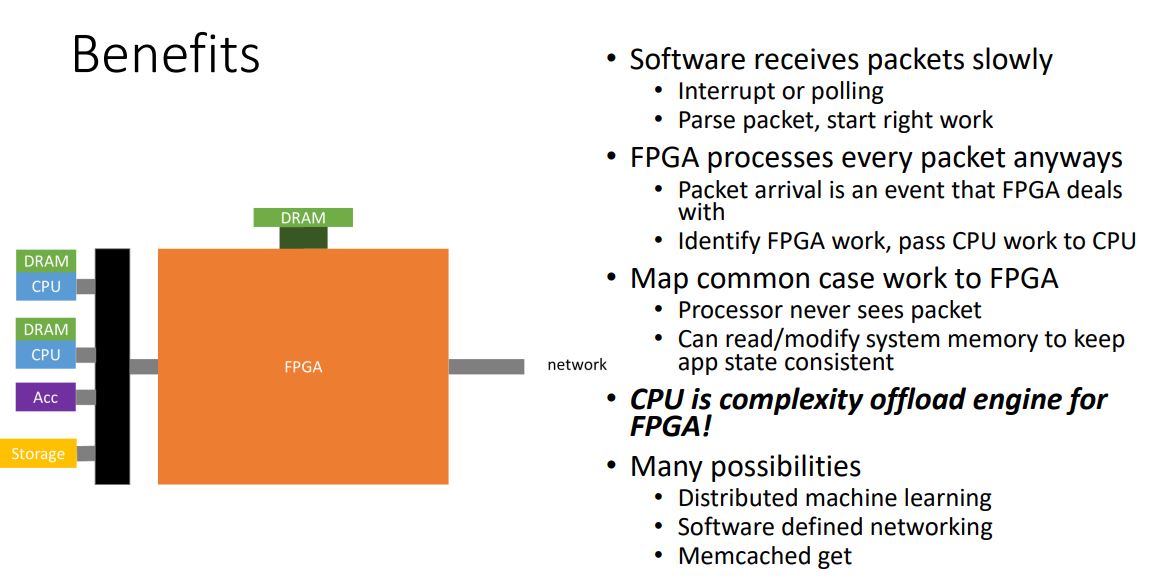
Microsoft is essentially using a microservices architecture to deliver low latency services via FPGAs. The variety of services being provided explains FPGAs v. ASICs clearly.
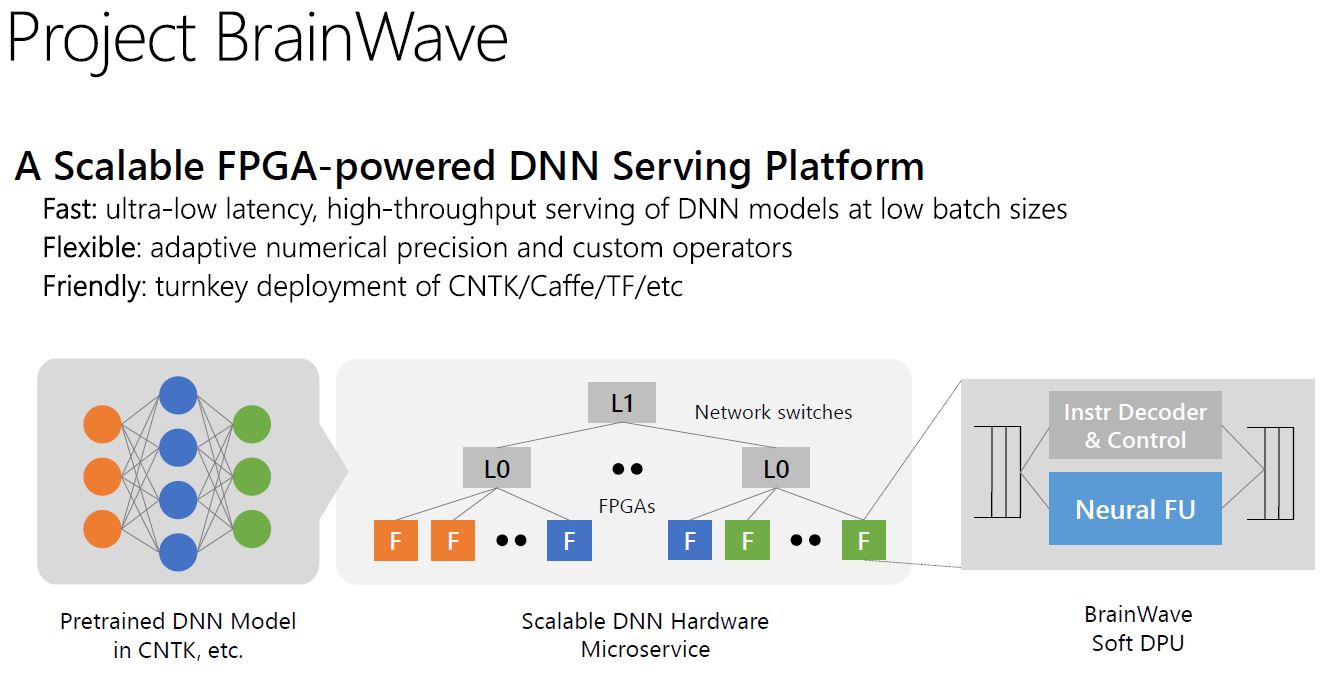
Microsoft Project BrainWave
Microsoft Project BrainWave is a DNN serving platform optimized for low batch size, low latency processing using FPGAs.
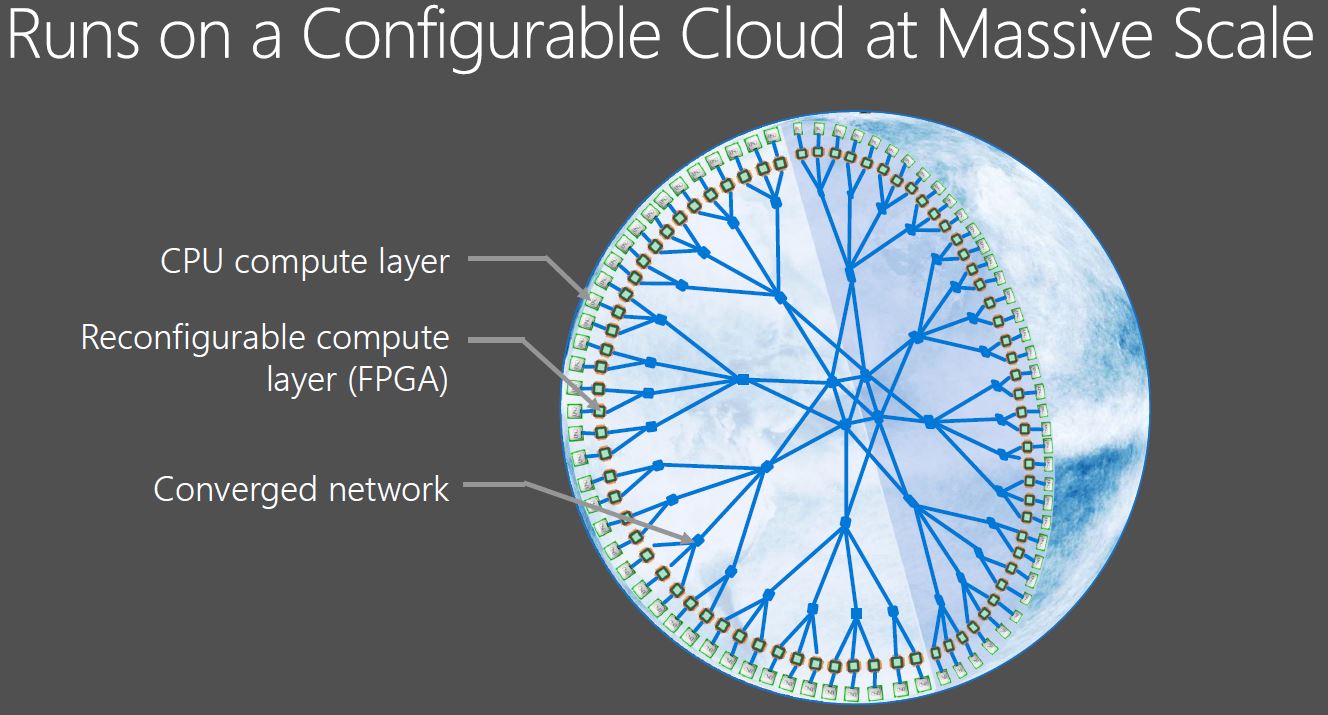
Here is a view of the Microsoft cloud. Underpinning the entire system is an ultra low latency fabric that supports distributing work efficiently. The endpoints are the CPU layer at the outer edge and FPGAs just on the inside.
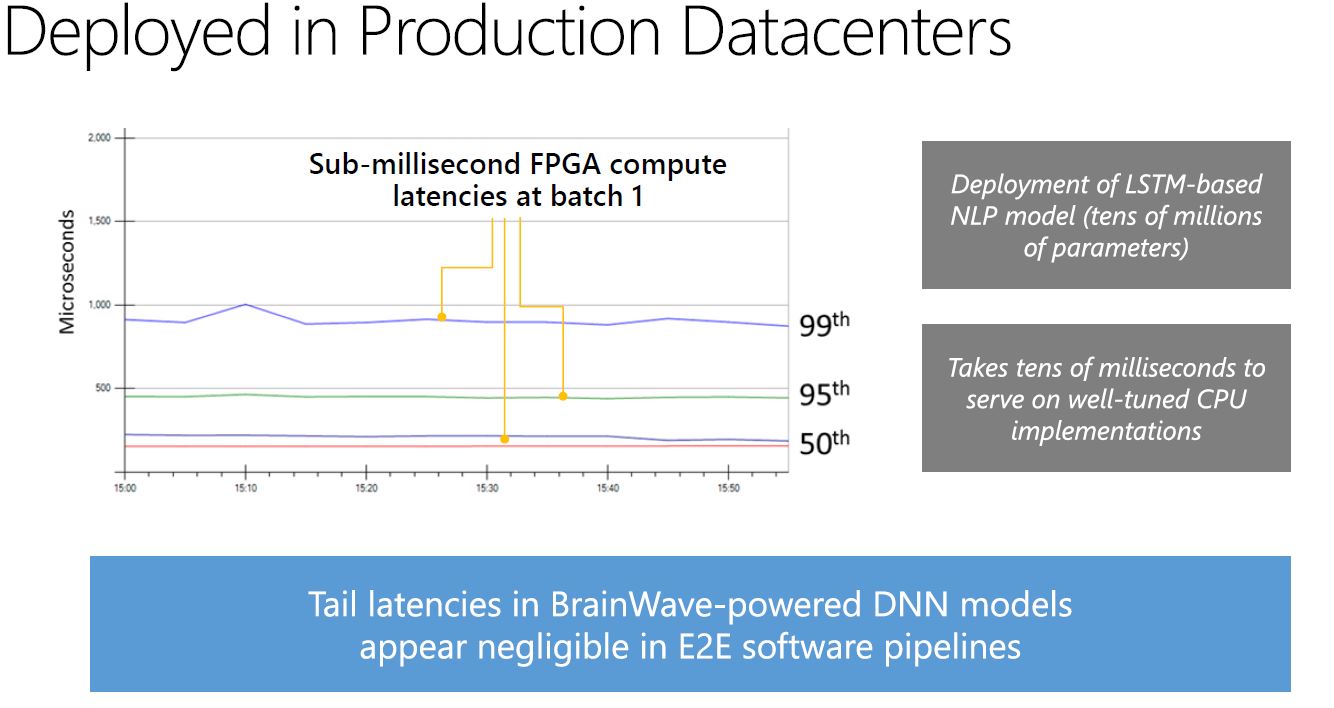
What is the impact of using FPGAs over CPUs? Low latency low batch size.
How Microsoft BrainWave Works
In terms of the actual implementation, the Brainwave stack is a very customized solution that was designed end-to-end to deliver this kind of performance.

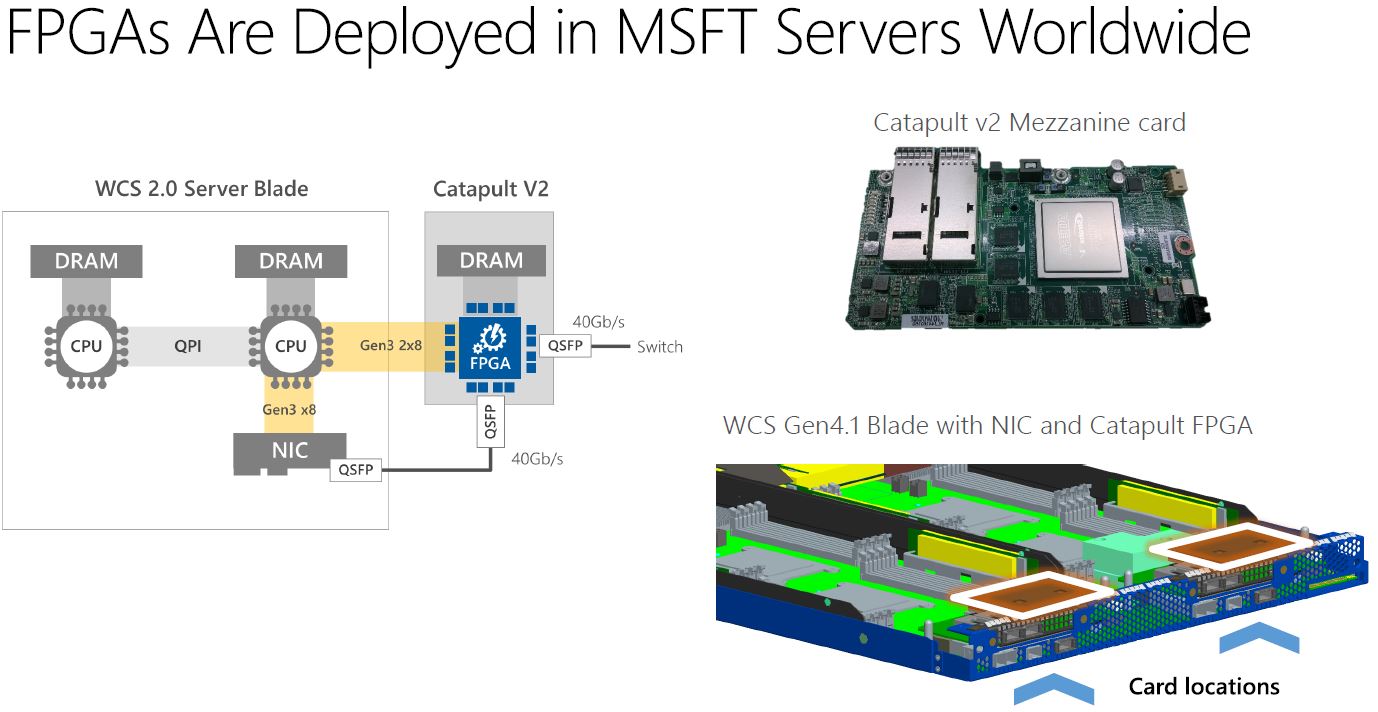
Here is what an Altera Stratix V era Catapult v2 deployment would look like for Microsoft. One can notice that the FPGA has its own 40Gbps QSFP NIC ports. These are clearly older modules that Microsoft is giving insight into.
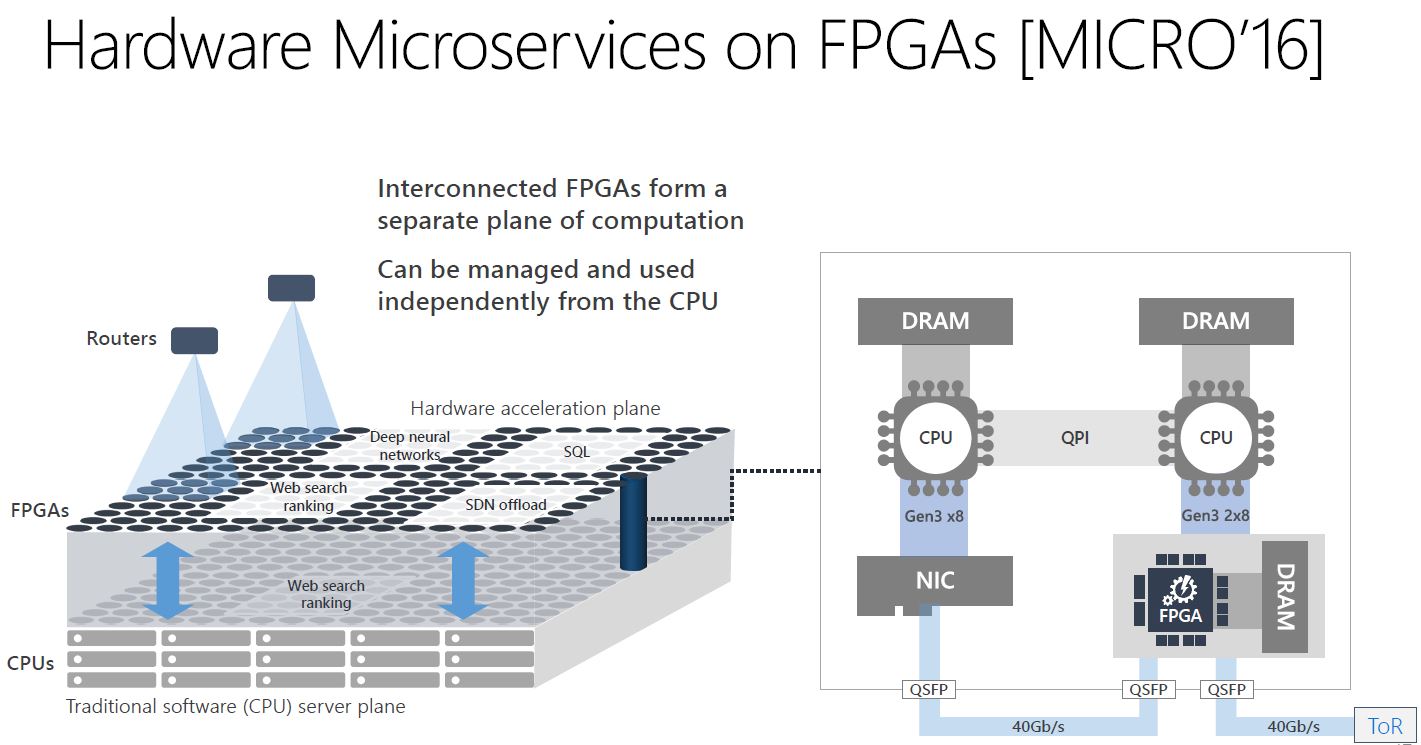
In terms of the impact of FPGAs, Microsoft was going well beyond DNN acceleration. One can see a number of other applications including SQL and SDN offload in the chart.
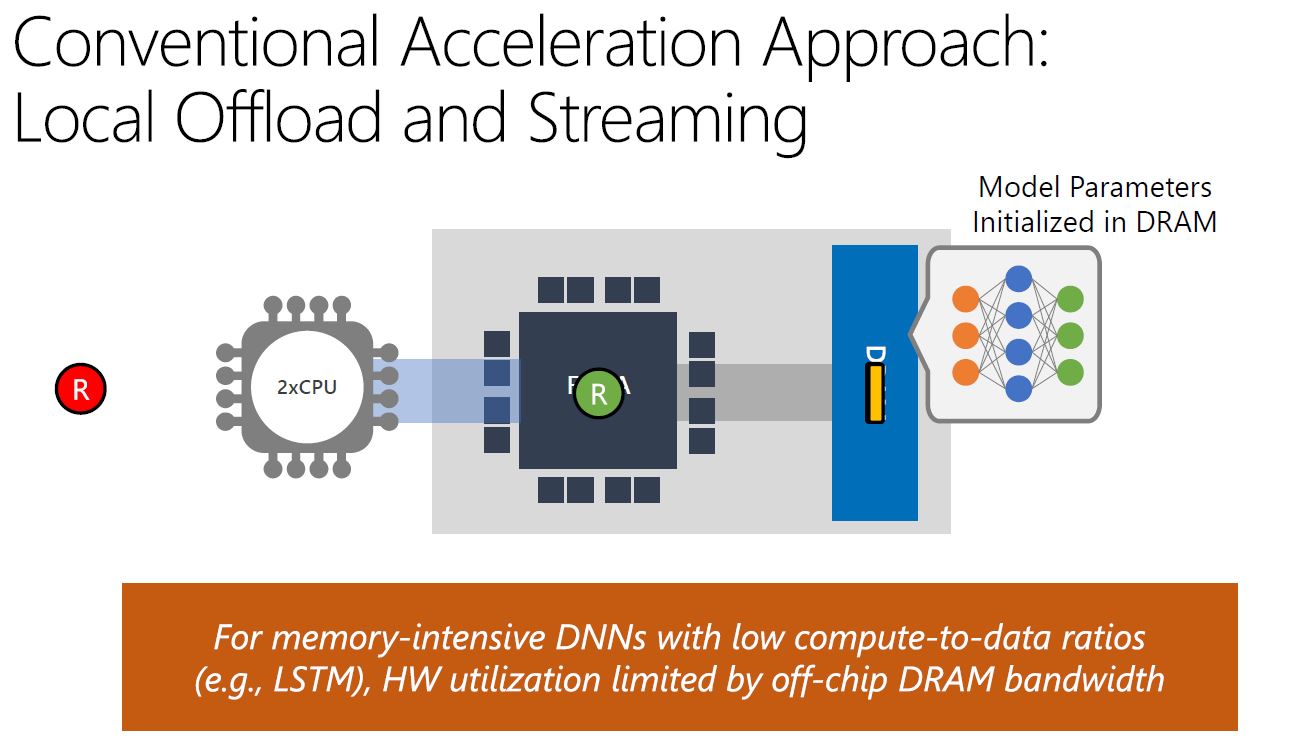
Microsoft ended up here because it found a large set of DNNs where hitting model parameters in DRAM was severely limiting performance.
Instead, Microsoft is persisting model parameters in FPGA on-chip memory.
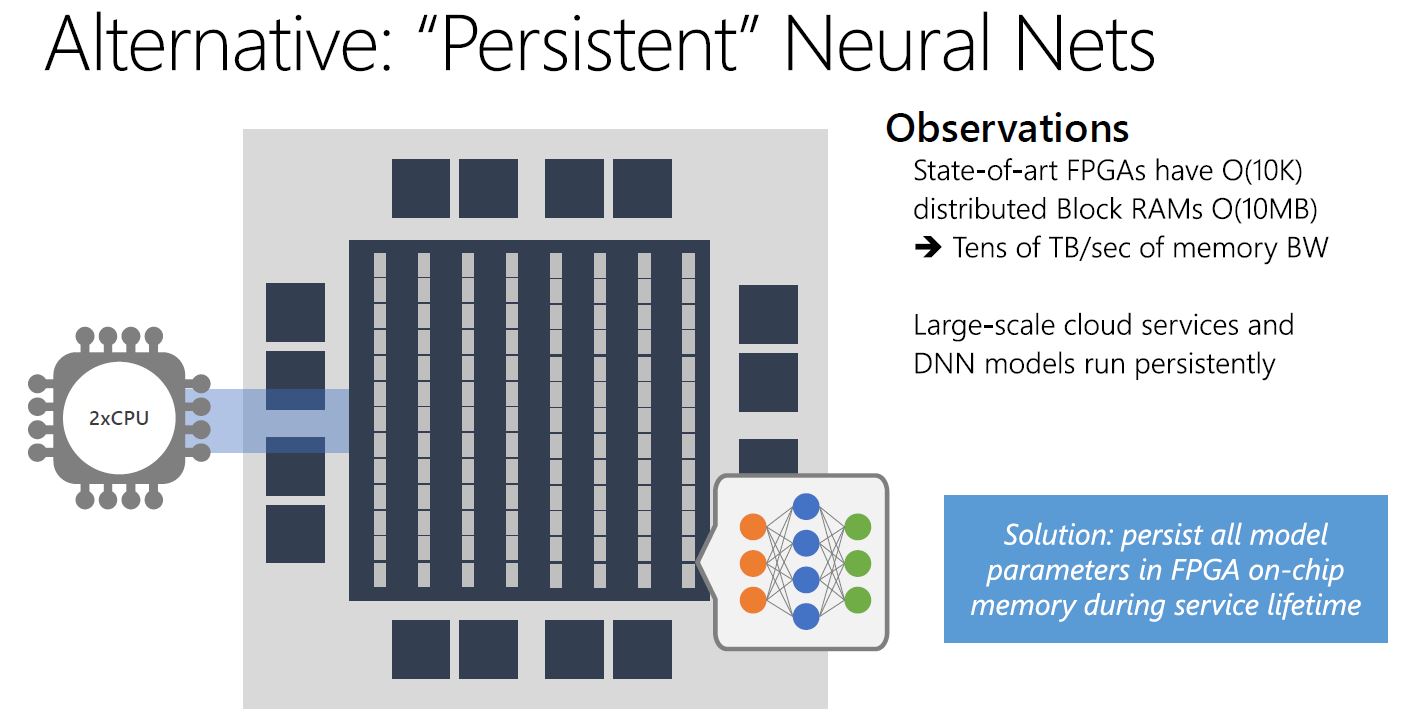
When you have the scale, that means you can persist model parameters in FPGA memory in the data center and run DNNs as a microservice. This is something that is simply not practical to do at a smaller scale.
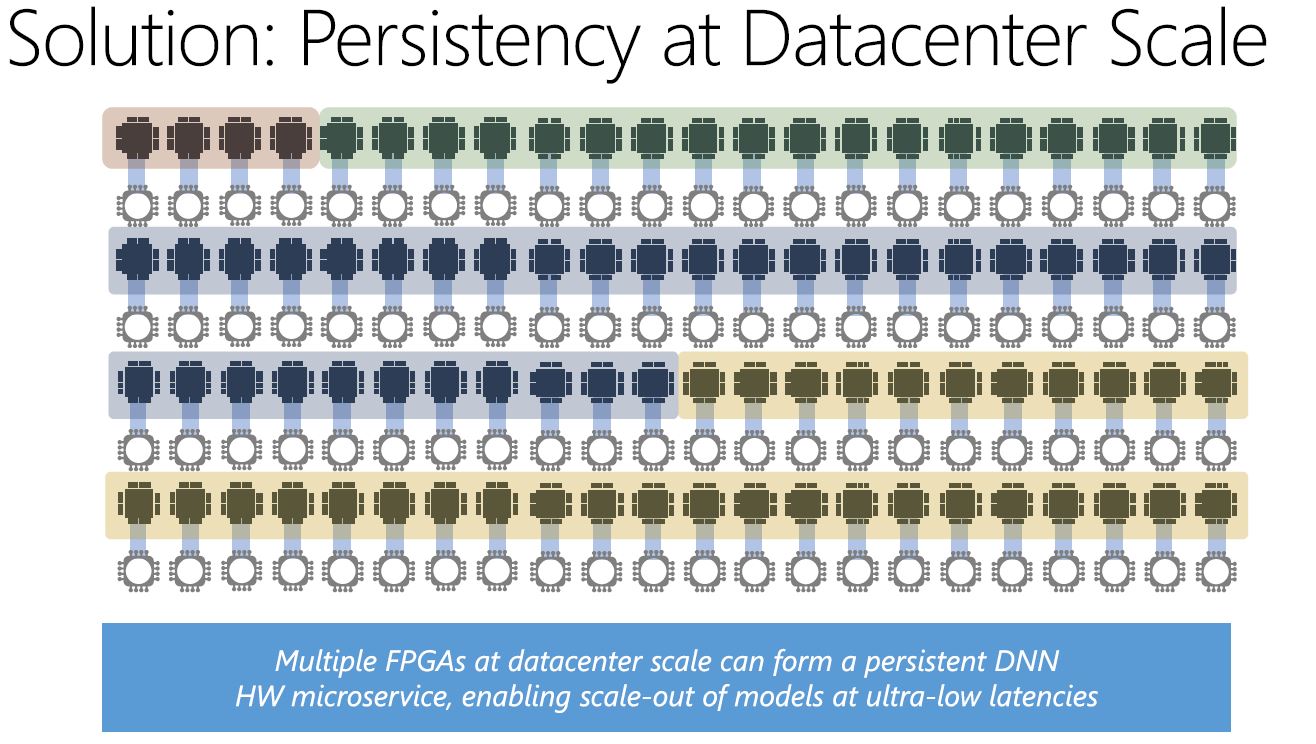
With the high-speed network, and connecting FPGAs directly to the network, Microsoft can deploy these microservices so that one FPGA can run multiple parts of different models and one model can run across multiple FPGAs. Once the model parameters are loaded, there is no longer a need to hit DRAM and this acts as an extremely fast processing engine.
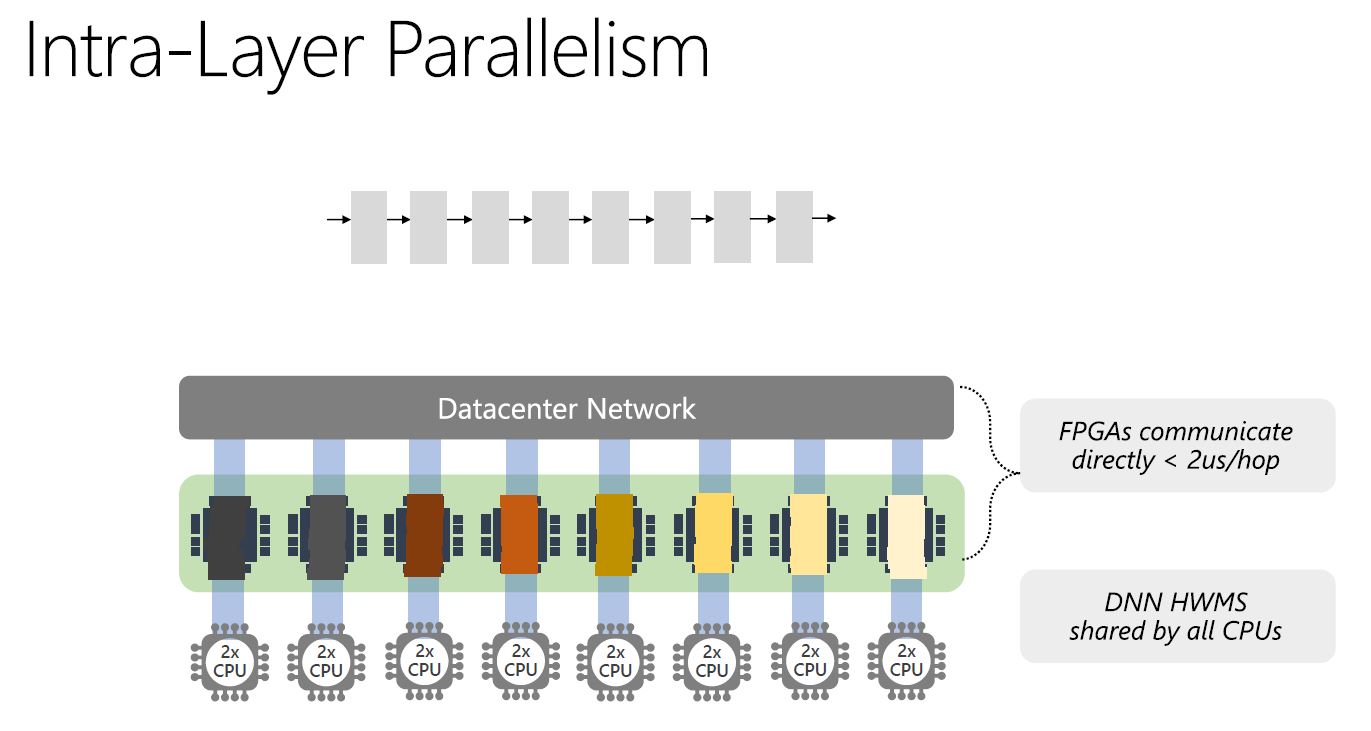
Overall, with this level of usage, it is little wonder why Altera was acquired by Intel. Microsoft benefits also by the fact that FPGAs are reprogrammable. That means that there are benefits over Google’s TPU ASIC approach when it comes to using hardware for new structures.
Microsoft BrainWave DPU Architecture
A key component in the BrainWave stack is the Soft DPU. Microsoft’s slide does a good job explaining the key features:

Here is the microarchitecture slide:
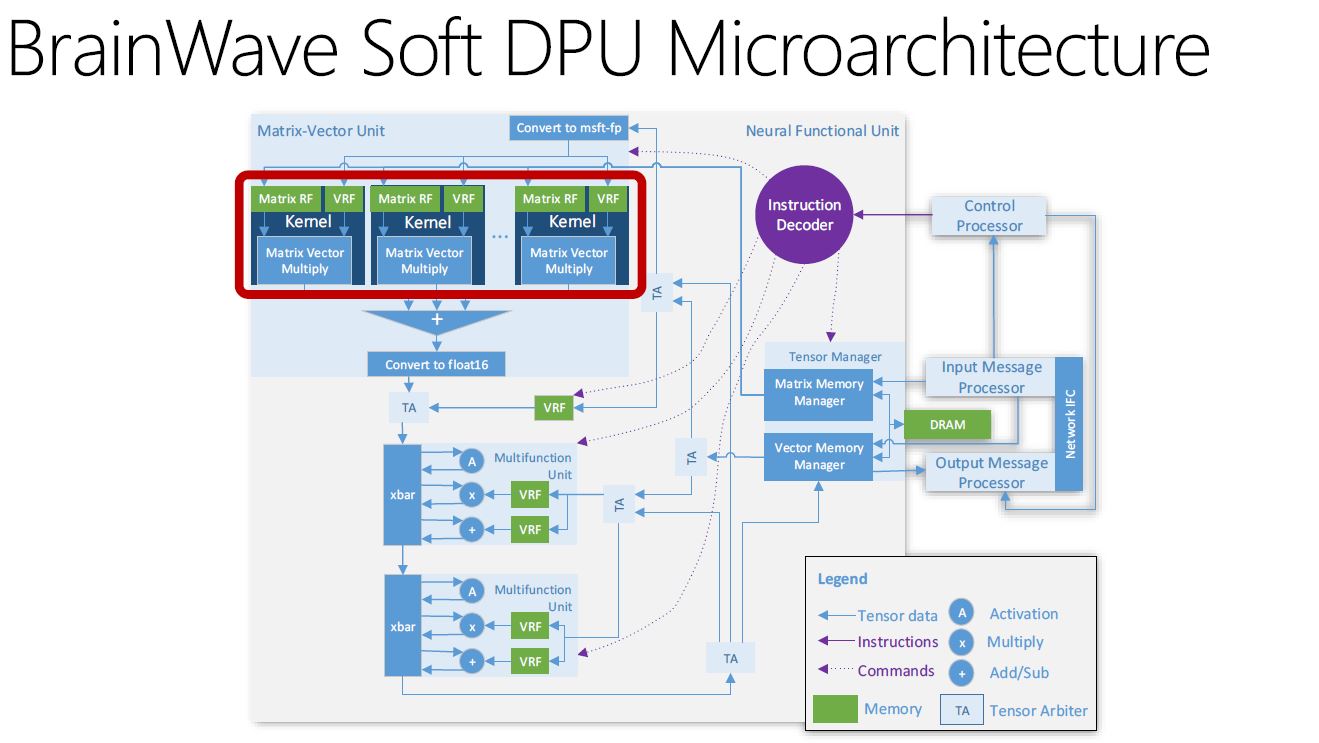
One of the key components is the Matrix Vector Unit. Here is where Microsoft is using msft-fp (its own floating point implementation) to achieve additional performance.
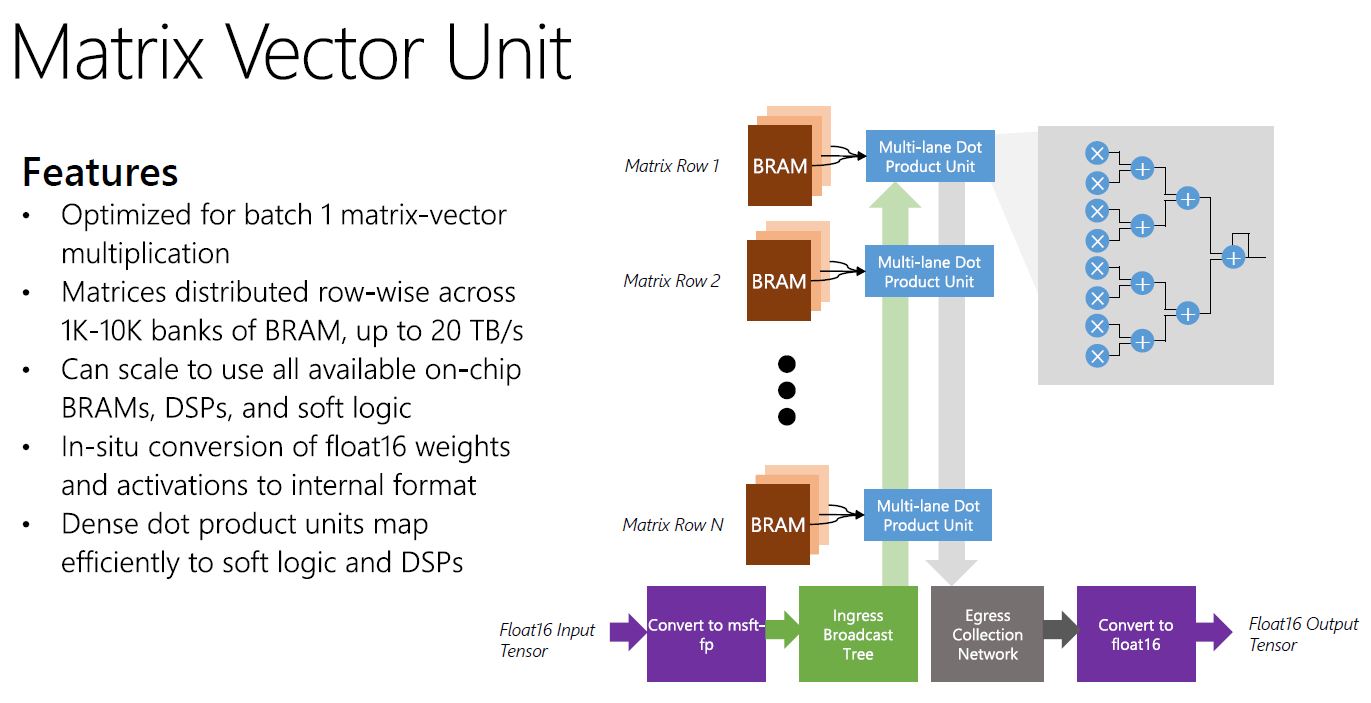
The idea here is that Microsoft can create different MVU tile arrays on FPGAs based on model needs.
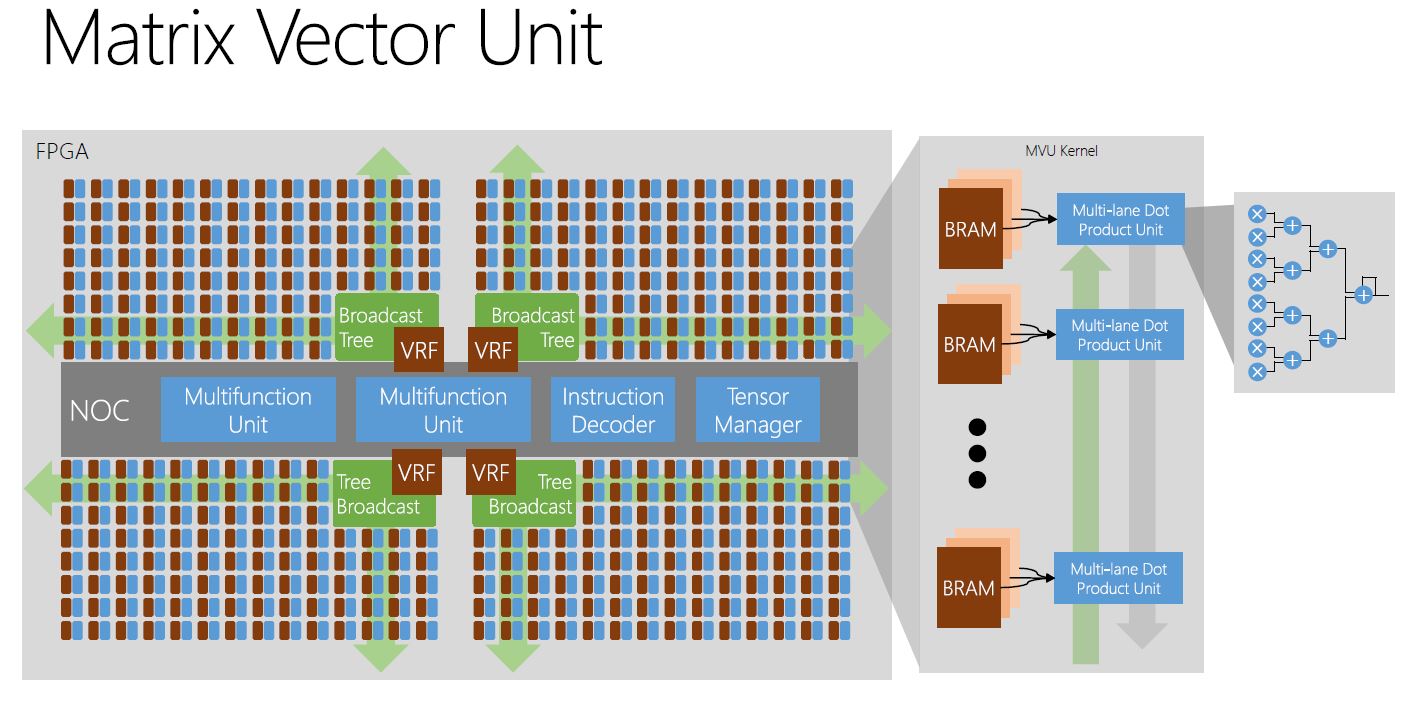
Now for why this matters and where it is going.
Microsoft BrainWave FPGA Powered Performance Ramp
Here is the Altera Stratix V versus the new Stratix 10 FPGA performance.
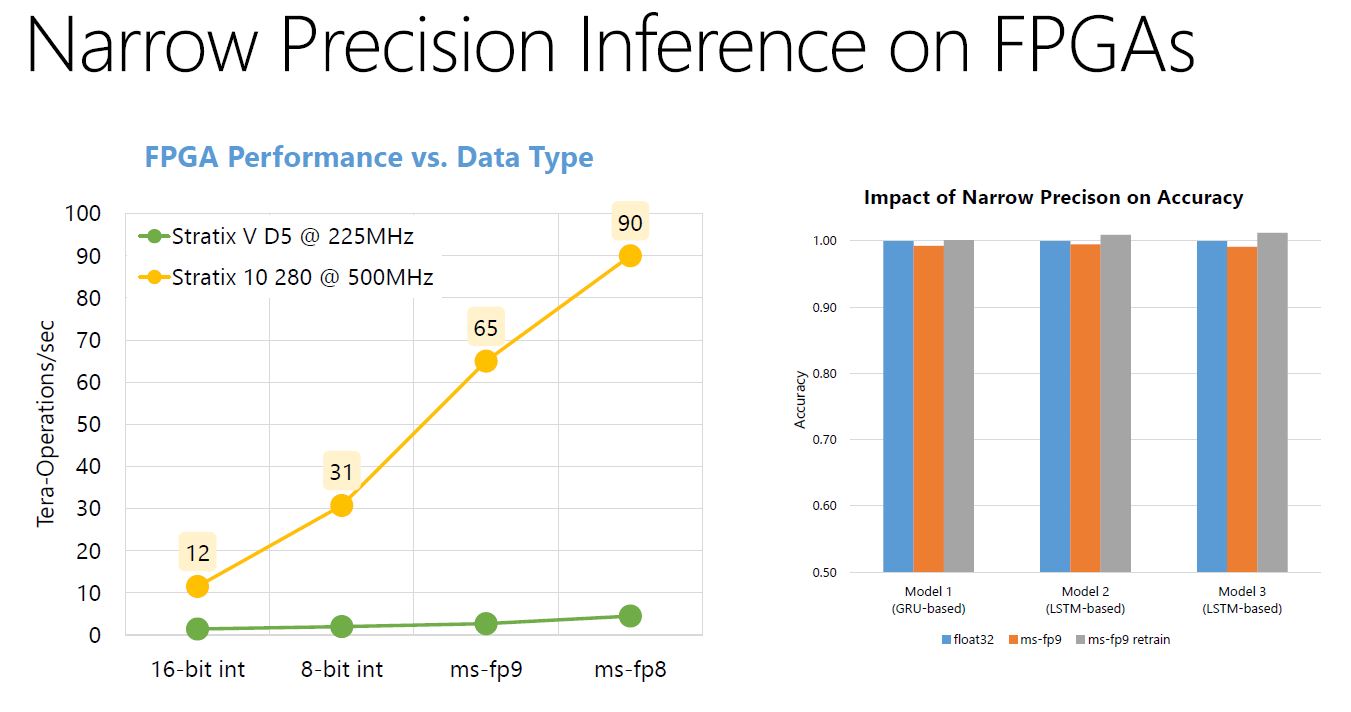
As you can see, performance is ramping significantly. There is little doubt that Stratix 10 had input from Microsoft that helped shape this performance improvement.
Here Microsoft is showing the Arria 10 to Stratix 10 (early silicon) performance improvement. On the right side of the chart is something interesting as well. This is how the Microsoft BrainWave Soft DPU is distributing MVU Tile arrays on a Stratix 10 280 FPGA.
Final Words
With Google building its own ASICs, many companies like Baidu and Facebook are relying heavily on NVIDIA GPUs, there is a quest to solve deep learning and inferencing problems with architectures beyond the CPU. Microsoft’s implementation is intriguing because it leverages a high-speed network and on-chip memory to achieve a persistent, low batch size performant, engine on FPGAs. This is something that Microsoft can do simply because of its scale. For startups, this type of architecture is relatively difficult to produce because it requires the scale that makes starting on NVIDIA GPUs significantly more viable. Still, it is a great window into how one of the largest hyper-scale shops is building its infrastructure.



{kind=link}
Yeah…
Well now guess why there are 4 Google TPUs 2 on their motherboards and why they have heavy networking IO?
Maybe to do exactly the same kind of splitting at an even faster speed?
Good try Microsoft, but Google is still ahead.
Skynet is taking over soon (or the matrix or whatever you want to call it).
Comments are closed.