
Graphcore has a new AI chip out, it dubs the BOW. The Graphcore BOW IPU adds more performance at a smaller bump in power and at the same price. Let us take a look at what is offered in Graphcore’s new chips.
Graphcore BOW IPU Launched
Graphcore is getting into the more advanced packaging model with the BOW IPU. Specifically, the BOW IPU’s major advancement is stacking additional power delivery with the Colossus Mk2 die.

As you will see, the new chip has 0.9GB of in-processor memory. This is in-line with industry expectations as we discussed in June of 2021 with our Server CPUs Transitioning to the GB Onboard Era piece. Graphcore is using 0.9GB here instead of a MB designator as it did previously.
We will quickly note that Graphcore’s design uses local memory instead of memory like HBM2(e) as NVIDIA/Intel server GPUs and other accelerators use. This trades capacity for bandwidth and latency due to the proximity. Graphcore is using the stacked wafer technology to help power delivery and thus clock speeds. This is using TSMC’s SoIC-WoW technology. It is a bit different, but conceptually the task is accomplished similar to how AMD EPYC 7003 “Milan” was the base version with “Milan-X” adding additional memory via stacked cache. That is not a perfect analogy here, since they are accomplishing different tasks and using different methodologies, but thinking of this as scaling chips up in 3D instead of out in 2D is the fundamental concept.
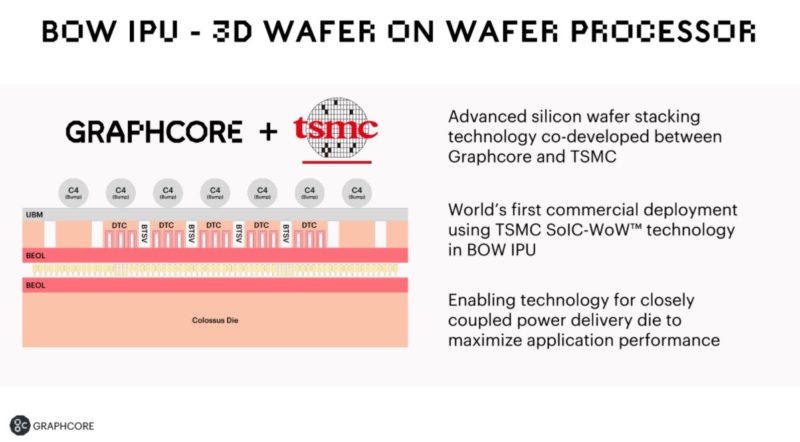
Here is the additional detailed diagram about what Graphcore is doing:
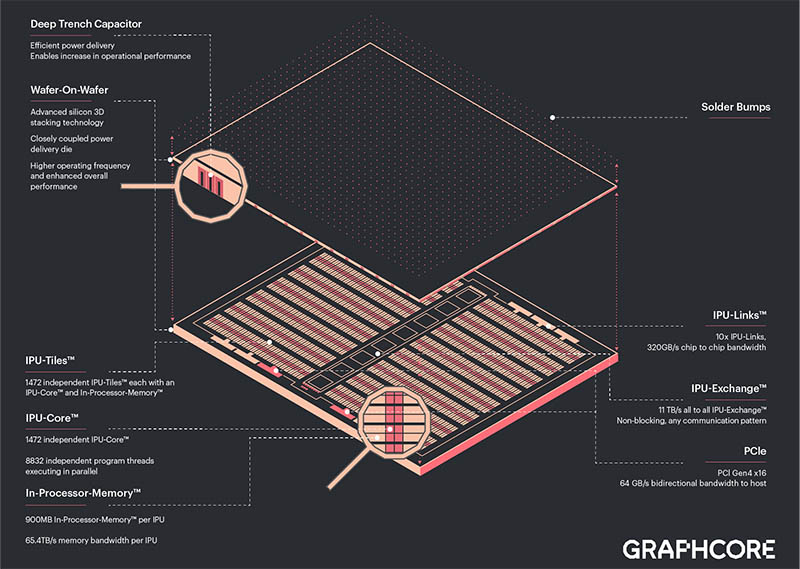
Below, for reference, we have the previous generations of chips. What we effectively get is higher clock speeds with the new generation, but this is otherwise similar to the GC200 chip in many ways.

Each IPU sits four to an IPU Machine. In this case, it is the BOW-2000 IPU Machine.

Graphcore sells these systems from small to large configurations along with a server to manage multiple IPU machines in what it calls PODs.

Graphcore’s <1GB of on-package memory means that it is focusing on using a smaller model to train versus NVIDIA. It is also discussing four IPU machines, each with four BOW IPUs, plus the server to a DGX-A100 640GB that has eight 80GB A100 GPUs. The older IPU-Machine M2000 used 1.1kW typical each, and since the performance is up 29-39% and the efficiency is up only 9-16%, we expect the BOW IPU Machine power consumption to increase from the 1.1kW typical model. A dual AMD EPYC CPU 1U server can use 750W-1kW fairly easily, especially if it is a 64-core design like NVIDIA’s A100 systems (and many deployed HGX A100 8 GPU systems use.) It feels like Graphcore is only looking at BOX costs for its TCO, not actual TCO that includes things like power consumption, networking, software, and support. Having NGC is a non-trivial part of TCO of one of these solutions. Maybe instead of TCO, it should be “performance per hardware purchase” or a similar metric.

Also, as we noted in Graphcore Celebrates a Stunning Loss at MLPerf Training v1.0, the company is still using the DGX A100 for its comparison rather than partner machines. We have looked at the Inspur NF5488A5 8x NVIDIA A100 HGX Platform Review and have also seen the impact of liquid cooling on these systems. We also recently saw that even in relatively lower-power dual CPU servers fans can take 15-20% of power which is why liquid cooling in accelerated systems is becoming more common since accelerated systems can see even higher power consumption due to fan cooling. To some these may seem like small things, but the 2022 generation of accelerators will either need to be liquid-cooled or will have to be lower performance options, so it is notable Graphcore is still using air cooling.
Performance is up 29-39% across its basket of workloads. Graphcore tends to fare poorly on MLPerf training, but that is also partly due to it being a NVIDIA-heavy benchmark. It is good to see the company focusing its marketing efforts elsewhere where it can show better results.
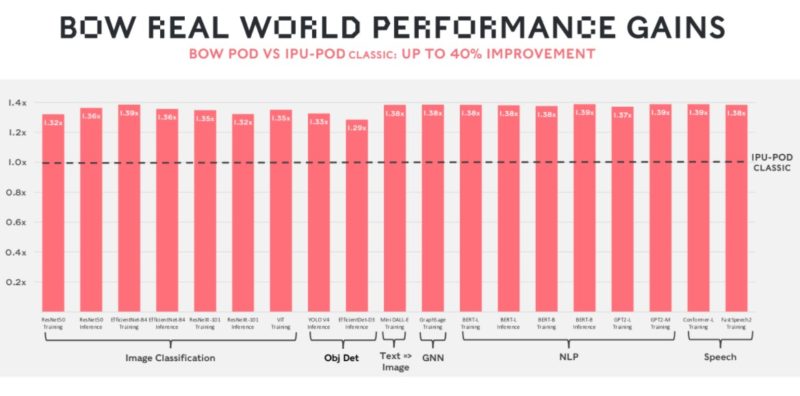
As mentioned previously, the 29-39% performance gains do not translate into 29-39% power efficiency gains so we can extrapolate that the new solution is using a bit more power.
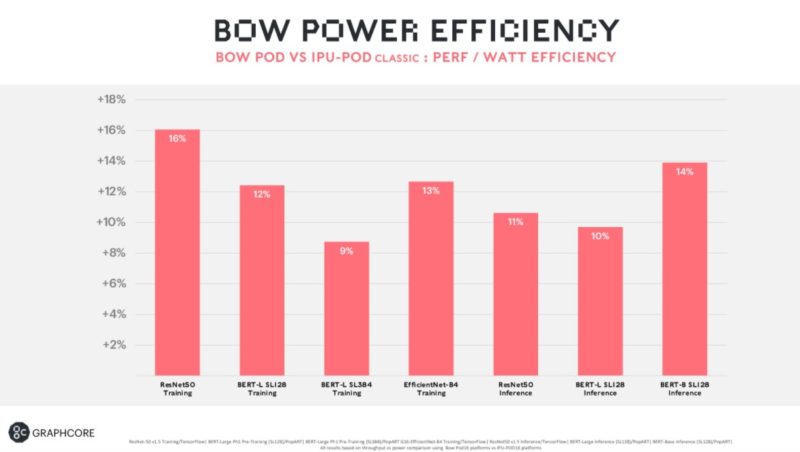
Graphcore also shows its scaling to multiple systems. For large AI clusters, this is important.
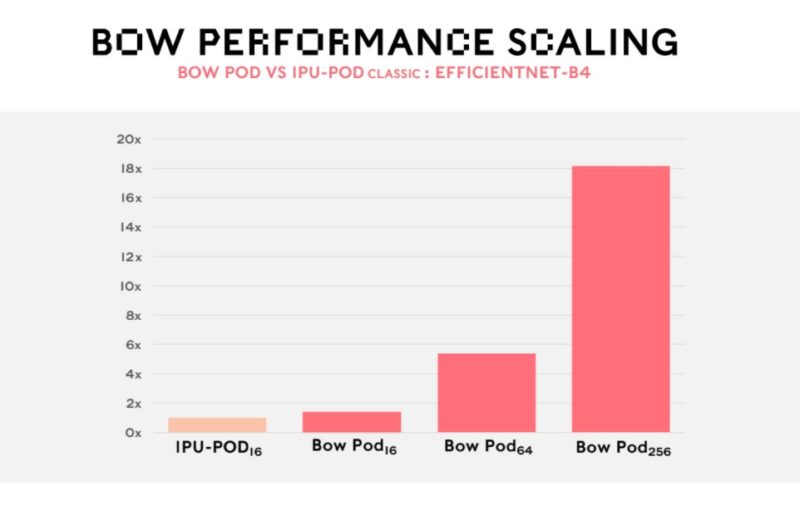
Overall, it is great to see Graphcore was able to basically increase its chip’s performance using new packaging.
Final Words
At this point in the journey, we need to take a step back. Graphcore is now 2-3 generations in, and its customer list is OK but is a far cry from where NVIDIA is, and where Intel will be in 12 months. Notably missing are the leading edge AI hyper-scalers like Microsoft, Facebook, Google, Baidu, and so forth. That is not bad, but it likely means that the market has figured out Graphcore has a more niche solution than NVIDIA. The market is large, and having niche solutions is OK, but we need to level-set here.

Perhaps the most troubling part of Graphcore’s announcement is simply the timing. We are weeks away from GTC 2022. There, we fully expect to see a new architecture from NVIDIA as the A100 has been out for a long time.
A few years ago I had a very small early investment in a company called Zume Pizza that was focused on making and delivering pizza via robots. I remember the day that I looked at the valuation and spoke to another investor and said “does it feel like we are invested in the world’s most overvalued local pizza chain?” Zume failed a few months after we both exited.
As a more general comment, Graphcore feels like Zume Pizza. It has huge amounts of investment and high valuations. Adoption is limited even after a decent amount of time passes. There are strong competitors with better positions and that are much larger. It is also hard to figure what company would buy an AI chip startup with a massive valuation that struggles against its biggest competitor even after three generations. If it was truly a best-of-breed solution, AMD, Marvell, Broadcom, Microsoft, Facebook, or even Intel would have already purchased them. It feels like the viability of Graphcore, at present, is tied to VC funding in a long-running bull market. That, in turn, will keep some customers away, thus continuing the cycle.
While the BOW IPU is a good development, we hope Graphcore has something better planned for 2022 before VCs get forced to review portfolios if the economy cools. The market needs competition and three years ago we were hoping Graphcore would be it.



{kind=link}
All I can think is how this should be called the “Graphcore Bow-WOW”, cause its performance is for the dogs.
Not really /* commenting */ on this device, just on the onboard memory (.9 GB).
In 1994/1995 I was having some issues with drives in a large-ish Sun server dying much sooner than expected…I distinctly remember Sun sending me a large supply of 1-GB hard drives.
Progress this would seem to be.
Like Patrick, I also feel that this BOW IPU is “too little too late”. People buying these kind of large AI supercomputers train trillion parameters datasets, which is exactly the target of Grace/Hopper, and it’s where the on die BOW SRAM is not enough. Or maybe I miss something…
Comments are closed.