
Google is now the first major cloud provider to offer NVIDIA A100 instance support, at least with its alpha instance launch. Google Compute Engine now has (in alpha) the Accelerator Optimized VM A2 instance family powered by NVIDIA A100 GPUs. One may remember that the NVIDIA A100 family, the company’s Ampere architecture successor to its Volta V100 generation, just launched a month ago. In the announcement, we got a few insights into how Google is deploying the A100.
GCP Accelerator Optimized VM A2 Instances with NVIDIA A100 GPUs
While Google Cloud announced that Google Kubernetes Engine, Cloud AI Platform, and other Google Cloud services will get NVIDIA A100 support in the future, we now have a general-purpose A100 instance. At first, we thought that this was a deployment of the new NVIDIA A100 PCIe add-in card but it does not appear to be the case.

In the new Alpha instances, Google Compute Engine allows customers to access up to 16 A100 GPUs. The a2-megagpu-16g instance uses 16x NVIDIA A100 GPUs and is connected via NVSwitch. With 16x GPUs using NVSwitch, we do not have a PCIe system, nor a set of smaller NVIDIA A100 4x GPU HGX Redstone Platforms. Instead, we have a full NVIDIA HGX-2 Design that is effectively two NVIDIA DGX A100‘s.
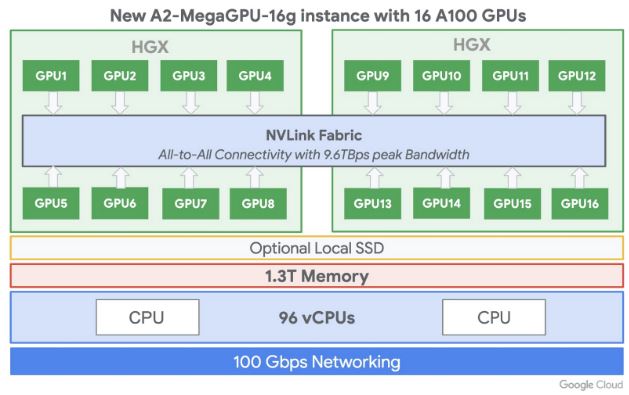
At STH, we recently reviewed the Inspur NF5488M5 with 8x NVIDIA V100 based on HGX-2. The Google deployment is effectively two of these HGX-2 baseboards, updated for the A100 making it similar to a NVIDIA DGX-2 updated for the NVIDIA A100 generation.
Final Words
The Google Cloud NVIDIA A100 announcement was widely expected to happen at some point. NVIDIA had Google Cloud on the HGX A100 slide. What is very interesting is that they only showed the 8x GPU HGX A100 unit, not the 16x GPU HGX A100 at the time. Clearly we can now infer that if Google is deploying 16x GPU servers that others may be as well.

We expect other cloud providers to launch their NVIDIA A100 offerings in the near future since once one cloud provider launches, the others tend to follow. Of course, this is an “alpha” launch, not a full general availability launch. Google and NVIDIA are trying to notch a quick win with this announcement. Still, for those who are eagerly awaiting the new NVIDIA A100 chips on cloud platforms, the wait is either over or nearing being over as the announcements have started.
Here are the instance sizes for the new A2 instance family.
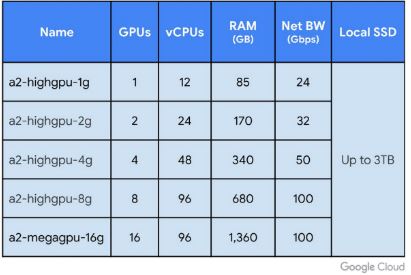
(Source: GCP Blog)



{kind=link}
This offering might cause a crysis over at AMD.
@hoohoo
Why? because they deliver the CPU’s (EPYC7742’s)
@Misha,
Threadrippers. To deal with a crysis, you want to take Threadripper…
@Misha
I didn’t want to reference Crysis frame rates directly, STH being a serious site.
I wonder if all instance sizes are run on 16 GPU systems, with the smaller ones being cut down at the virtualization level; or if there is some hardware variation.
Homogeneity is presumably a virtue for a cloud operator; but, depending on how much NVswitch adds to the cost, having separate node types for the 1, 2; and 4 GPU options might make sense since those can be hosted on the unswitched pure NVLink option.
It looks like RAM scales as an exact multiple of number of GPUs; but number of vCPUs is higher per GPU on the 4-and-smaller options.
@Misha Engel
Are You sure? As we know 8x GA100 are connected with 2x Ice lake xeons
https://wccftech.com/intel-10nm-ice-lake-sp-xeon-cpu-nvidia-ampere-a100-gpu-7nm-servers-spotted/
Daniel
That is an Inspur system – and it does use Ice Lake SP – the dual socket config matches the Epyc system where it matters (I/O). The CPUs – whether AMD or Intel are nothing more than traffic cops and job schedulers – the computational capabilities are not used in conjunction with the GPUS. Nvidia likely chose AMD solely because their launch windows was a little early for Ice Lake SP. Not to mention that Nvidia is a bit more worried about Intel invading it’s space than AMD. The Nvidia branded DGX Ampere systems use the AMD Epyc.
Both the Ice Lake SP and the Epyc are limited to 2 sockets, expose 128 PCIe4 lanes, and use 8 channel DDR4 3200 ECC. The increased computational efficiency in the Ice Lake Sunny Cove likely negate any “benefits” the 128 core system possess.
We have a test 8 GPU DGX-A100 installed, but not yet powered on – which will happen Monday – we will test it head to head against one of our DGX-2 with 16 Volta “next” GPUs over a ~2 week time. I have tasked the other engineers to have several of the sims they run regularly to be ready to go into the scheduler.
The Nvidia rep intimated that the AMD system is in no way custom, or attached in any way other than the PCIe interfaces to the GPU “cube” as he called it. So I would imagine swapping out the AMD with Intel would not be a hassle. When we do get our production machines, IF there is an option for Intel we will take the Intel. It just isn’t an issue.
What struck me was that a 16 GPU Ampere system will use the same 12KW as our current 16 GPU Volta “next” machines – amazing considering the increased computational power.
We will either keep the same time window for certain simulations with increased fidelity or will decrease the time window with the same level of fidelity we have now.
The upgraded DGX systems coincide with a network overhaul. Dual homed 400Gb/s backbone (Cisco Nexus 9316D Switches), with backhauls (7.5KM and 2.8KM) going from 10Gbs/x2 to 100Gb/s x2 over the installed SMF. Servers will be moved from 40Gb/s to 100Gb/s and the last vestige of our Infiniband infrastructure will be the 8x40Gb/s IB on our large SGI TP16000 Array – the IB will be converted to 40Gb/s Ethernet with a Mellanox SX6710G Gateway – with an eventual replacement / retiring of the SGI. Servers are currently Xeon 1st gen Scalable – and will be replaced 1st half of next year with Ice Lake SP systems, the 3 existing smaller flash arrays will be replaced late this year and will go from PCIe3 Optane to PCIe4 Optane drives. 1st upgrade after the network/compute will be replacing 66 Intel NUCs of various generations with Tiger Lake NUC11s (not having any computational issues – issues are with video) – 2.5Gb/s will be existing copper (CAT7 in wall) to a Cisco switch with a pair of Cisco Nexus 31108PC-V switches with SFP+ transceivers to copper. 10Gb/s ports are cheaper and with a higher density than anything we could find with 2.5Gb/s line speeds. Would be willing to pay a premium for an Intel NUC with an SFP+ network port – and ditch the last bit of non PoE copper.
Comments are closed.