
Compute Express Link, or CXL, has been a technology we have been waiting on for many years. To be fair, CXL already exists and is useful in products. At the same time, I think most in the industry, going back to 2019, would have assumed that this would be a bigger part of the technology landscape by 2024. In 2025, it will likely move from a very niche technology into the realm of a technology we start to see used regularly.
CXL is Finally Coming in 2025
In 2019, we covered the first big talk on CXL after it was announced, just as Intel started to transition the technology from inside the company to a consortium. For some context, in Q1 2019, AMD had not yet released the AMD EPYC 7002 Series “Rome”, NVIDIA was not moving the entire market with AI chips, and Intel was really in the driver’s seat where it could offer these types of technologies to the industry. Just as a fun one, at its April 2019 Interconnect Day, Intel’s interconnect chart had a lot of Ethernet. This was around the time of the failed Mellanox bid. If you want to hear more about how Jensen and NVIDIA outplayed Intel for Mellanox, we finally went into it in our Substack. The other big one is that CXL/ PCIe was given precedence here over a scale-out UPI alternative like NVLink, UALink, and so forth.
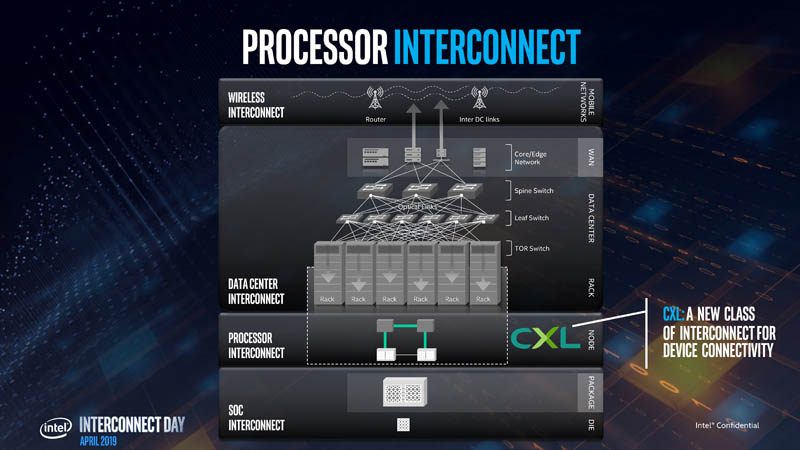
Still, by 2021, it was clear that CXL had won and we were rapidly approaching productization. We did our Compute Express Link or CXL What it is and Examples piece. Folks to this day still tell me they use this article and video.
Some interesting things happened after that video. First, AMD EPYC Genoa arrived in 2022 with CXL support for Type-3 memory expansion devices. For Intel’s part, its 4th Gen Intel Xeon Scalable “Sapphire Rapids” launched without that CXL Type-3 device support. The chips worked with CXL, but the official support did not come until 5th Gen Intel Xeon Processors “Emerald Rapids” about a year ago. Somehow, Intel managed to support these memory expansion devices a year after AMD.
Now that modern servers support CXL, one of the big drivers will be memory expansion. For those unfamiliar with Type-3 devices, the high-level idea is that you utilize lanes that are CXL or PCIe lanes for CXL instead, and then hook up a CXL memory controller with DRAM attached. Some of the memory vendors are building CXL drives that look like SSDs and will eventually plug into E3.S or E3.L EDSFF drive bays just like SSDs.

The alternative is often something that looks like a PCIe card with memory or DIMMs such as this Astera Labs Leo CXL memory expansion card.

Scaling this up, in a server, we have something like the Lenovo CXL Memory Monster with 128x 128GB DDR5 DIMMs that we saw in an Astera Labs booth recently. The Lenovo ThinkSystem SR860 V3 is designed for scale-up memory workloads like SAP HANA where you simply need as much memory as possible.

We have also seen custom modules like these from Montage and ASUS that we have shown in the ASUS AMD EPYC CXL Memory Enabled Server which has four servers and a number of memory expansion modules in a single chassis.

Perhaps the cooler variant is what happens with something like a CXL memory expansion shelf like this Inventec 96 DIMM CXL Expansion Box that can house many TB of memory in a dedicated chassis. What is more, that chassis can then connect to one, or multiple servers.

With CXL 2.0 we have a path to switching. Our sense is that the CXL switching, especially when we get to the PCIe Gen6/ CXL 3.x generations coming in the future will be the big use case. Imagine a box like the above where you plug a memory shelf into a rack and then it is allocated dynamically using a switched architecture.

One of the big benefits, esepcially with the hyper-scale focus on delaying general purpose compute refresh cycles, is that you do not need to use DDR5 with CXL controllers. For example, you can recycle a large number of DDR4 DIMMs on a controller like this Marvell Structera. That saves both on purchasing memory, but also on the emissions from creating new modules. In effect, hyper-scalers can pull old DDR4 memory, put them into shelves based on DDR4 CXL controllers, and then allocate the memory to different nodes dynamically. There are huge savings with this.

Beyond DDR5 and DDR4, we have seen other options like the Kioxia CXL and BiCS Flash SSD Shown at FMS 2023 which is just a neat option.

The big message is that we now have had 1-2 years with chips supporting CXL Type-3 devices, and more importantly generations of servers. We also have the ecosystem of devices to start using them.
Final Words
My ask to all of the vendors is that CXL Type-3 devices need to have a plug-and-play experience. In early 2023 if you tried using a CXL controller, it was often validated with a few DRAM module numbers, in specific systems, and running certain firmware on both ends. It needs to be like plugging in a SSD. We are getting closer, but we are not there yet as an industry.
Still, in 2025, expect to see more CXL server designs for those who need more memory and memory bandwidth in general purpose compute. We will start to see CXL pop up in more locations in the near future as the technology is becoming deployable. Its big challenge is that CXL is not normally part of the AI build-out. 2027 would be a best guess for mass adoption and some of the cooler use cases, but it is coming, finally!



{kind=link}
Love that Lenovo Memory Monster.
Don’t see the point. PCIev5x16 can give you 64GB/s theoretical peak in each direction, which boils down to 50GB/s.
One DIMM at 6000MHz can do 48 GB/s peak. So whole link gets bottlenecked with 2 DIMM channels.
Modern servers have 8 and 12 channels.
And that’s without considering the latency etc.
How many apps simply don’t care about RAM bandwidth and latency ?
Also, I’m not sure about memory cost savings.
Memory is expensive, but those novelty boards and links won’t come cheap either.
BTW, we have M(C)RDIMM incoming, which is poised to double the RDIMM bandwidth and capacity.
Which means that CXL bandwith bottleneck will be even more pronounced.
Yes, PCIev6 ii coming, but so is DDR6.
ANd then there is energy consumption problems.
Moving all that data through considerable lengths and switches doesn’t bring just HW costs, but extra power consumption etc.
The use case as stated by Google and Oracle is to reuse a stock of old memory supplies for colder memory storage on CXL expansion
CXL doesn’t take bandwidth from a socket, it adds because you get DDR channels local and you’re getting PCIe channels. Latency is higher like going across UPI or IF.
It isn’t just being able to re-use. It’s being able to install less DDR5 in servers. Then you’re putting cold capacity onto CXL as you expand past local capacity. So you’re saving, but you’re also getting more scaling capacity.
I’d agree CXL 3 is where it’s at. What you’re missing is that once you can share data in a high-capacity switched topology you don’t need to copy data over Ethernet once you can load data into CXL mem then share it among systems
@frogfreak
Not true. CXL would provide extra flexibility, but only for those applications that don’t care about bandwidth and latency.
Well, how many of those are there. Have you seen a friggin server use that fits in that category ?
@Onsigma Blue – consider the case of a compute cluster running an MPI application. You use Infiniband or 100/200 GbE to implement scatter/gather. Such amounts to a memory to memory copy across the network – bottleneck being IB/Enet or PCIe. Now suppose you could leave the data in place in a CXL memory shelf and just share that address space amongst the compute nodes. You have the same bottleneck but you have half as many copy operations. Seems like a win. —- I’m also not convinced that CXL is the way forward for huge memory single nodes, especially given memory modules keep getting bigger. But in some use cases this seems like a good thing.
I see LLM training the primary driver in CXL (2.0+) adoption. As LLM datasets and pace of growth exceed the capacity limits of onboard memory, CXL memory pooling is the natural and more efficient next step.
DDR4 re-use will fail on 1) speed and 2) reliability. DDR5 did so much for memory reliability, especially in large memory servers. Re-using DDR4 en-masse will just run into crashes. I dont think any vendor with CXL 2.0 has hot-swap for individual modules.
CLX 3.0 with PCIe 6 and some RAS features should see adoption, so I agree with the 2027/2028 timeline. Anything before is just tinkering on small scale/proof-of-concept.
LLM training happens in HBM, not slow-speed 3rd tier memory.
People need to understand that just because its in memory, doesn’t mean its instantenous.
Where this might make sense is small nodes with remote-memory beyond the OS and shared within the rack. Exciting technology but I disagree with real-world usage patterns, at scale.
If you’re waiting for 2027 then you’re getting PCIe 7 (assuming not another delay) and the option for optical interconnect, which is useful not just for the lower latency and the (slim ) chance of x32 lanes (because why would optical be x16 or less), it’s also useful for its reach throughout adjoining racks. With 2026 will come MRDIMM too.
When we buy servers, we buy max RAM, load VMWare, which allocates all of the RAM and then reallocates on demand to any VM.
For containers, it usually is the same. Max RAM, load RHEL and use Kubernetes to allocate appropriately.
The servers are then tasked based on the application requirements.
Swaps or changes are done only as a part of repair, since the host is already fully populated.
There is no interest in distributed memory resourcing because they want to keep any malfunction blast radius small and local to the rack.
Performance is not hurt from the physical distance compared to dram sitting next to the CPU working with the CPU memory controller?
Comments are closed.