
One of the big announcements coming from Intel recently is the Intel CXL Compute Express Link Interconnect Announcement. At the Intel Interconnect Day 2019, we received more information on the new Compute Express Link (CXL) interconnect that we wanted to cover in this post.
Note to our readers: we are updating this real-time during Interconnect Day 2019. Please check back later for more details and excuse typos.
The CXL Interconnect at Intel Interconnect Day 2019
Intel is using this diagram to frame interconnects from silicon and packaging to the wireless network edge. CLX is a processor (or processor to processor) interconnect rather than a data center interconnect like Ethernet.
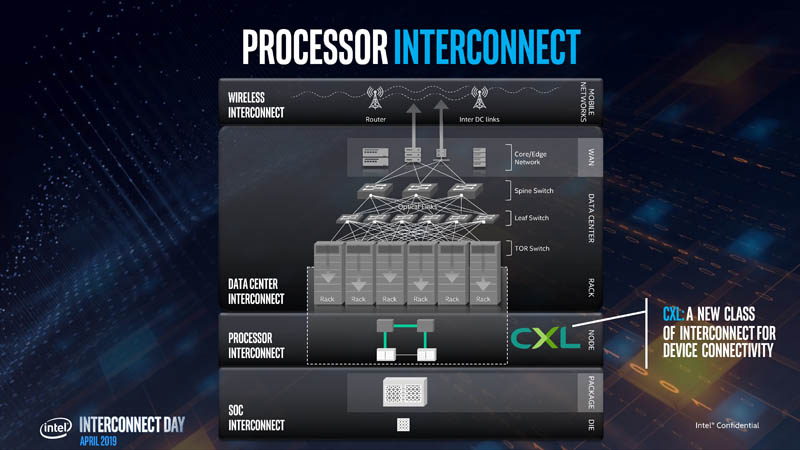
Intel says it needs a new class of interconnect because while PCIe is great, future computing will need low latency communication with coherent memory pools rather than isolated pools with PCIe. Data center trends are toward heterogeneous computing and disaggregation. Currently, there are bottlenecks moving data through these larger systems with memory on accelerators. CXL is trying to address these challenges.

Intel is not using UPI because the company thinks that would have been the wrong solution for heterogeneous computing and an open ecosystem.
Compute Express Link Background
Intel sees CXL is being an alternate protocol running over the PCIe physical layer. At first, CXL will use 32Gbps PCIe Gen5 pipes, but Intel and the consortium plan to aggressively drive towards PCIe Gen6 (and theoretically beyond) to scale.

Intel expects that these are the models that are going to drive bandwidth demands and therefore a more aggressive PCIe schedule.
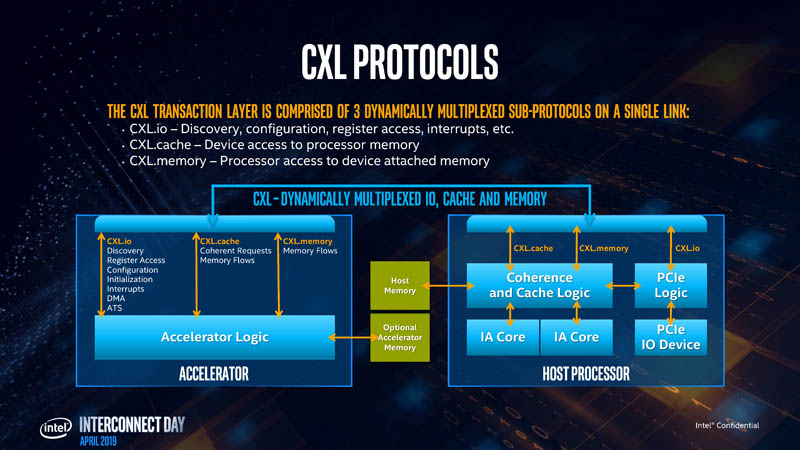
CXL will utilize three dynamically multiplexed sub-protocols over a single link. These are CXL.io, CXL.cache, and CXL.memory.
- CXL.io still allows PCIe like I/O
- CXL.cache allows accelerators to reach into the CPU cache (using 64-byte cache lines)
- CXL.memory allows CPU to reach across to device and access the device memory.
In CXL.cache, the device is always the requestor and the CPU is always the responder. In CXL.memory, the CPU is always the requestor and the device is always the responder.
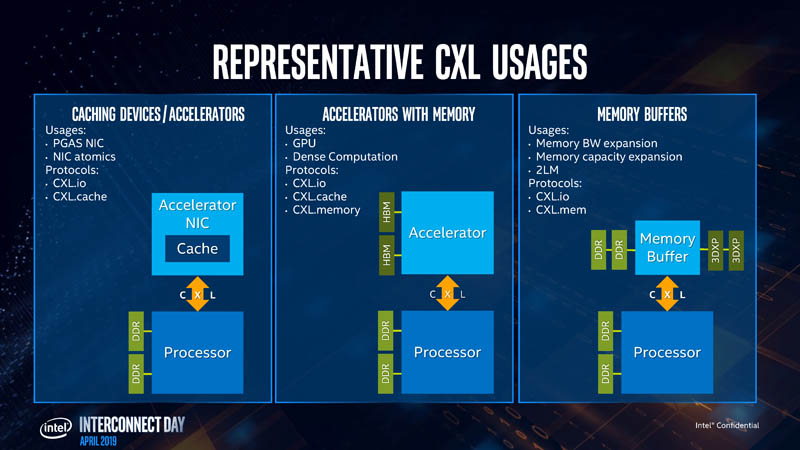
Intel, like the rest of the industry, sees many use cases for CXL and coherent interconnects. HPE and Dell EMC are pushing Gen-Z for largely these use cases as we covered in An Interview with Dell’s Robert Hormuth on 2019 Predictions. HPE, Dell, and the Gen-Z consortium conspicuously were quoted supporting CXL. There are synergies between CLX and Gen-Z for disaggregation.
Intel says that unlike other interconnect options, CXL is designed for low latency. At the same time, CXL.io pass through a stack that looks similar to a standard PCIe stack. Intel thinks that CXL.io is going to be “pervasive.”
About the Compute Express Link Stack
The CXL.io stack is very similar to the PCIe stack but the CXL.cache and CXL.memory run through their own layers. Intel thinks that the extra investment in the CXL stack pays off in latency.
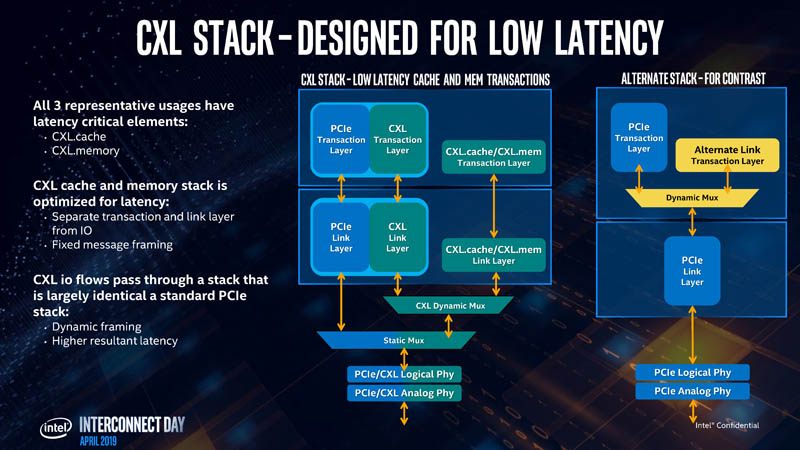
Intel noted that this diagram does not mean that a PCIe Gen5 PHY must be designed for CXL. Intel clarified at the event that CLX Gen1 would use a standard PCIe Gen5 PHY.
The CXL coherency protocol is asymmetric, unlike the QPI/UPI interconnect between Intel Xeon CPUs. QPI/ UPI is a symmetrical model. All agents have home and caching agent mechanisms. In CXL, the caching agents are only on the CPU. This has a number of advantages. From an open ecosystem perspective, this helps allow even non-Intel CPUs and accelerators to join the ecosystem.
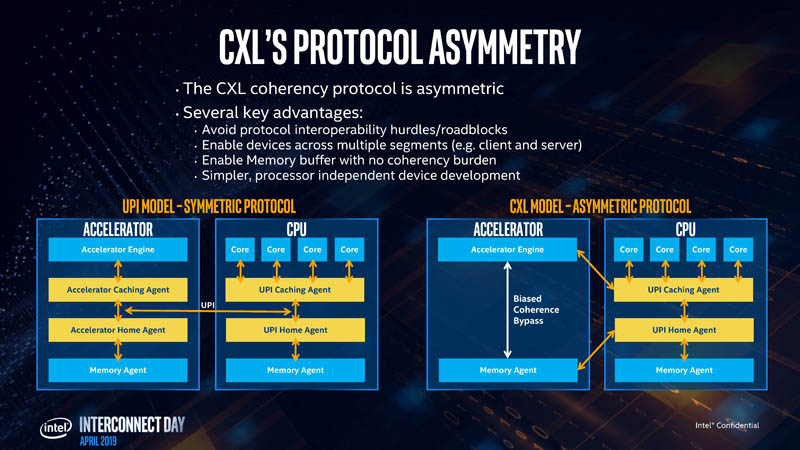
An example of this is if a certain CPU vendor uses CCIX for its multi-socket protocol, it can still adopt CXL. That is the advantage of designing the solution so it does not need to use UPI.
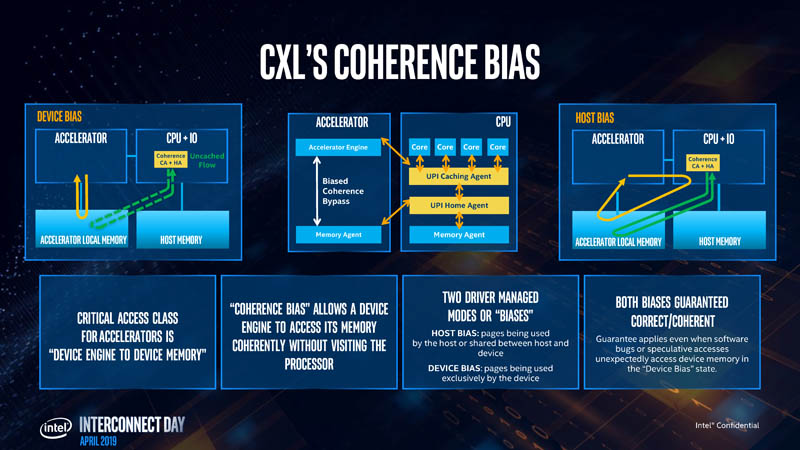
CXL is designed to have coherency which can allow a device to access memory coherently without having to stop at the processor, alleviating some latency drivers.
The design is such that the critical access class will be the accelerator to its own memory. CXL supports a coherency bias that allows this critical access from an accelerator to its memory (e.g. a GPU to HBM), to run at its maximum speed. Host bias is a secondary bias that allows an accelerator to reach through the CPU. Intel sees the device bias is the dominant flow while the host bias flow is used significantly less.
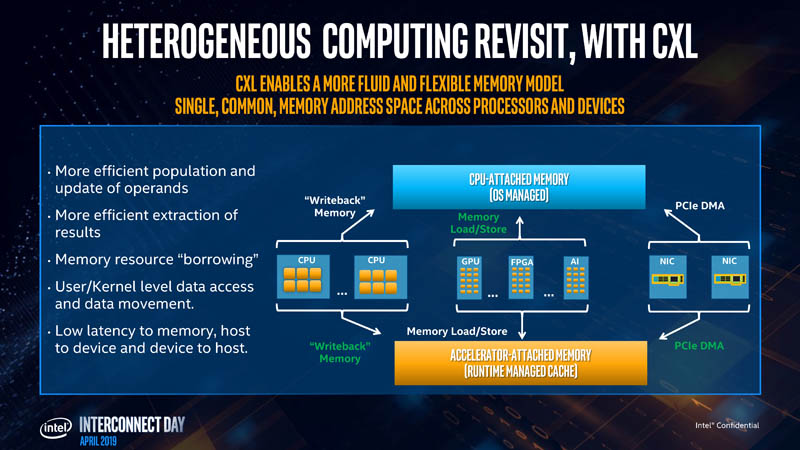
By enabling the ecosystem with CXL, the company sees this as a step to running higher-performance heterogeneous computing infrastructure. This includes not just Intel CPUs, but also Intel sees its future GPU and deep learning accelerators, as well as its FPGA products and their chiplets to as being enabled by CXL.
Here is the quick Compute Express Link summary from Intel Interconnect Day 2019.

This is exciting, but it also means that we need PCIe Gen5 to get here which means realistically this is going to be more relevant as we go into 2021.
Final Words
Overall, Compute Express Link is seen by many as Intel’s onramp to Gen-Z. The industry is moving towards cache coherent protocols and big OEMs like Dell EMC and HPE are pushing for this. We expect to hear more in the future on CXL but we are still some time off. The recent 2nd Gen Intel Xeon Scalable Launch included PCIe Gen3. We expect Cooper Lake to have PCIe Gen4 later this year and into 2020, and then mainstream Intel Server CPUs to support PCIe Gen4 in 2020. AMD is making an aggressive interconnect and PCIe Gen4 push with Rome in a few months so it is good to see Intel has a roadmap beyond the immediate products.
Now, all we need is silicon that supports Comptue Express Link.



{kind=link}
In other words, Intel is trying as hard as it can to show how they are really far out of AMD’s reach.
They need lots of smoke curtains to counter Rome.
Expect many of these technologies to be useless in their first iterations because they are being rushed into the market.
Really Marcelo. That’s your takeaway from this article? You don’t have to look far to find Bozos in tech world
Em, so.. we can execute software across racks without modifing the code? Or we should use some kind of API (One.API?) and make resource access “transparent” in the the software as much as possible in terms of hardware/”MaaS”?
And what will happen if cable is broken? “kernel panic”?
Agreed with Marcello. There’s :
https://www.youtube.com/watch?v=w-rAj1liqrw
CCIX, GEN-Z, OpenCAPI .. Intel isn’t found on any of these open standards that do the same thing as above and better but wants people to look out for their PCIE Gen 5 standard that was hurridly thrown together ahead of AMD’s announcements in the coming months? AMD is going to deliver this technology first in 2019. It will be based on an OPEN standard that many companies support guaranteeing compatibility with PCIE devices. Intel being Intel has their heads up their behind and are still trying to push overpriced propriety junk that is nowhere near being delivered to the market. Too little too late, still proprietary, still will be overpriced… And their marketing slides still read like a garbled mess. Give me a break and get it together Intel.
“FxB” was slipped leftover in on slide. FPGA cross(?) Bus as a internal early codename? Front? Fixed? FaceBook? Fast?
And one motivation seemt to be making accelerators without own memory, just cache.
FlexBus.
This was a fantastic write-up. Thank you! Any idea why they announced this on the same day as Nvidia-Mellanox deal was announced?
There is far too much, and incorrect, reverse “object-action” sentence stucture usage being exhibited on the internet and elsewhere, a.k.a. European Pidgin English, instead of the correct “action-object” sentence structure, and to which a growing act of disrespect. The Stephen Van Doren slide should read something of the sort: A new class of interconnect for connecting a device, or A new class of interconnects for connecting devices, not the reverse sentence structure and incorrect, A new class of interconnect for device connectivity. The action in the sentence is “connecting” and gerund, the “object” is device or devices. Remember, the horse eats grass or the horse is eating grass, as oppose to the horse grass eats, or more arcane, the horse grass eativity.
Comments are closed.