
With the newest $100M+ AI cluster, Cerebras has become the first post-legacy chipmaker to become an AI winner. For years, there have been many companies trying to tackle AI training. At this point, NVIDIA has done it. AMD and Intel have HPC wins and are trying to win in the dedicated AI training chip space. Cerebras is the first of the new wave of AI chipmakers to actually have a shot at AI training and inferencing because of its radically different architecture. What is more, Cerebras is innovating on more than just its chips, it is also the first major AI chipmaker to deploy and sell its AI accelerators in a cloud that it operates at this scale.
$100M+ USD Cerebras AI Cluster Makes it the Post-Legacy Silicon AI Winner
Cerebras makes the largest AI chip out there by a long shot. Its chip is as big as one can make on a round wafer at TSMC and is thusly called the Cerebras Wafer Scale Engine WSE-2. Here is the second generation WSE-2 from last year’s International Supercomputing conference.

Having a huge chip that is like having dozens of GPUs on a single chip. That also means that it needs a massive amount of power and cooling. Cerebras builds a system called the CS-2 around the massive chip and this is the power and cooling assembly that looks a bit like an engine block.

We looked at this, along with other technologies last year at SC22 in a video here.
Today, Cerebras is announcing a big win for its CS-2 system. It has a $100M AI supercomputer in the works with Abu Dhabi’s G42. The key here is this is not just an IT partner, this is a customer.

The AI supercomputer is located in Colovore in Santa Clara. Colovore is where the STH liquid-cooled lab would have gone if we were still in the Silicon Valley.

The current Phase 1 has 32 CS-2’s and over 550 AMD EPYC 7003 “Milan” CPUs (note: Andrew Feldman, CEO of Cerebras told me they were using Milan) just to feed the Cerebras CS-2’s with data. While 32 GPUs are four NVIDIA DGX H100 systems these days, 32 Cerebras CS-2’s are like 32 clusters of NVIDIA DGX H100’s each on single chips with interconnects on the large chip. This is more like hundreds (if not more) of DGX H100 systems, and that is just Phase 1.

In Phase 2, the Santa Clara, California/ Colovore installation is set to double, likely in October.

Here are the stats. Something to keep in mind is that with giant generative AI models, Cerebras has designed its architecture from the ground up to scale to huge levels. The code is designed to look the same between one CS-2 and a cluster of CS-2’s. With such large chips, Cerebras can handle weights and data differently than on GPUs and it has been leveraging that approach for some time to efficiently scale to meet large problem demands.
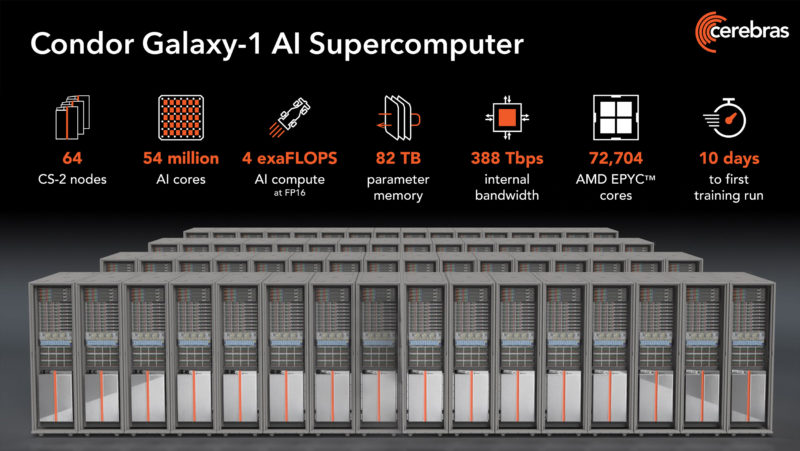
Then, Cerebras is going a step further. With Condor Galaxy-1 in Santa Clara, Cerebras will add two additional 64x CS-2 clusters in the US.
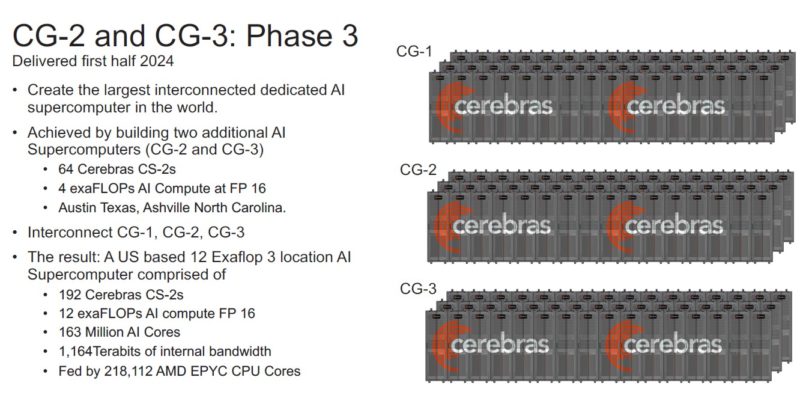
One is set to be here in Austin Texas. The other will be in Ashville North Carolina.
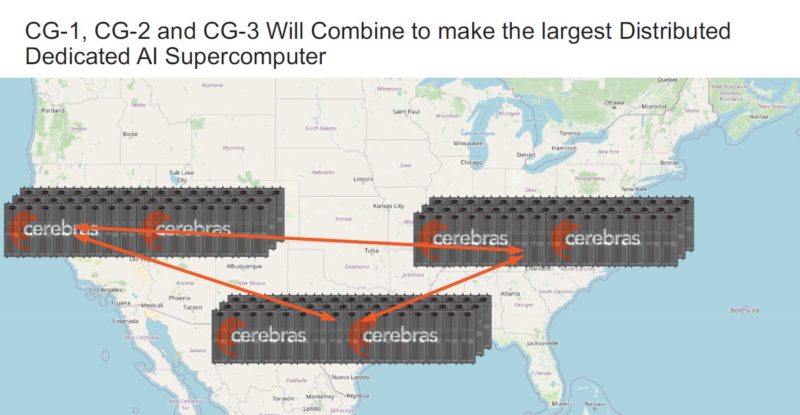
Once these 192 CS-2 systems are installed, then the next phase is to six more 64x CS-2 clusters around the world next year.

It is hard to understate how huge this infrastructure is, even if it does not look large in photos. The context is that each CS-2 is like a cluster of GPU systems plus all of the interconnects built into one box.

While G42 has its own uses, Cerebras is evolving its model as well. It will operate the clusters and help sell excess capacity. Right now there is such a big push around generative AI that companies are scrambling to find GPUs, and NVIDIA has been sold out for a year on the H100. Cerebras changes that by providing the biggest AI chips in a cloud for companies (as well as selling on-prem servers.)
Final Words
This is a winning model. Cerebras not only has a customer that can spend vast sums of money on compute, it also has a strategically interesting customer. Unlike selling to Google, Microsoft, AWS, Baidu, and so forth, Cerebras can operate the AI cloud and help broker selling time on the AI clusters. It is transforming itself from a company that just makes huge chips and boxes into one that has recurring revenue streams.
Some argued that I was a bit harsh with Graphcore Celebrates a Stunning Loss at MLPerf Training v1.0. With this win, Cerebras has a huge cloud-scale customer. It won big commercially without participating in the MLPerf benchmarks that are heavily NVIDIA-leaning. It has also separated itself from other AI companies trying to build NVIDIA-sized chips and then compete in a NVIDIA leaning benchmark.
Beyond all of that, many customers worry about the viability of AI startups. If CG-1 was a $100M+ cluster, and the plan is to build out nine more in the next 18 months, then generate cloud service revenue from them, that means Cerebras has a line-of-sight to $1B in AI revenue in just the next 18 months. This is no longer a startup looking for meaningful revenue.



{kind=link}
I’m looking for the real-world performance of model training tasks. It seems the dedicated optimized training code is needed for CS-2 and when it is done properly, in ballpark figure, 16 Cerebras CS-2 is roughly equivalent to 96 Nvidia A100 ?
@Yamamoto,
I think you are thinking about this wrong. First off, you are comparing Cerebras systems to NVIDIA chips ? You should probably be comparing to DGX systems with the most recent H100s. I’m guessing than we will see LLM training comparisons soon, but aimed at typical and future training needs (not puny BERT or even GPT-3). Likely that the 64 CS-2 system will have similar training performance to a 1024 H100 DGX system.
Cerebras is untrustworthy until they perform MLCommons benchmarks. They are still scared to do that = untrustworthy.
Totally disagree. They have customers using their platforms. NVIDIA so heavily influences MLPerf workloads and submissions of its own and partners. The bigger takeaway is that even without MLPerf, Cerebras’ customers are investing $1B+ in the AI hardware, or around a quarter’s worth of AMD’s data center revenue.
Comments are closed.