
At HC34, a few years after shocking folks with the original Wafer Scale Engine, Cerebras goes into WSE-2 and its efforts to bring more types of computation onto its giant chips. Much of this we have known about the architecture, but it is great to get updates in a few areas.
Note: We are doing this piece live at HC34 during the presentation so please excuse typos. The cover image is me with the WSE-2 at ISC 2022 since Hot Chips is not live this year.
Cerebras Wafer Scale Engine WSE-2 and CS-2 at Hot Chips 34
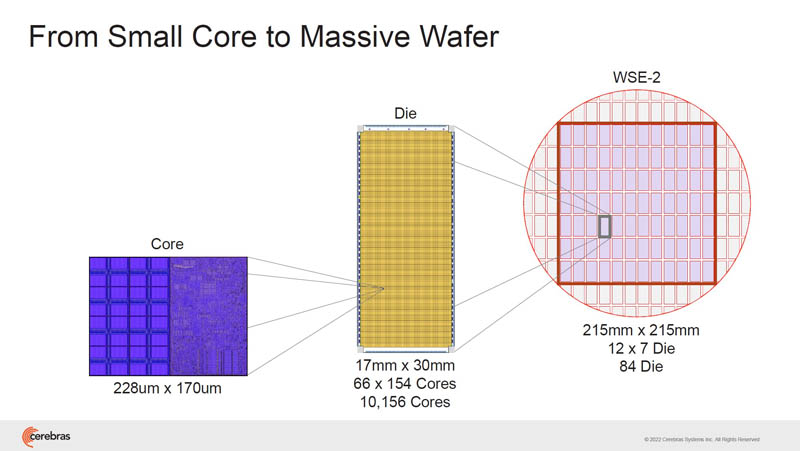
The Cerebras WSE-2 has many small cores on a giant TSMC N7 wafer. Each core has its own SRAM and only takes 30mW. Half of the area is logic and the other half is SRAM.

Cerebras scales memory with the compute cores across the wafer because it is more efficient to keep data on the wafer than go off-chip to HBM or DDR.
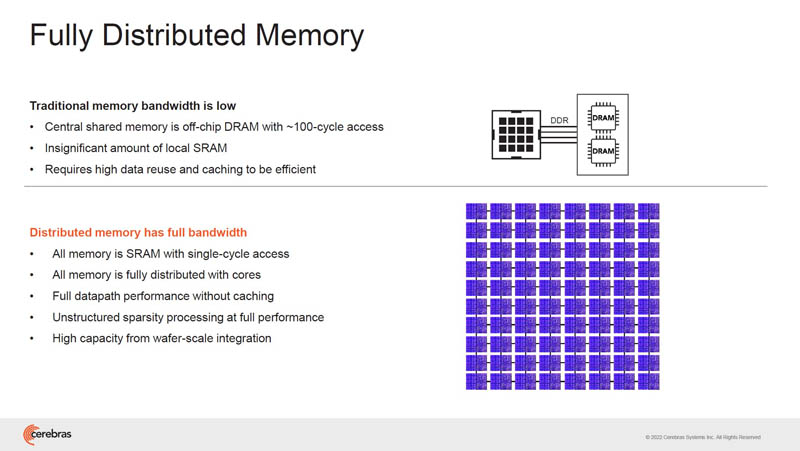
Each small core has 48kB of SRAM. Sharing of memory happens through the fabric. There is also a small 256B local cache for low power. Cerebras says it has 200x the memory bandwidth compared to the area at a GPU.
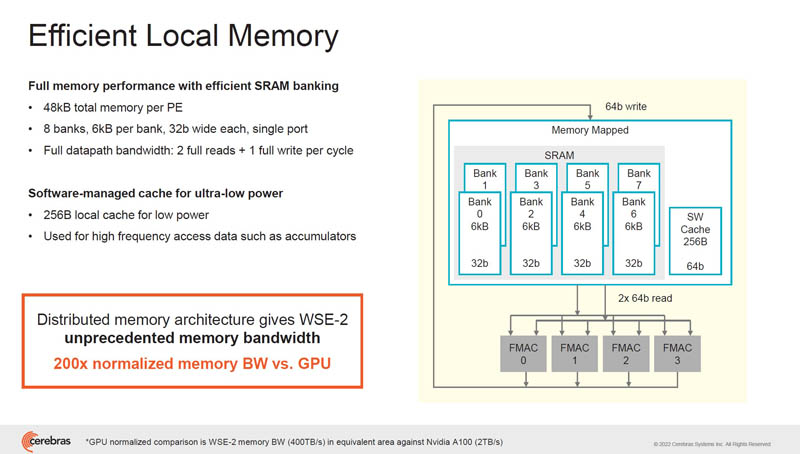
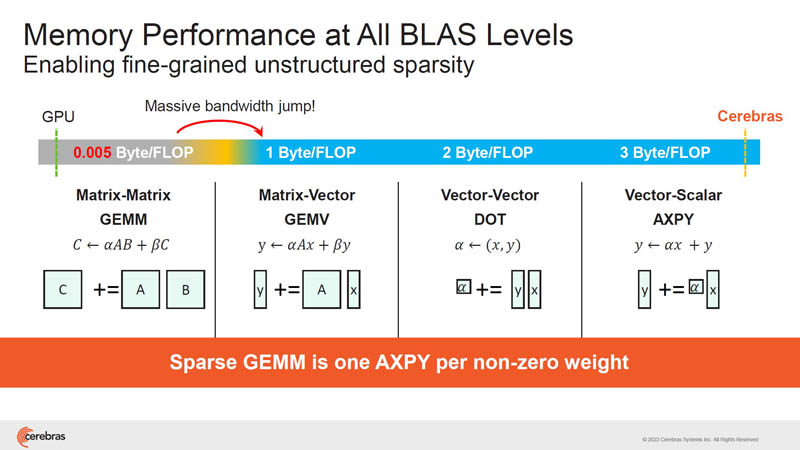
Cerebras says that going beyond GEMM operations, memory bandwidth does not scale on GPUs. The WSE-2 SRAM setup can feed cores at higher speeds.
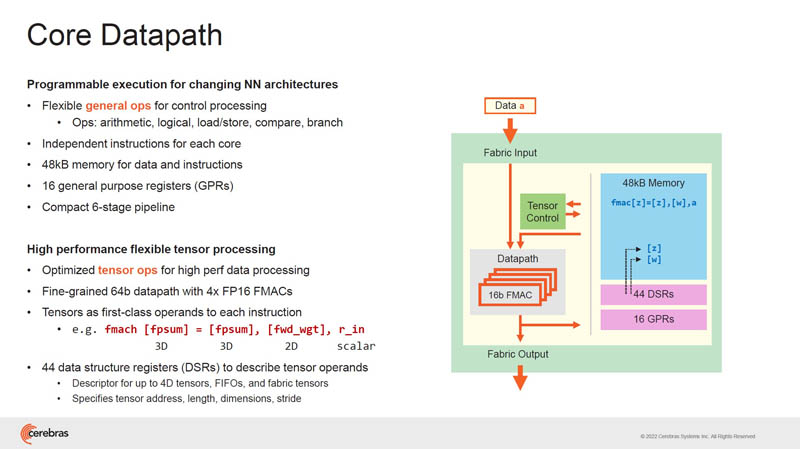
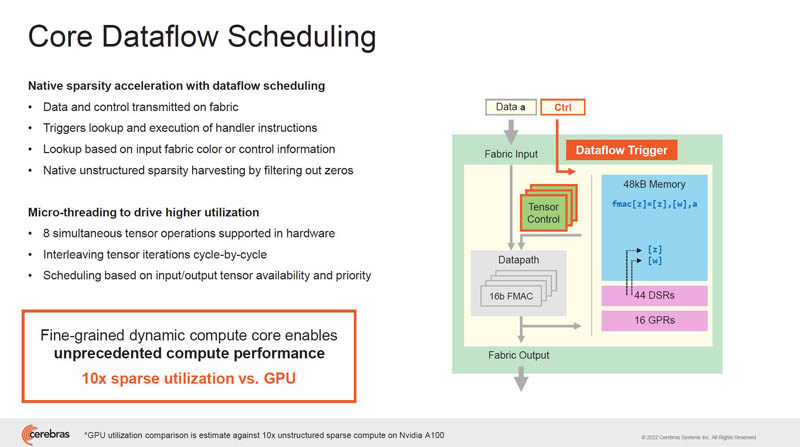
The core has its general operations. Each core is independent allowing for fine-grained control and computation across the chip. There are also tensor ops built into the cores.
Cerebras only sends non-zero data, so it only performs compute on non-zero data. This is fine-grained unstructured sparsity computation.
Here are the top-line specs for the WSE-2. Tesla Dojo has 11GB of on-Tile memory. Cerebras is at 40GB.

When we say WSE, Cerebras is using a wafer-size chip that is the largest chip that can be made out of a TSMC 7nm wafer. That means that instead of making a chip, then splitting them up, Cerebras uses a wafer-size chip.
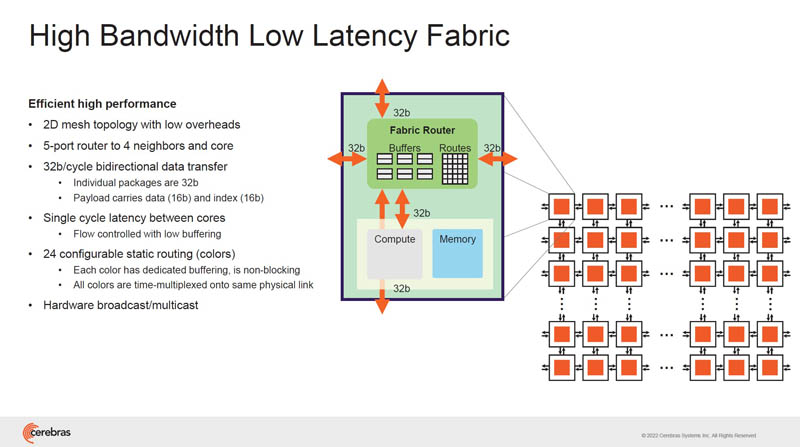
On the chip, there is a low latency fabric with a 2D mesh topology. Each router can talk to its neighbors and the core.
The fabric spans the entire wafer. Because of that, it needs to be tolerant of fab defects.
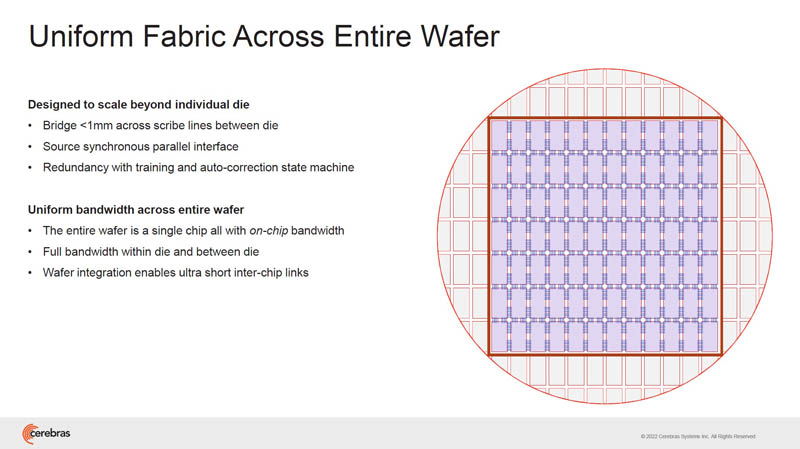
Each wire between the cores spans less than a millimeter. As a result, it uses less power to move bits.
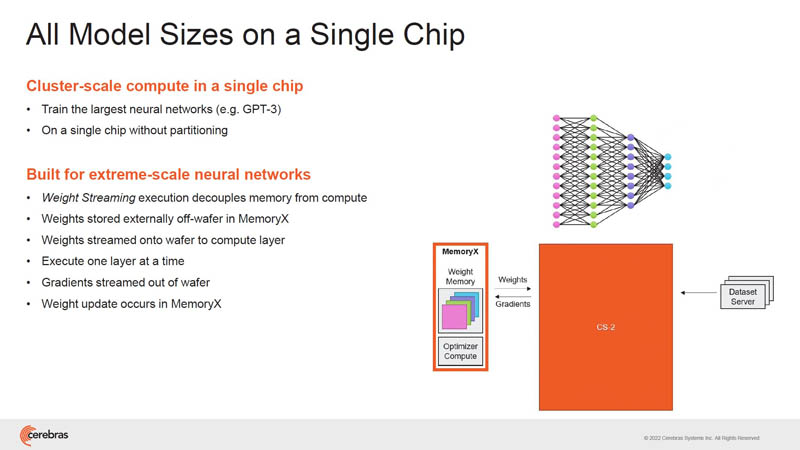
For larger models, Cerebras has a novel way to use these resources. Model weights are stored on MemoryX and are streamed onto the system. That means it does not need larger on-chip memory to address larger models.
The next set of slides are talking about how compute is performed. We are going to just let folks that are interested read through the slides.
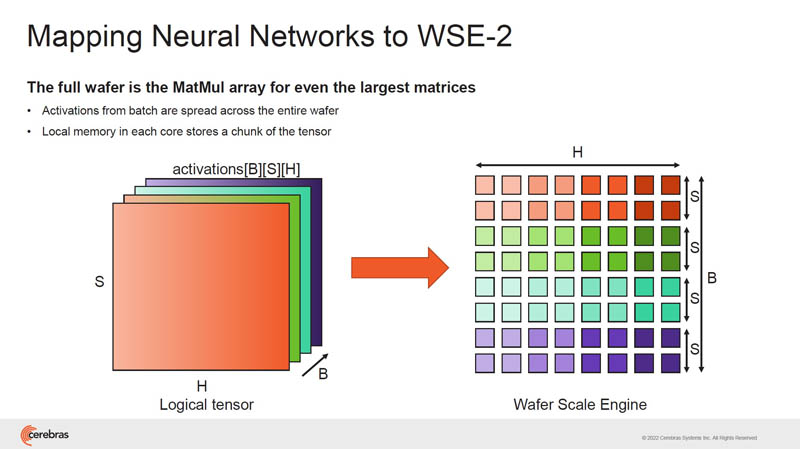
The next step after the neural networks are mapped to the wafer, is to stream data in and start work.

This is the GEMM and sparsity we discussed earlier.
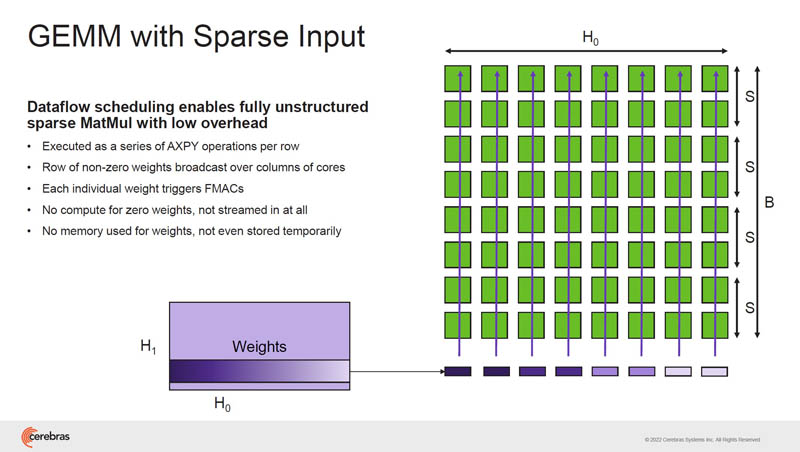
Since multiplying by zero yields zero, as a result, Cerebras can harvest sparsity.
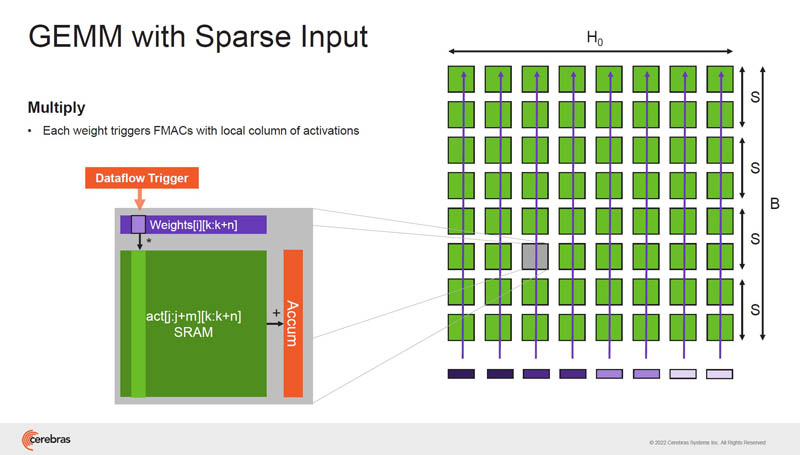
It Cerebras can then continue operating on the weights.
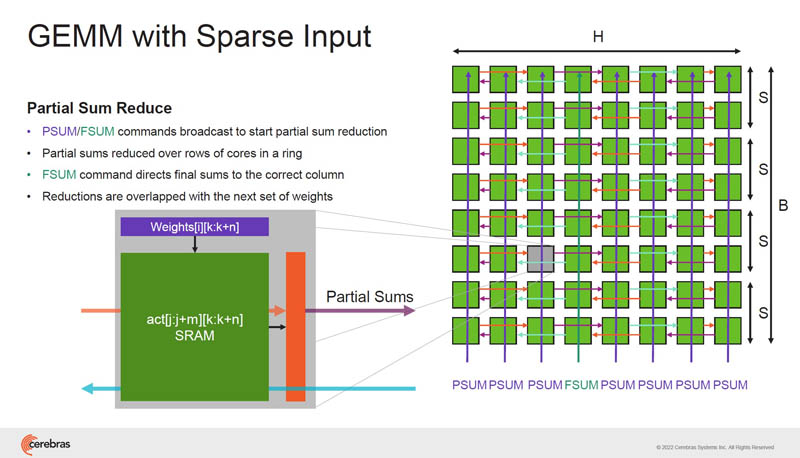
We covered this a bit at ISC 2022, but Cerebras is working on streaming weights into the chip to more efficiently use the architecture with larger models.

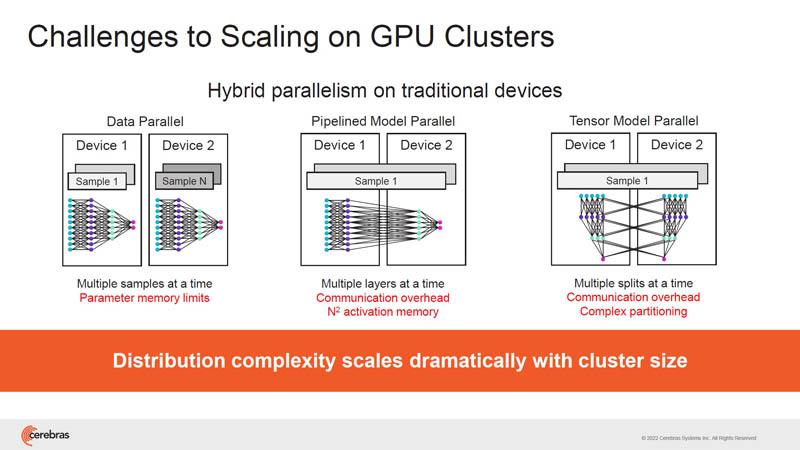
Clustering is a big deal in AI. Depending on the method chosen, scaling out can run into interconnect or memory limitations quickly.
Here are the largest models trained on GPUs and the types of parallelism that are being used.
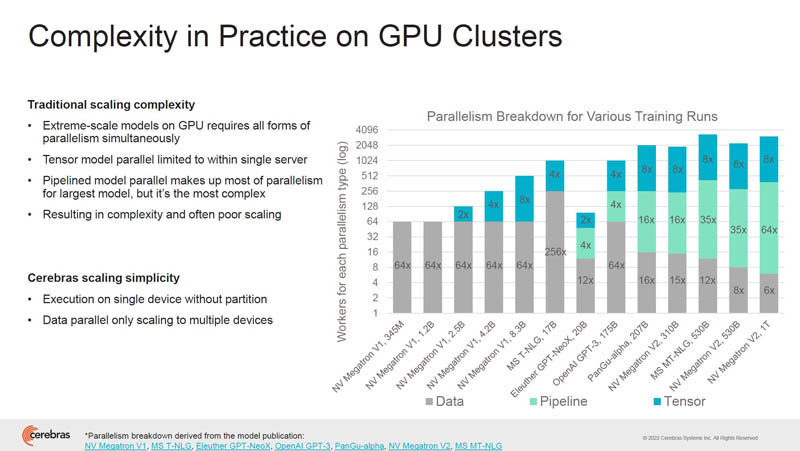
Training large models on GPU clusters, is a systems challenge. We will note that NVIDIA is working hard on this front. Still, Cerebras’ approach is SwarmX where it matches data in MemoryX to CX-2 compute modules (each CS-2 has a WSE-2 inside.) That allows the system to scale to larger scale-out systems. Also, the SwarmX mapping to CS-2’s is more efficient than GPUs because there are fewer nodes due to the size of WSE-2 versus GPUs that are then aggregated in servers.
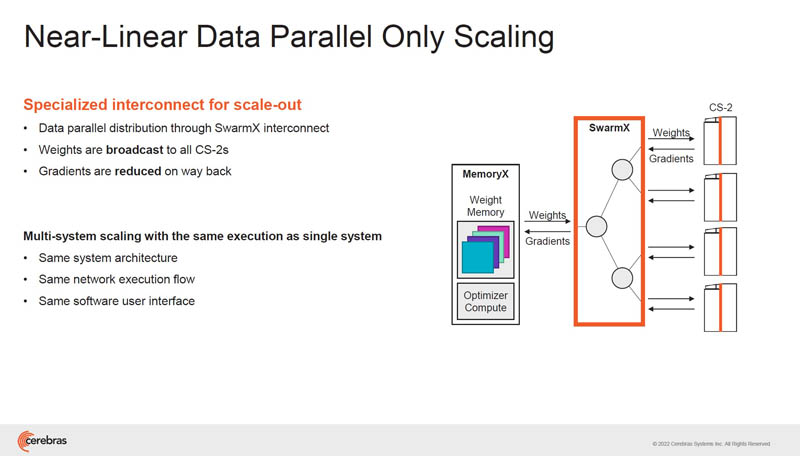
Cerebras has certainly taken a step beyond just having a chip and is now engineering larger clusters.
Final Words
I certainly still remember the original Cerebras Wafer Scale Engine reveal at Hot Chips years ago. Years later, this is still perhaps the most differentiated competitor to NVIDIA’s AI platform. It takes a lot to go head-to-head with NVIDIA on AI training, but Cerebras has a differentiated approach that may end up being a winner. Tesla just did its Dojo Tile approach, but Cerebras has a bigger chip because it is not breaking up the chips before re-integrating them.



 was detailed, and the company showed how it is scaling out CS-2 deployments){kind=link}