
We just looked at the Tesla Dojo microarchitecture at Hot Chips 34. The next talk is about packaging the components into a larger system. Tesla has its own hardware and even its own transport protocol. Tesla’s goal is to make an AI supercomputer that is optimized for its heavy video AI needs.
Note: We are doing this piece live at HC34 during the presentation so please excuse typos.
Tesla Dojo Custom AI Supercomputer at HC34
Tesla needs a ton of compute for general autonomy for self-driving cars, trucks, and more. Since Tesla works on a lot of video data, that is a more challenging problem than just looking at text or static images.
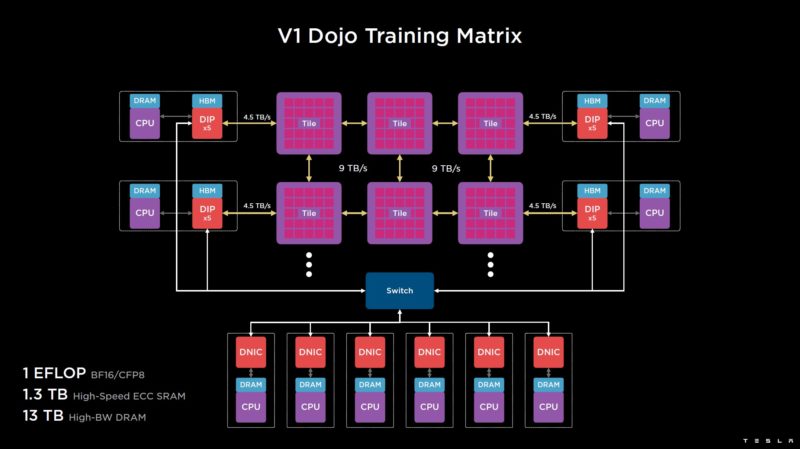
The Tesla Dojo is based on a System-On-Wafer solution. We just looked at the D1 Compute Dies in the last talk: Tesla Dojo AI System Microarchitecture. Each D1 die is integrated onto a tile with 25 dies at 15kW. Beyond the 25 D1 dies, there are also 40 smaller I/O dies.

The Training Tile has all of its power and cooling integrated.

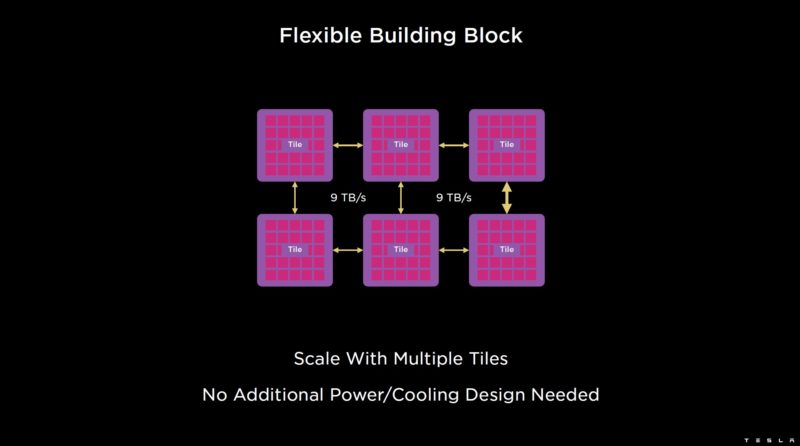
These Training Tiles can then be scaled with 9TB/s links between tiles. The tiles are designed to be simply plugged in instead of requiring its own server.
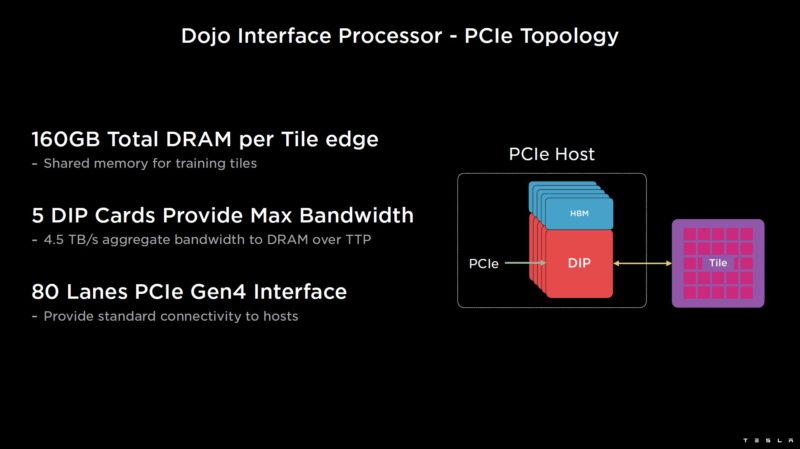
The V1 Dojo Interface Processor is a PCIe card with high-bandwidth memory. This can be in a server or standalone. The cards utilize Tesla’s own TTP interface and have massive bandwidth.

In the first generation, up to five cards are used in a PCIe host server to provide up to 4.5TB/s of bandwidth to the training tiles.
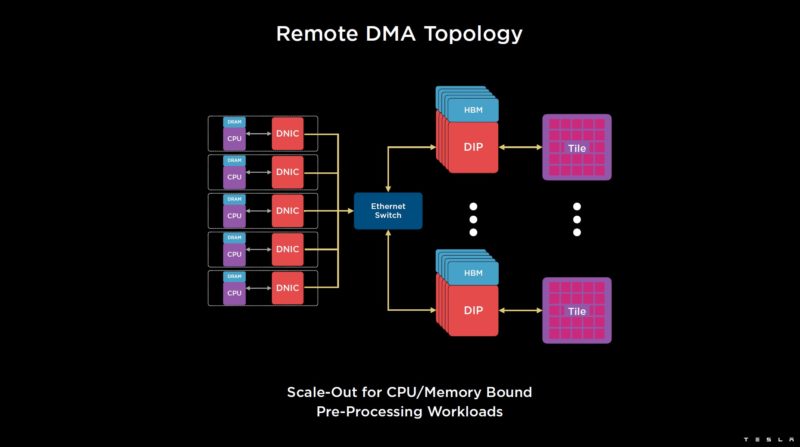
TTP is the Tesla Transport Protocol, but Tesla is also using Ethernet. The software sees a uniform address space across the system. The Interface Card can also bridge to standard Ethernet.
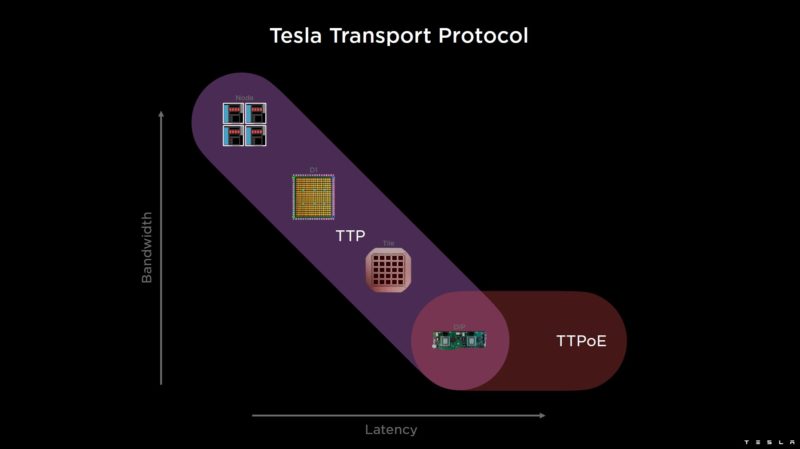
TTPoE can use standard Ethernet switches for a Z-plane topology.
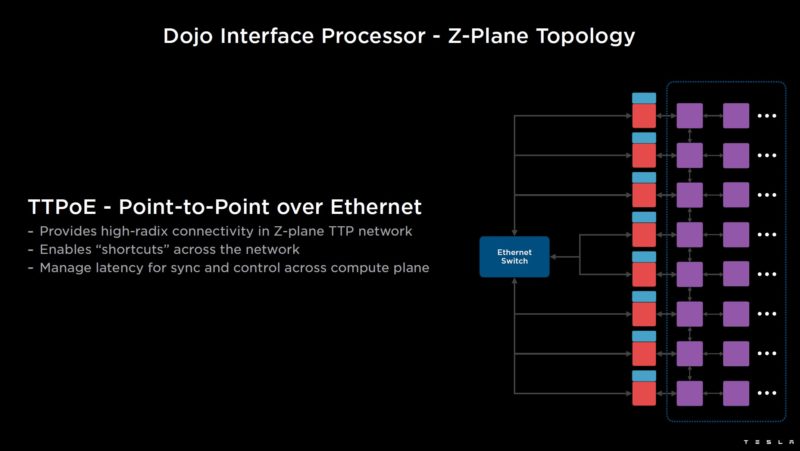
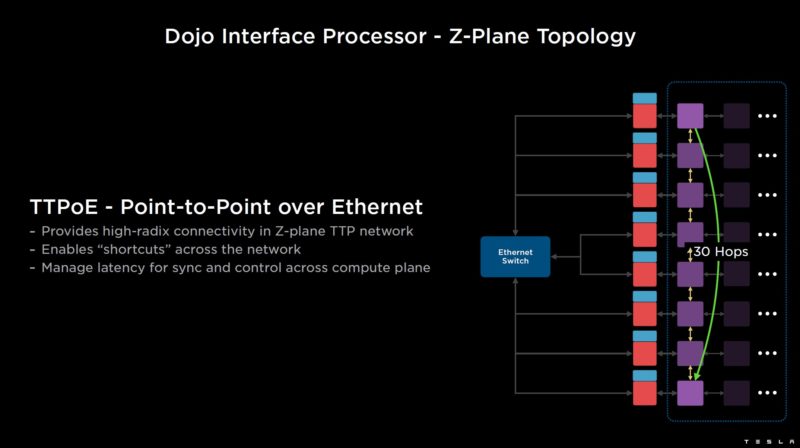
An example, is that using the 2D mesh, something that can take 30 hops…
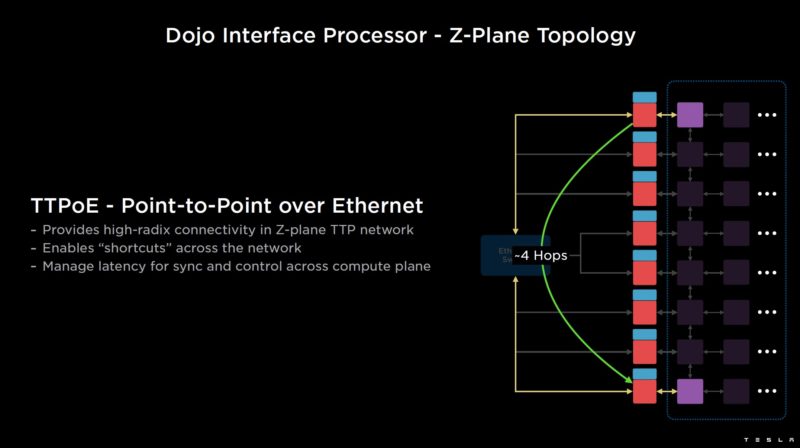
…can instead traverse the Z-plane and only pass 4 hops.
Dojo can also handle RDMA over TTPoE.
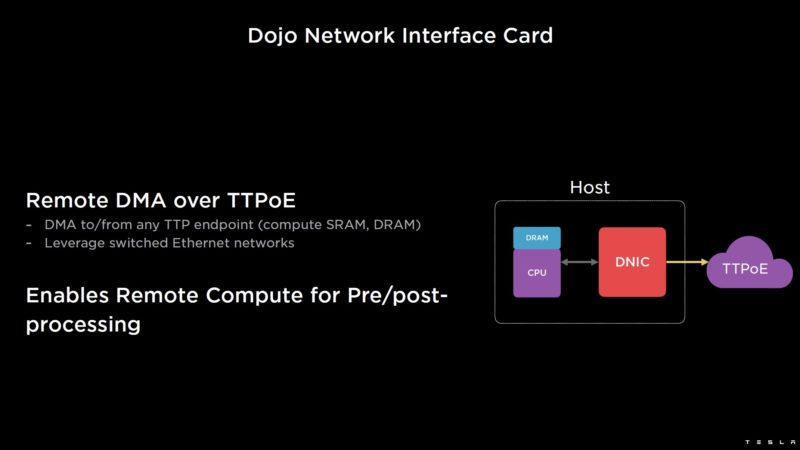
Here is the topology.
Here is what the current V1 Dojo Training Matrix looks like. That can scale out to 3000 accelerators for its exascale solution.
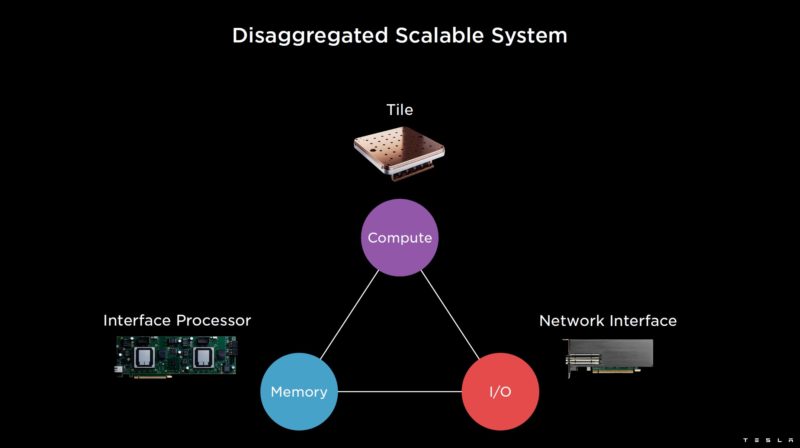
This is built as a disaggregated scalable system so devices can be added (e.g. accelerators or HBM hosts) independently.
On the software side, the entire system can be treated as one block. With the SRAM, Tesla says most of its work is done completely in SRAM.
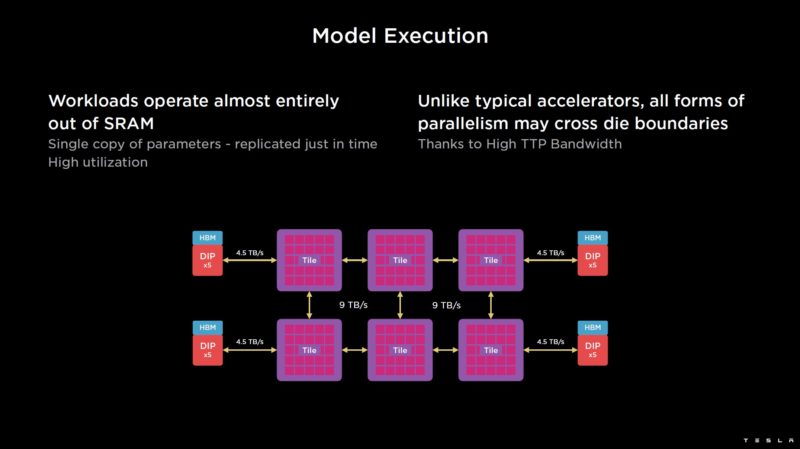
Tesla’s talk went into steps of how computation happens for a model, but instead, let us get to the higher-level challenge.
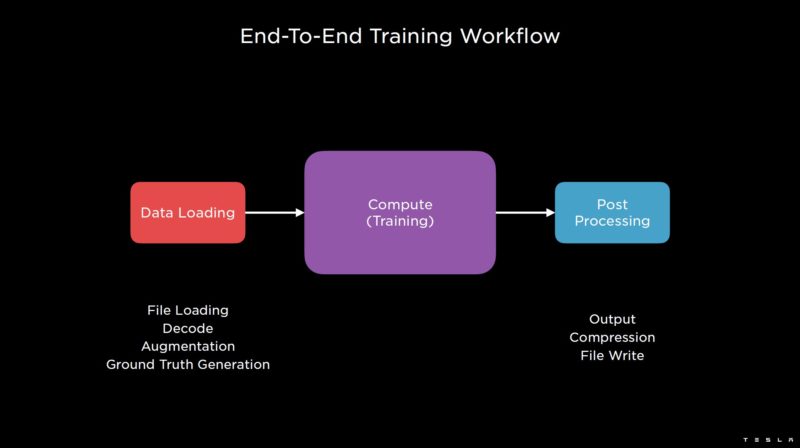
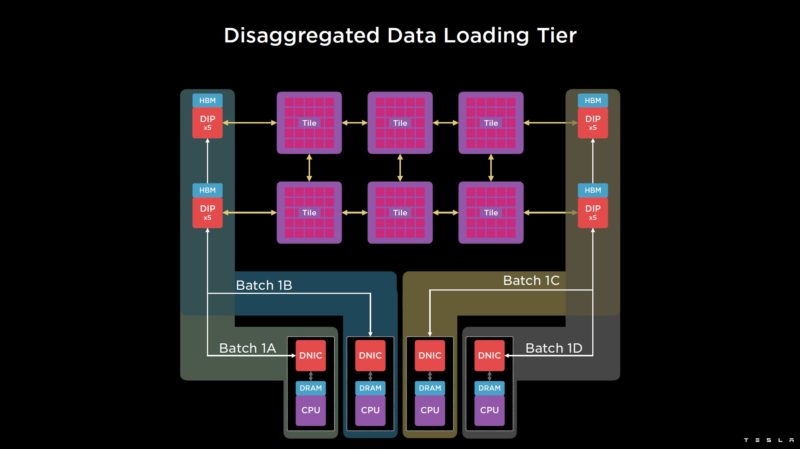
Training requires loading data. Tesla’s data is often video, and so that gives a data loading challenge.

These are two internal models at Tesla. Both can be handled by a single host.
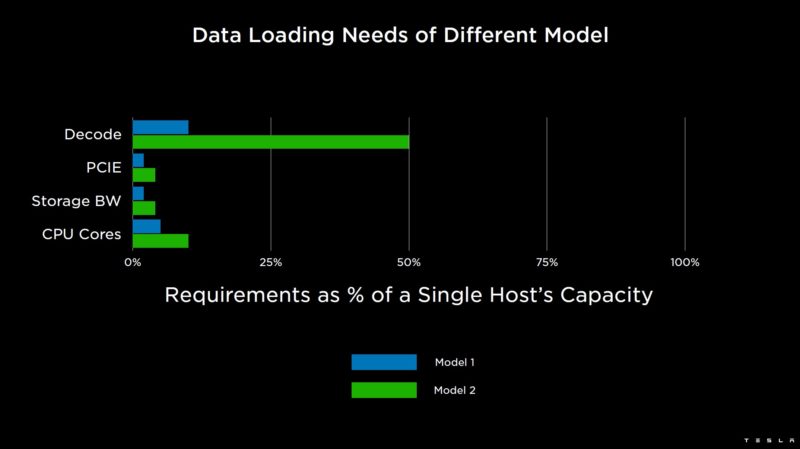
Other networks can be data load bound such as this third model that cannot be handled by a single host.
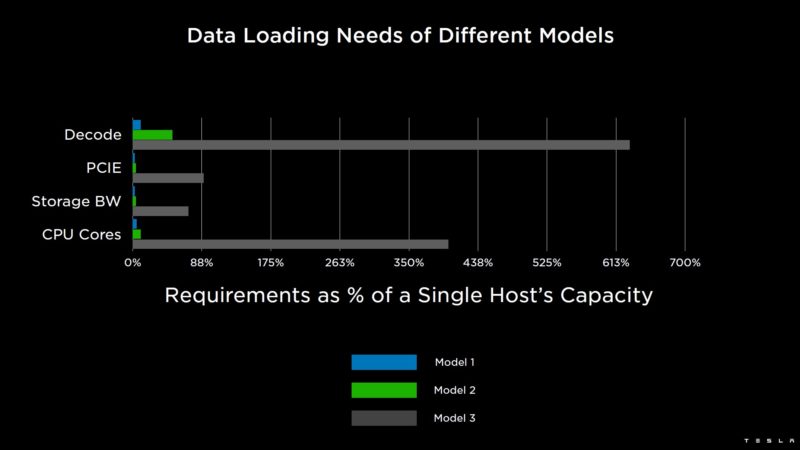
As a result, the host layer can be disaggregated so Tesla can add more processing for things like data loading/ video processing. Each has its own NIC.
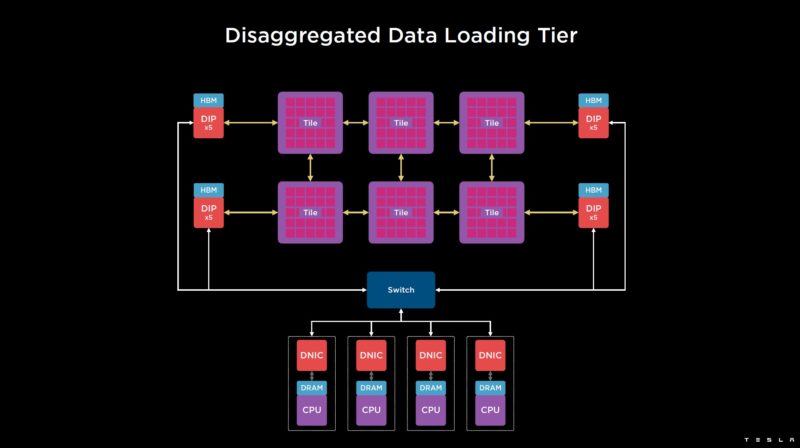
This is an example of sharding the input data for the data load across multiple hosts.
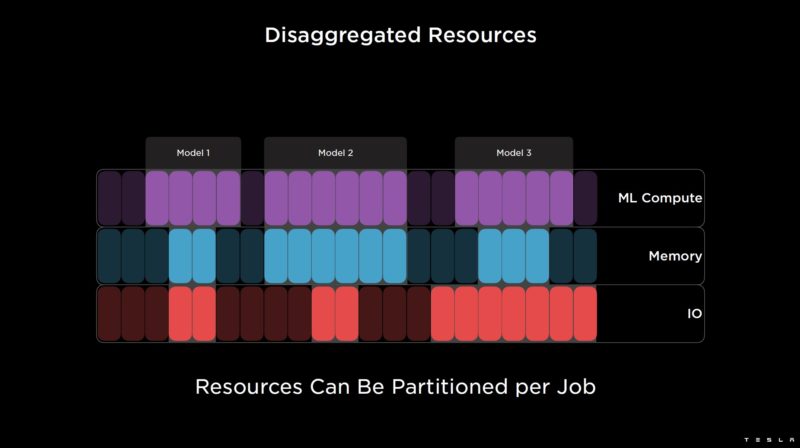
Since models use different amounts of resources, Tesla’s system allows for adding resources in a more disaggregated model.
Tesla has 120 tiles per Exapod and plans to build out in Exapod sizes (Exa pod?)

This is a very interesting design for sure.
Final Words
This is a lot of resources behind building an AI cluster. Still, it is really cool that Tesla shows its custom hardware. Companies like Amazon, Apple, and Google rarely do so. While those companies are building their own chips, Tesla is trying to lead the industry and gain mind share. Our sense is that this is a presentation designed to attract engineers to the company since it does not seem like the company is selling Dojo to others.



{kind=link}
Is Tesla actually using Dojo?
@Ziple lol, I sure hope they are. Think of the payroll for the silicon team!
I don’t think they are right now, everything is just renders and there are no performance comparisons or anything.
And they are still buying Nvidia GPUs like crazy.
It was sort of confirmed in the Q&A session that Tesla currently has silicone in their labs, but they made no mention of what stage of development that silicone is at. Based on that and their presentations I’d say it is safe to assume that none of what Tesla is touting is actually functional at this time and the presentations are just their wish list for the future.
Comments are closed.