Supermicro SYS-112D-40C-FN8P Performance
The system utilizes the Intel Xeon 6716P-B. You can learn more about the Intel Xeon 6 SoC Family in our overview.

One of the neat features of the CPU is that it supports Intel vRAN Boost. This is a carrier capability, but one that used to come in an eASIC accelerator that Intel has integrated into many Xeon 6 SoC SKUs. If you want to see more on the origin, you can see our Intel ACC100 quick look.

One challenge that we have is that a lot of the vRAN stack that uses this acceleration that Intel manages access to, so we cannot use it for benchmarking at this point. Still, it is neat to see the progression from a hardware accelerator to an onboard accelerator, which is also what happened with things like the Intel QAT accelerator on this chip.
On the onboard networking, here is a quick and dirty iperf3 test with 4x 25G flows using simple DAC connectivity:
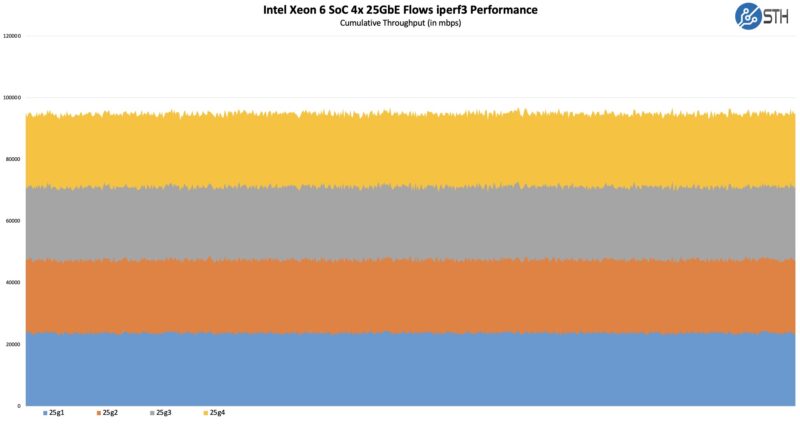
I think we have found a way to use Keysight IxNetwork to do NIC testing in our environment, as we use it for network switches, but we need to do a bit more validation on that. Still, just being able to do this shows that we are well beyond the 10GbE era of integrated networking.
Core-to-Core Latency
Since we have not published benchmarks for the Intel Xeon 6 SoC yet, we thought we would take a quick look at the CPU’s core-to-core latency.
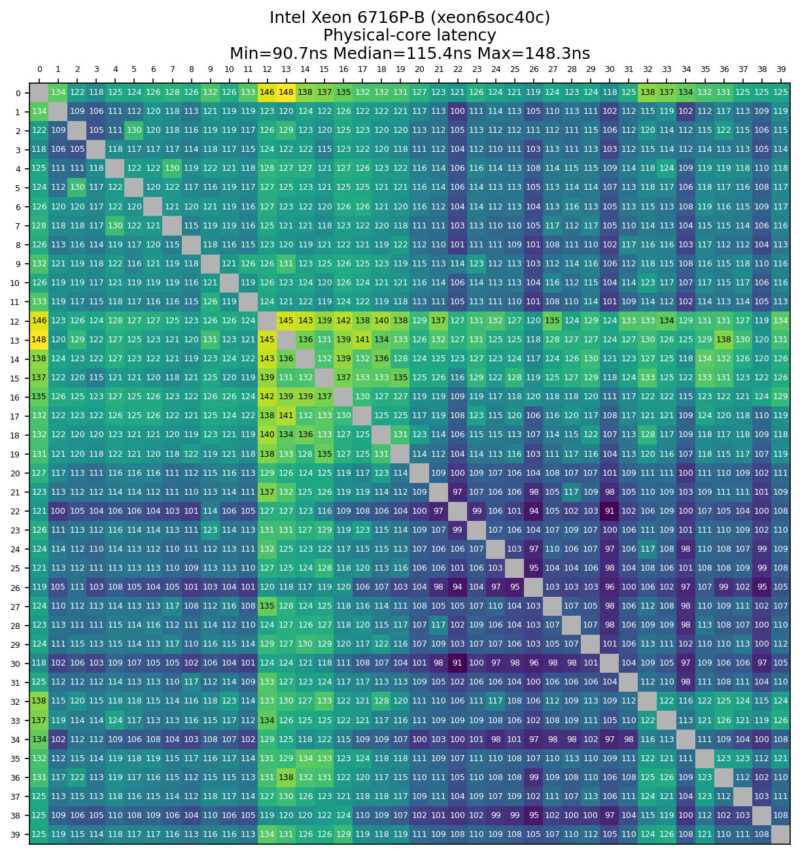
This is a Granite Rapids part, and something notable is that you do not get the big chiplet latency hops that you see on AMD systems (among others), nor the latency hits we sometimes see going from P-core to E-core complexes.
Lmbench Results
We just quickly ran a lmbench sweep on the new SoC. Here is what we saw:
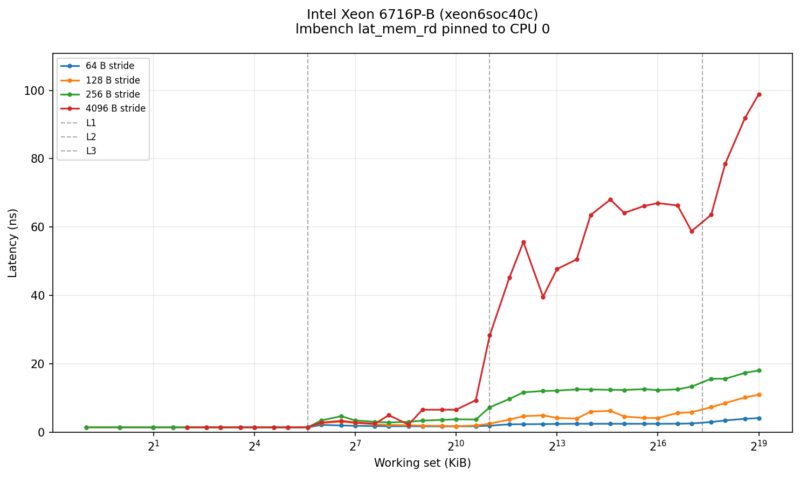
You can see the caches work their magic here, and also why having that big L3 cache helps.
Geekbench Results
We wanted to add these to our growing Geekbench portfolio, so you can have a quick and easy comparison point. Here is the Geekbench 5 result:
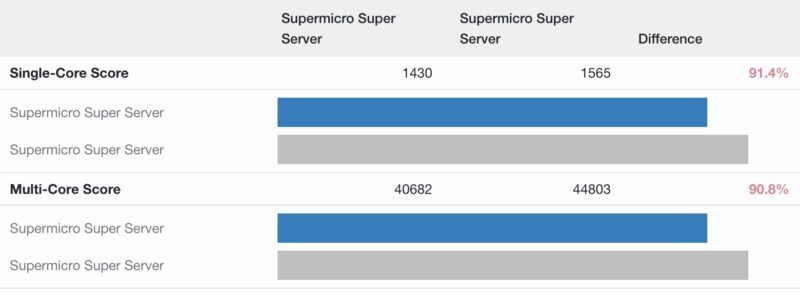
This is really good, owing to the 40-core CPU. It is amazing just how far these have come compared to a few generations ago.
Here is the Geekbench 6 result:
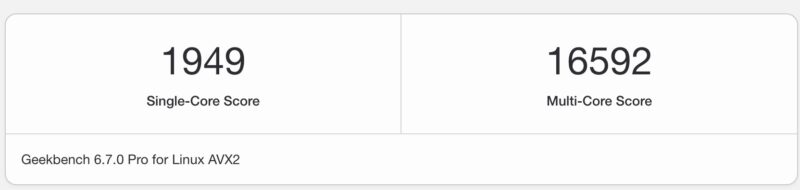
This is not really exciting since Geekbench 6 does not scale to big CPUs, but we have it here more just for the single-core result.
AgentSTH V5 Results Preview
Something we discussed is a new Agentic AI benchmark focused on how well CPUs perform on the agent part of workloads, rather than the LLM part, which often runs on GPUs. It turns out that Agentic AI CPU workloads often mirror much of what we see in more traditional workloads, so as we have been overhauling our suite, we wanted to modernize as well. For those who do not want to see AI, tasks like compression are still very relevant to general-purpose computing use. What we did, however, was to profile a number of different Agentic AI workloads to get a mix for the composite score. Also, and this is important, we are splitting up tasks. On modern CPUs with hundreds of cores, having a single task on a single core constantly stalling over 100 cores is not ideal. Realistically, today’s CPUs run containers, sandboxes, and virtual machines to use a single server to service multiple workloads simultaneously. So we are moving to an era where we will look at a number of different CPU splits to see how it handles those simultaneous workloads and how they scale. That means we are not running a suite of benchmarks across a CPU once. Instead, we are now running different workload configurations on the CPU, for example.
Also, we are going to land the public benchmark on Ubuntu 26.04 LTS since we have found a few instances where Linux 7.0 makes a notable difference, and we are days away from the new OS release. Instead of an incremental upgrade for STH, this is a complete overhaul, modernized and written in Rust, and targeted at a modern LTS release.
Staring out, 1 Agent is running one instance of the suite across the entire socket, whereas 2 and 4 Agents are views of splitting the task up to multiple simultaneous agents running. We have a lot more split data on these, but this is just a high-level view of the difference.
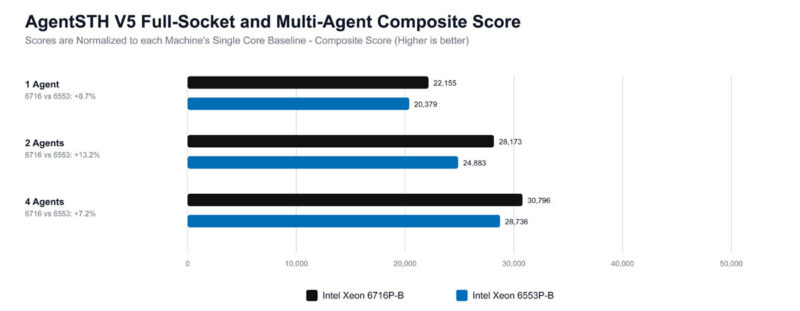
These results are all normalized to running the benchmark on a single core of that machine. The reason the 4 Agents look much better than the 1 Agent is because of the issue of stalling an entire chip for a single core waiting to finish. The key lesson here is that running a single workload across even a 36 or 40-core CPU is relatively less efficient these days. Easier said, the total performance of the chips increases as multiple agents are run instead of just a single agent.
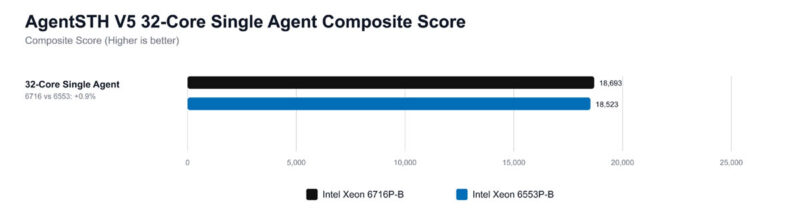
One other one we wanted to look at is the performance of the chips at different core counts and a single agent. We have 32 cores here and a composite score for the CPU across all subtests. We are using those 32 cores just as a standard here to make it easier to compare.
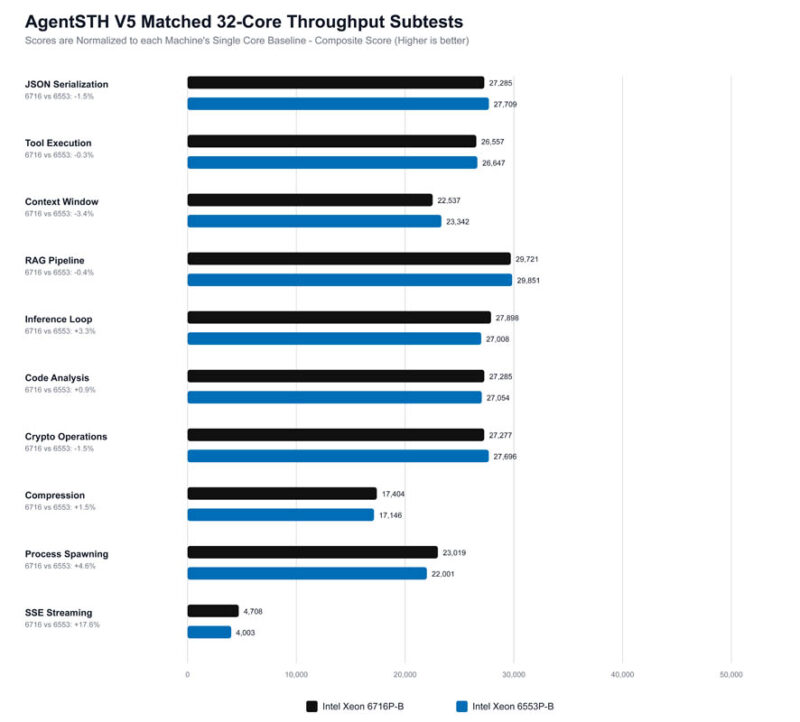
Overall, the results are very close, which is to be expected given that they are the same CPU core generation. Since we are using 32 cores on 36 and 40 core CPUs, sometimes bits like how much of a workload fits in the shared L3 cache or boost clocks running more often or at higher frequencies actually matter quite a bit. We also have a set of tests that is more focused on coordination tasks.
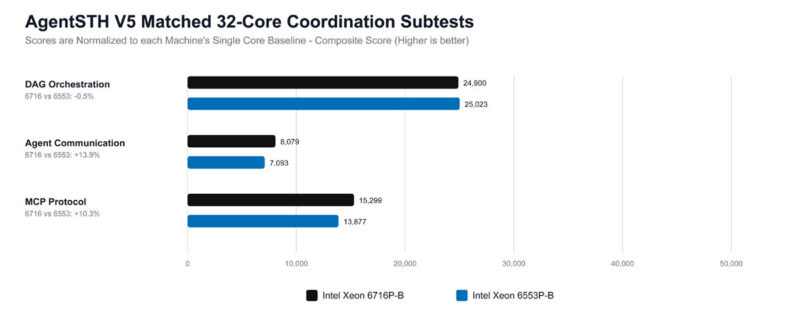
Here, the DAG orchestration is very close, which we would expect. Once the workload turns into queue traffic, RPC framing, and mailbox fan-in/fan-out, the Xeon 6716P-B seems to keep more of that metadata hot, leading to better results.

What we are seeing here suggests that the Xeon 6716P-B performs better when threads repeatedly revisit related state. Once the workload becomes broader, allocator and hash-table churn, the Xeon 6553P-B platform still looks stronger in this V5 data.
This is something we have been working on for some time in collaboration with one of the hyper-scale cloud providers’ performance gurus. Our observation a few years ago (over BBQ) was that CPU benchmarking often runs one process per core or per system, but modern cloud CPUs run multiple simultaneous workloads. This is just the first step in getting there. The goal is to turn this into something that we can release for folks so they can run easily. We are also exploring just doing a Geekbench-style distribution and providing pre-built binaries to make it easy for folks. Next, let us get to power consumption.



 to provide 8x 25GbE){kind=link}
This is the best server review you’ve done in the last year
What tool do you use for the core-to-core latency?
@Nikolay it’s an open-source tool called core-to-core-latency written in Rust
On the one hand the 8x25GbE (and a way to expand to 16) makes this seem like an interesting network-focused server — maybe a box doing load balancer duties and firewall for a bunccollection of servers behind it, maybe other tasks like caching/serving static stuff. You can get much better RAM/storage/compute density but you often don’t need that for those sorts of tasks. On the other hand, with 40C it feels like it ought to have more work to do than just that!
Also, the clock stuff is just neat!
@David Thanks for the info!
Is the datacenters also leaving VGA? Wow!
And 25gb/SPF28 NICs
What the world coming to?