
Recently we had a number of folks ask about Numenta. The company touts itself as being able to efficiently manage data on CPUs leading to some eye-popping performance figures. What is more, the company does not need large batch sizes to generate fast AI inference figures. Instead, it is using features like Intel AMX and AVX-512 together, plus software managing sparsity, to speed up AI inference.
A few weeks ago, Intel put together a brief on the solution since Numenta is doing AI inference using its custom instructions and asked if I wanted to do a piece on it. Then I saw the presentation at Hot Chip 2023, and I was one of the folks in the audience who thought the presentation was cool, so I said I would do it. As such, we are going to say Intel is sponsoring this piece, but most of the information is from Hot Chips.
Numenta Has the Secret to AI Inference on CPUs like the Intel Xeon MAX
Numenta has been around for a long time. It was founded in 2005 by Jeff Hawkins and Donna Dubinsky. For the readers out there, Jeff’s book “A Thousand Brains” is currently Amazon’s #12 best seller in Computer Science (Audible Books & Originals) and #53 in Artificial Intelligence & Semantics. (Amazon Affiliate Link.) The company’s goal is one we have heard many times before, which is to apply more of the way the brain works to AI problems.
This is probably not the official tagline, but think of it as neuroscience-inspired AI. Since the human brain uses something like 20W and is able to out-pace computers that use order of magnitudes more power than that, it is a common theme in the industry. Today’s computers are designed for dense compute. The human brain is designed for a lot of sparse compute. If you are not familiar with dense versus sparse compute here, an imperfect but quick mental model is to think of dense compute as trying to compute every permutation and sparse compute as computing only the most relevant and impactful combinations.
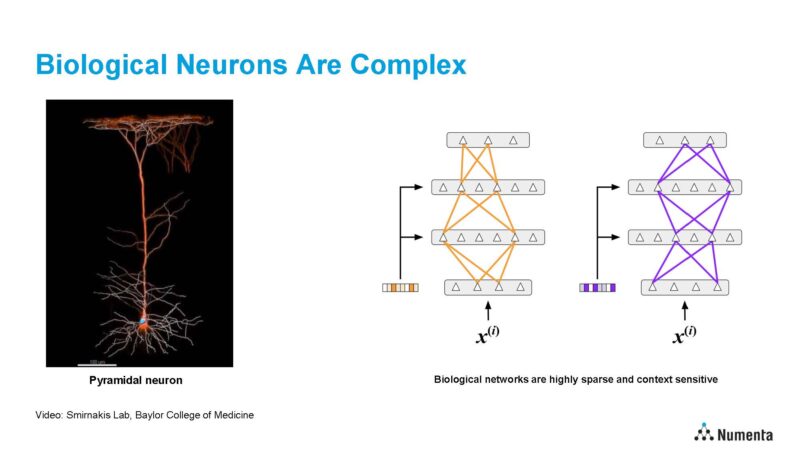
Neurons are complex, but the brain works in a realm of ultra-sparsity. Biological brain learning is dynamic and sparse, connections are sparse, activations and routings are sparse, and so forth. Brains also utilize contextual routing. When an input comes in, the brain determines the highly sparse part of the network that is going to be relevant, and then routes based on the input and context. Today, most organizations are using more of a brute force dense computation for AI.
Numenta’s work years ago with Xilinx showed two orders of magnitude in throughput, latency, and better power efficiency with similar accuracy. Now, the company is applying its algorithms to new CPU hardware. Numenta found that it can get ultra sparse, removing 90% of the weights while delivering similar accuracy.
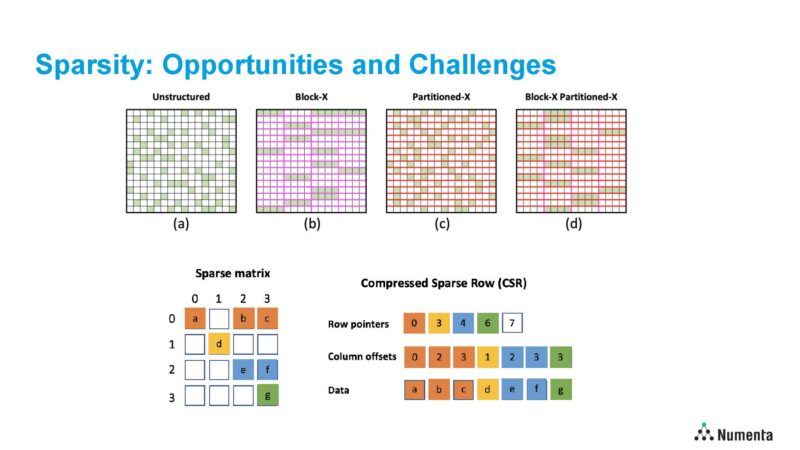
CPUs and GPUs today are designed for dense matrix multiply compute. These more general-purpose processors have relatively deep pipelines, high clock speeds, and big vector engines, so data needs to be staged to fill those compute resources. Sparsity is designed to deliver the opposite, less data to compute.

Sparsity is a huge challenge for modern CPUs and GPUs. Modern CPUs/ GPUs have deep pipelines and big vector engines that need to be consistently filled to run efficiently. For a great example of this, Numenta shared the optimized Intel Math Kernel Library (MKL) using AVX-512 and 1024×1024 data matrix. Here CSR (Compressed Sparse Row) is unstructured sparsity and BSR is block-structured sparsity. 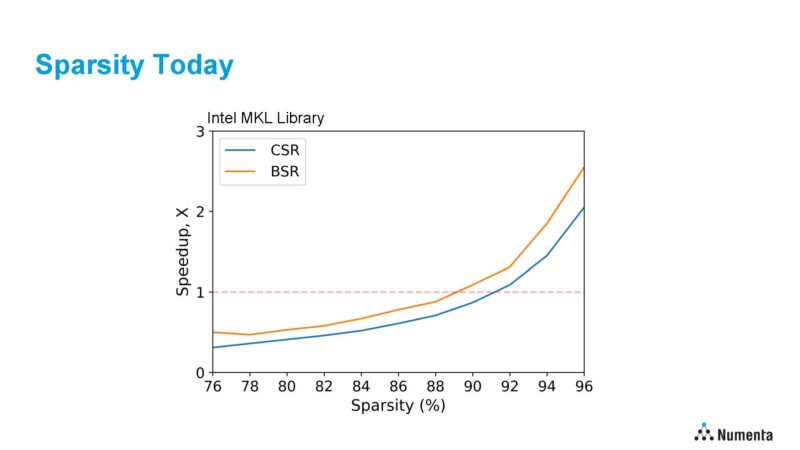
Numenta HotChips 2023 Sparsity In 2023The CPU needs ~90% sparsity using AVX-512 and Intel MKL to break even by just running a dense matrix. That is one of the key challenges. Sparsity is a well-known path to increasing performance, but modern CPUs suck at using sparsity because they are designed for dense compute.

That is Numenta’s focus point. Fixing the efficiency of sparse compute in LLMs and other large AI models but with a catch. Instead of building a domain-specific AI accelerator, the company is focused on bringing better performance to more general-purpose silicon.
Numenta’s approach (it says) works on CPUs and GPUs, but the company had to prioritize, so it went after the Intel Xeon CPUs since those are still the most plentiful in the market. The previous Numenta product version used AVX-512. The new product uses AVX-512 plus AMX. We did a piece on AMX with pre-production silicon about a year ago, but we did not use Numenta at the time.
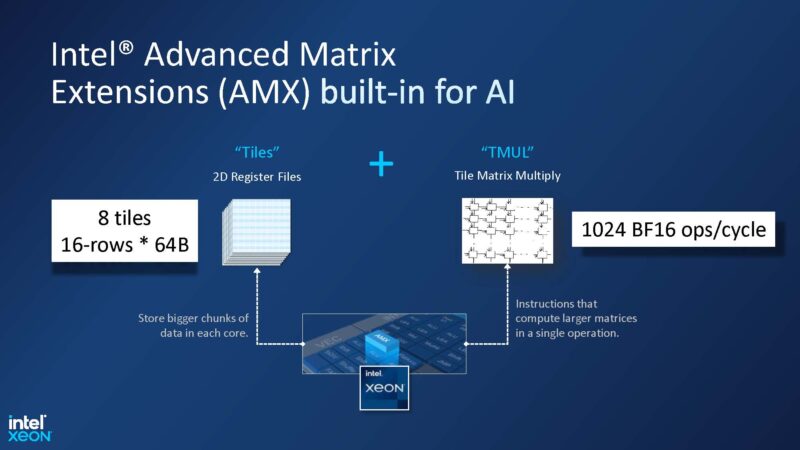
Here is some of the secret sauce. Numenta is using AVX-512 and AMX together. As an example, AMX outputs into FP32 so AVX-512 can be used to downconvert FP32 to BF16 to feed into AMX again. Numenta says one of the big challenges is that in both the AVX-512 and AMX cases, the assumption in the hardware is that they are designed for dense matrix multiplication.

Numenta’s approach is to handle the complexity of sparsity in software, then use the AVX-512 and AMX to do dense math. Or another way to put it, Numenta is abstracting away sparsity so that the wide compute units can continue to operate on dense data. That keeps the hardware running at nearly full speed avoiding the situation where we need 90% sparsity or more to get a speedup.

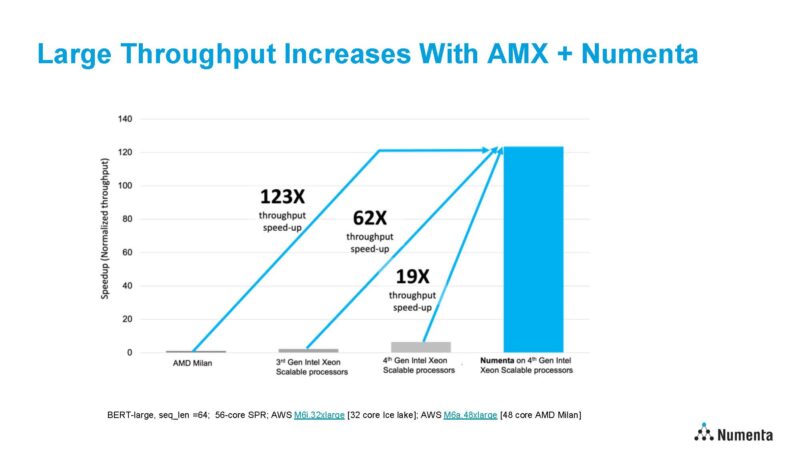
In Intel’s case study on Numenta and Sapphire Rapids with AMX, had a number of performance comparison points that showed a massive speed-up. We wish that Intel-Numenta also did testing on Genoa, Bergamo, and Genoa-X for a more complete picture. AMD’s EPYC parts do not have AMX, but it would have been a more relevant comparison point to Sapphire Rapids.
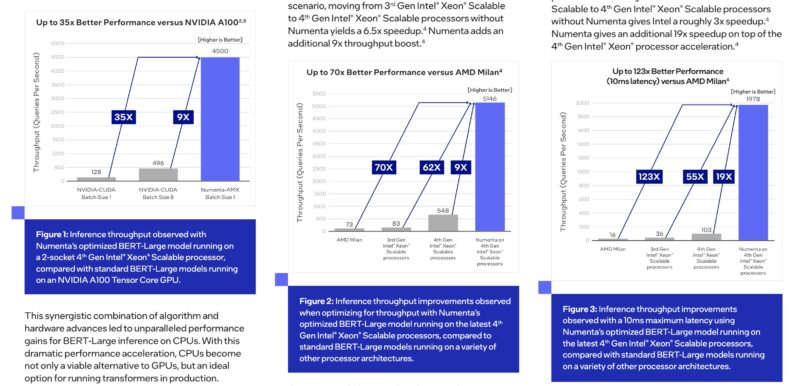
During its HC2023 talk, Numenta showed BERT-Large with 3rd Generation Xeon Scalable “Ice Lake” not “Cooper Lake“, Milan, Sapphire Rapids – 19x versus Intel AMX with MKL.
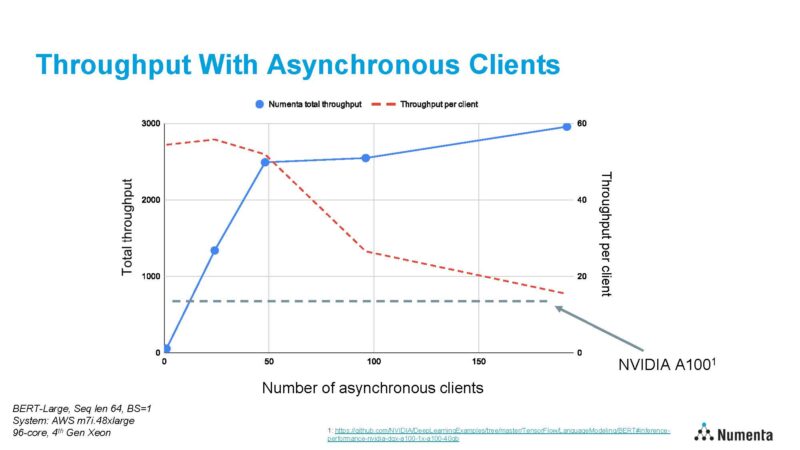
Here is an interesting one. Numenta took a workload that NVIDIA reported A100 performance figures on, and ran it on a dual socket 48-core Sapphire Rapids server on AWS. It saw linear scaling up to 48 cores. Each client is running its own BERT-Large instance so it puts pressure on cache and memory subsystems. In either case, it is faster than the NVIDIA A100.
I have to admit, with scaling like that, I would want to see what a Xeon MAX 9480 HBM-enabled part would do in single and dual socket mode. We returned our test system and we will have a piece on the Intel Developer Cloud next month, so hopefully, new numbers can come out on those chips (Do 56 cores help? Is a single socket better? Does HBM have an impact?)
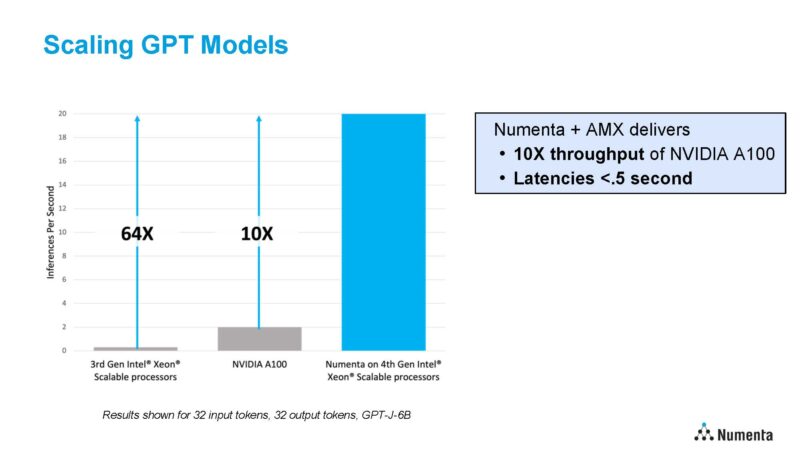
Generative AI can have its place but it has higher costs. So the goal is also to shift the cost curves of achieving accuracy by changing the compute requirements for models.
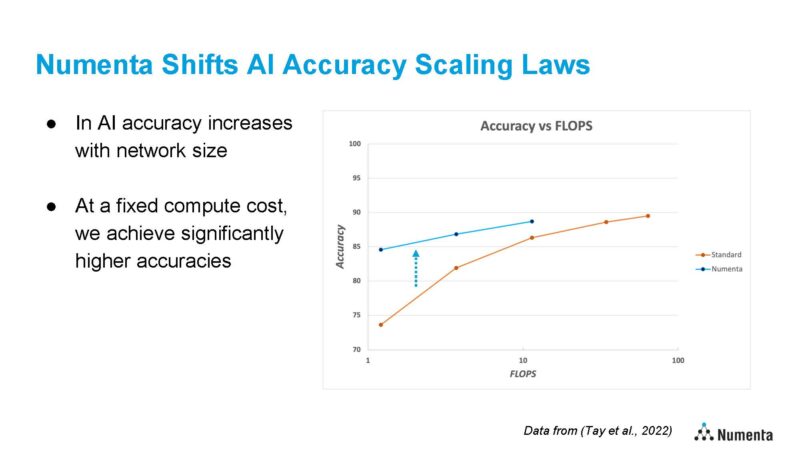
One of the cool bits here was that Numenta has also run on Intel Xeon MAX CPUs, and found that on larger models that are memory bandwidth constrained, they can get up to 3x throughput improvements.

As a fun one, our Xeon MAX article was written and the video was almost done when I saw this.
It was neat to see some real-world non-HPC use cases for Xeon MAX while doing a piece on it.
Final Words
Since Hot Chips 2023, Numenta productized this solution with a scalable and secure LLM service for things like sentiment analysis, summarization, Q&A, document classification, content creation, and code generation. They call this NuPIC or the Numenta Platform for Intelligent Computing.
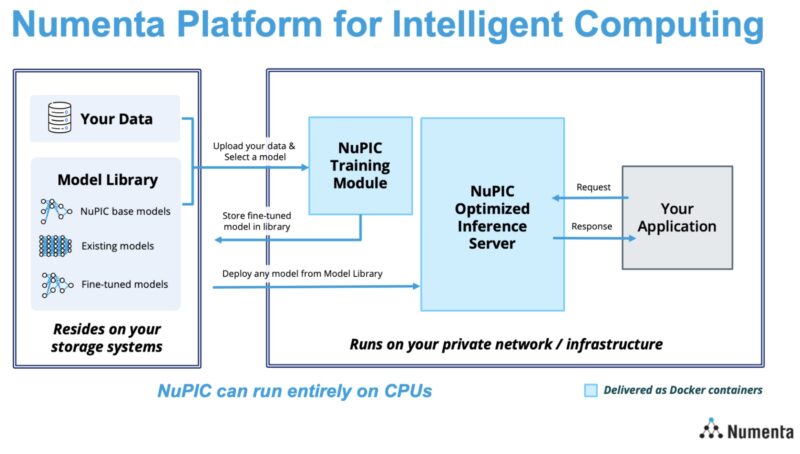
It delivers the service via docker containers and it can run on a company’s private infrastructure to keep data safe.
Hot Chips is very cool because there are a lot of very smart people in the same room. I was sitting next to Bill Dally after his keynote watching these presentations as an example. The audience was very excited about Numenta’s solution because it solved the problem of AI inference using CPUs that were already commonly deployed, or perhaps better said, easier to get ahold of than supply-constrained NVIDIA GPUs, not-yet-released AMD GPUs, Intel Gaudi2 (that has become popular enough it is starting to see supply constraints) or other accelerators. This runs on standard servers.



{kind=link}
I guess being sponsored by Intel means you can’t even mention if this is compatible with AMD Epyc (and even faster?), as it’s AVX-512 compatible?
Mama – We mentioned that earlier Numenta worked with Xilinx (now AMD), showed Numenta’s performance charts mentioning that we would have liked to see not just EPYC Milan but also Genoa and others.
The bigger challenge is that AMD EPYC does not have AMX which is the key component.
At Hot Chips 2023 Numenta said they could work on other architectures (CPU/GPU), but it seemed like AVX-512 plus AMX were key enablers here.
I am not sure what else we could have done here.
Comments are closed.