
While the Intel Ponte Vecchio is a Spaceship of a GPU and that will be paired with the Intel Sapphire Rapids Xeon in the upcoming Aurora exascale supercomputer, work needs to happen today. The Aurora system is likely to be delivered next year as Intel reset expectations to Q2 2022. As a result, the DoE and Argonne National Laboratory picked HPE to add a new Polaris cluster to the mix.
New DoE Argonne Polaris Supercomputer
Michael E. Papka, director at the Argonne Leadership Computing Facility (ALCF) said: “Polaris is well equipped to help move the ALCF into the exascale era of computational science by accelerating the application of AI capabilities to the growing data and simulation demands of our users” (Source: Argonne)
Aside from the pretty cover photo, we got a few details on the cluster:
- 280x HPE Apollo Gen10 Plus systems
- 560x (2 per node) AMD EPYC 7002 “Rome” and EPYC 7003 “Milan” processors
- 2240x (4 per node) NVIDIA A100 GPUs
- HPE-Cray Slingshot interconnect (same as will be used on all three of the first exascale systems)
Something that is very interesting here is that the Argonne link to the HPE system went to the HPE Apollo 6500 Gen10 Plus that we covered in HPE Adds a Quartet of New AMD EPYC 7003 Servers.

This is quite interesting. HPE is likely using an 8x HGX A100 configuration we saw in our recent Inspur NF5488A5 8x NVIDIA A100 HGX platform review and the air and liquid-cooled Supermicro configurations we tested in Liquid Cooling Next-Gen Servers Getting Hands-on with 3 Options. With eight GPUs per node, this is most likely a “Delta” not a “Redstone” configuration.
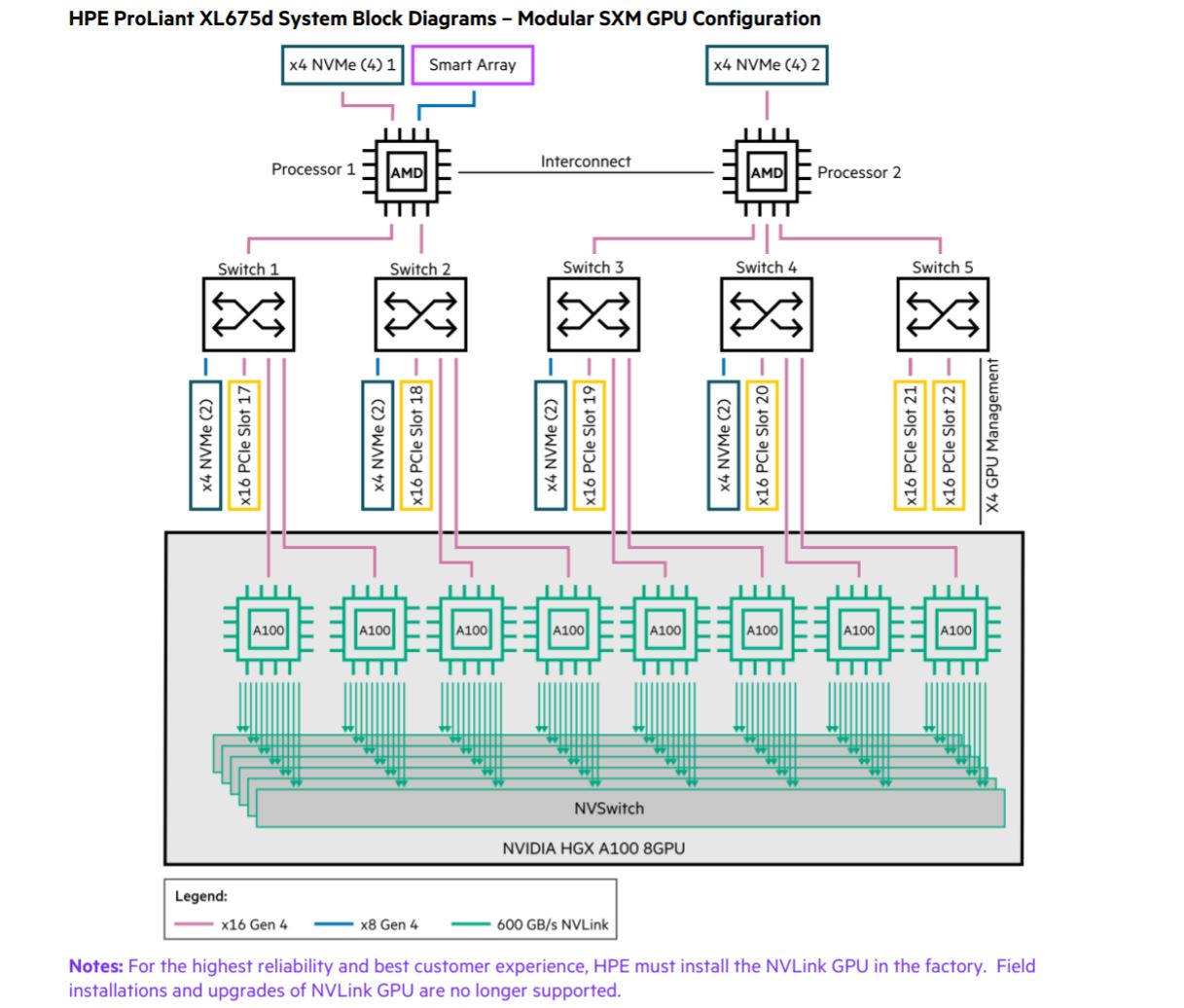
HPE has Apollo 6500 Gen10 Plus systems with NVIDIA Redstone, but these configurations have one CPU to one Redstone platform as can be seen in the diagram below.
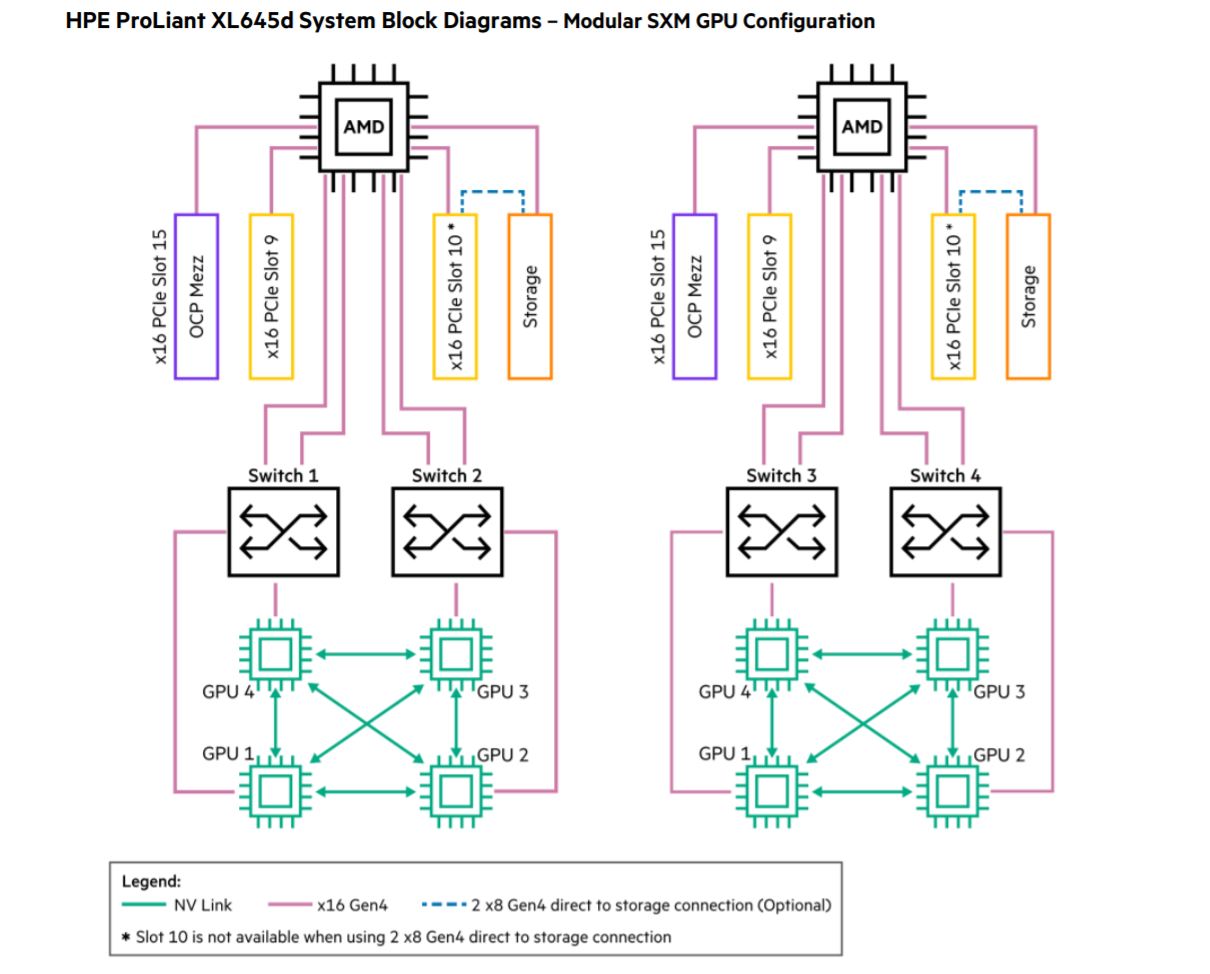
Our sense is that HPE has both options in the Apollo 6500 Gen10 Plus which is very cool.
Last week we did a Dell EMC PowerEdge XE8545 Review AMD EPYC and NVIDIA Redstone Server and several readers/ YouTube viewers asked why one would purchase a system with four NVIDIA A100 GPUs instead of eight GPU systems. Typically in HPC applications, like the Polaris cluster will be used for, having direct CPU to GPU connections is preferable to using a PCIe switch. Also, often DDR4 bandwidth and CPU core counts are designed for targeted ratios with the GPUs.
Here is how this Dell EMC PowerEdge Redstone platform is set up.

Of course, the PowerEdge we looked at is air-cooled and the Apollo 6500 is a more flexible platform, but the basic CPU/ GPU/ memory architecture we would expect to be similar.
We suspect Argonne is using rear-door heat exchangers in this installation.
Final Words
Overall, let us be clear, Polaris is a relatively small cluster compared to Aurora. For some context, a few weeks ago in the STH lab, we had just over 30 NVIDIA A100 GPUs and many more AMD EPYC 7002/7003 CPUs running in systems. In the old lab, we did not have the capacity to run even a small portion of a modern top 10 supercomputer and that was enough to be around 2% of what is being deployed with Polaris. It is still a good win for HPE, AMD, and NVIDIA.
Editor’s Note: Updated to make more clear.



{kind=link}
Hi Patrick,
2240 GPUs divided by 280 nodes equals 8 GPUs per node not 4. Or am I confusing nodes with enclosures?
Could you make an educated guess what such a system would cost? You mentioned ~ 150k per node ( ~42 million for 280 nodes), how much money would you need to add for storage and networking?
— Max
I don’t understand the need for a switch between each CPU and the corresponding 4-GPU cluster.
Max – you are right. I think a bit got very unclear there during editing. We had a truck arrive with the last parts *hopefully* for the new studio. Hopefully, the edit helps.
On cost, that is pretty hard to say. There are storage, networking, but also software and professional services to think about as well and the pricing of this class of machine is often quite different.
Comments are closed.