
Recently we have been running a small series looking at some of the platform trends in servers over the last decade. In this article, we are going to look at the per-socket and per-core memory bandwidth growth over time. This is a follow-up to both our Guide DDR DDR2 DDR3 DDR4 and DDR5 Bandwidth by Generation and Updated AMD EPYC and Intel Xeon Core Counts Over Time pieces. This is one will tie the two together a bit more.
Memory Bandwidth Per Socket and Per Core Over Time
First, let us take a look at the memory bandwidth over time. The theoretical memory bandwidth over time shown here is effectively memory channels per socket x memory bandwidth per DIMM.
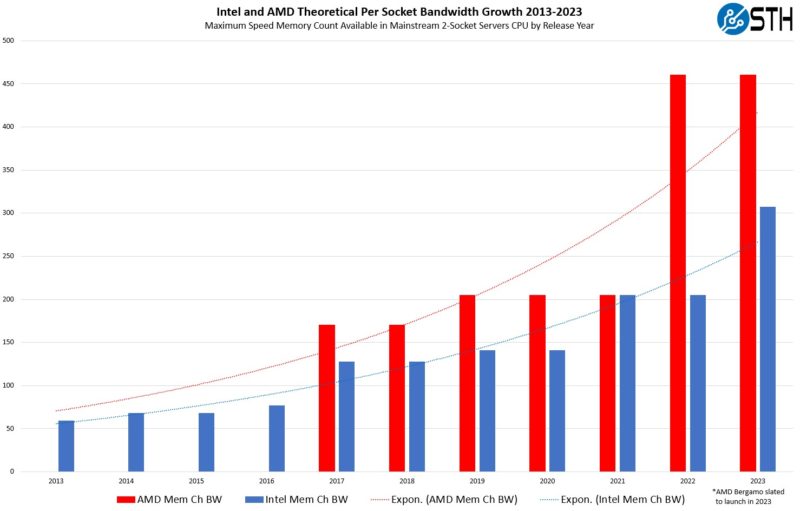
Here we can see the per-socket memory bandwidth increase by smaller increments whenever new incremental generations of memory in servers arrive (e.g. DDR4-2133 to DDR4-3200.) The larger jumps are when we start to see more memory channels plus updates to new memory generations. For example, in 2017 when Intel went from the 4-channel DDR4 to six channels, and then in 2021 when we had six to eight channels. When we discuss why DDR5 is important to servers, one can look to the AMD 2022 jump, where 8 to 12 channels and DDR4 to DDR5 transitions happened. Alternatively, simply the massive jump Intel saw moving from 8-channel DDR4-3200 to DDR5-4800.
While that looks like a promising chart, one has to also take into account the number of cores. Adding more cores means that the memory subsystem is servicing a greater pool of cores, and so memory bandwidth needs to scale. When we take the chart above and divide it by the maximum number of cores per socket, we see a interesting trendline:
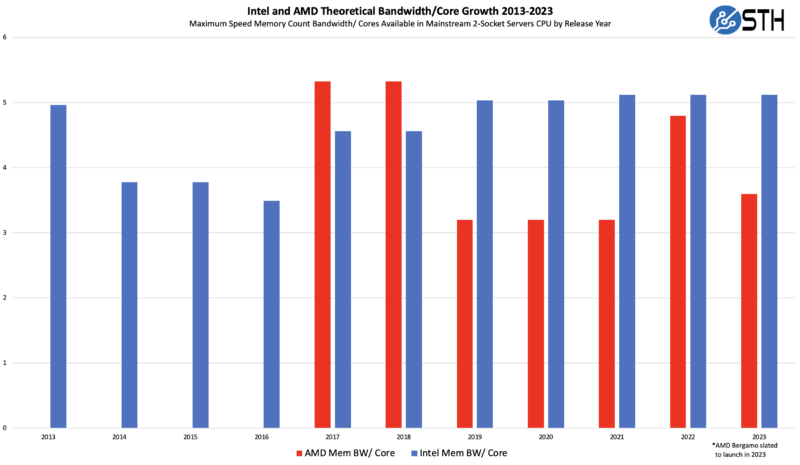
Intel has largely kept its memory bandwidth per core on an upward trend, from 2nd Generation Intel Xeon Scalable “Cascade Lake” to third generation “Ice Lake,” Intel went from 28 to 40 cores maximum per socket for around a 43% increase. At the same time, Intel increased memory channels by 33% and then transitioned from DDR4-2933 to DDR4-3200 for a bit over 9% more performance per channel. Those combine to keep the banalance. Likewise, the transition from Ice Lake to 4th Gen Intel Xeon Scalable “Sapphire Rapids” saw a 50% increase in core count (40 to 60) and a 50% increase in theoretical memory bandwidth per DIMM (DDR4-3200 to DDR5-4800.) That has created the flat line for Intel over those years.
For AMD, things are more complex. AMD doubled core counts from Naples to Rome, but the memory channels remained constant, and just the memory speed incremented. The most recent AMD EPYC 9004 “Genoa” added only 50% more cores but a massive increase in the memory substem’s channel count and speed. As a result, Genoa is off the trendline set by Rome and Milan. Bergamo we expect to launch in a few months. This will have 128 cores with reduced cache but in the same SP5 socket as Genoa. We are using the DDR5-4800 figure here, but there is a chance AMD may get its memory controllers running faster for Bergamo.

Again, we are looking at top-end SKUs. If one has a 64 core AMD Naples to Genoa or 16 core E5-2600 V3 to Sapphire Rapids there will be a massive delta in memory bandwidth per core over generations.
For its part, Intel has its new Xeon Max series with integrated HBM to help provide lower capacity but higher bandwidth memory near the CPU cores. Companies like NVIDIA (Grace), AMD (MI300), and Apple (M1/ M2 lines) will all be co-packaging memory with CPUs/ GPUs by the end of 2023.

This type of architecture is designed to increase memory bandwidth that otherwise has remained fairly constant in a range.
Final Words
We hope this provides at least some view of how memory bandwidth per socket and memory bandwidth per core has evolved. There is, of course, another component to this: performance. While we are looking at bandwidth per core, the performance per core has increased by 2.5-3x over the past decade. We will have more on that in an upcoming piece on DDR5.
Some like to go back to the 1970’s with charts like this. Since servers are often purchased new at least one generation prior to the current newest on-market hardware, our sense is that the Ivy Bridge-EP/ Haswell-EP (Intel Xeon E5-2600 V2/V3) generation is probably either at the limit of what most folks are upgrading or have recently upgraded. Many vendors tell us that the Intel Xeon E5-2600 V4 and 1st Gen Xeon Scalable platforms are some of the most intense upgrade projects at this point. A decade just feels like a more relatable time period to the hardware that is in service, plus a buffer of what has just been replaced and what the next upgrade cycle will be.
We hope folks these types of charts are useful for explaining industry trends to colleagues.



{kind=link}
Quite interesting…I’ve been wondering well how Intel & AMD have been doing on a memory bandwidth per core basis, for the last few years as core counts shot up.
Yes lots of cashing helps (although SRAM is not scaling as well at 7nm..5nm…Yikes!).
But one does wonder how many memory channels will be sufficient to “feed the beast”, as core counts per socket keep increasing.
Too early for “64GB ought to be enough for anybody” ?
Would be interesting to update your charts with IBM POWER Series Memory bandwidths and Core counts……
Thank you Eric
Now if you could “just” add amount of cache per core to the memory bandwith :-)
I feel that this is kinda key information into how we see increase of the performance gen by gen, despite memory bandwith per core staying more or less the same
Can you use the HBM as the sole system memory? Do Windows and other programs need to support this or do they not see whether the memory is DDR or HBM?
Comments are closed.