
We are still catching up a bit from the last few weeks of announcements. At Intel Architecture Day 2021, Intel shed some more detail on its next-generation performance core codenamed “Golden Cove”. Golden Cove will be the base core that will be found in the upcoming Intel Alder Lake Hybrid Processor we covered at Hot Chips 33 and also the upcoming Intel Sapphire Rapids Xeon we expect in Q2 2022. On Alder Lake being a hybrid processor, that is due to the fact that Intel also will be using its “Gracemont” core that is its efficient core (think Atom lineage here), and combining them into a chip. We will go into Gracemont over the next few days but wanted to have a base reference point for Golden Cove.
Intel Golden Cove Performance x86 Core Detailed
We normally do not show cover slides. Something that stuck out reviewing these slides was that “x86 core” was stressed so many times. It is probably being used to differentiate versus its Intel Arc Alchemist GPU cores, and also its Mount Evans DPU IPU Arm Neoverse cores, but re-reading this it is stressed so much I almost expected there to be a “Performance Arm Core” or “Performance RISC-V Core” set of slides after.

Just as an example, here is the next slide the company showed at Intel Architecture Day 2021 where “x86 core” is featured again. The key here is that Golden Cove is the performance core that is designed to be the successor to modern desktop/ workstation Core and server Xeon Scalable CPU cores.

Intel now has competition on a few fronts. Not only does it have competition from AMD with Zen3 and future core designs, but it also has Arm in the data center. AMD has been pushing double-digit IPC gains recently, so Intel needs to deliver more than a 3-5% gen/gen improvement. As such, it is focusing on two areas. It is both creating a more robust execution core for standard workloads as well as creating an infrastructure to accelerate emerging workloads such as AI. In contrast, AMD has been focused on a more fast-follower strategy, letting Intel introduce a feature, and then introduce cores as software adoption ramps. Arm tends to focus on more specialized execution.

O the front end, we are not going to transcribe everything on these slides but the key is that Intel is making structures bigger to be able to do more in parallel. Intel also says that its branch prediction mechanism is improved. Not on here or the other slides, but this is a generation where we would also expect to see more speculative execution mitigations.

The out-of-order engine also go bigger to be able to do more per clock.

On the integer side, we got an additional execution port.

On the L1 cache side, we can see that the L1 cache got wider and faster.

On the L2 side, we can see that we have 1.25MB of L2 cache on the client part but 2MB on the data center (Sapphire Rapids part.) Since we focus more on the data center side, the Intel Xeon Ice Lake Edition had 1.25MB of L2 cache per core so the jump to 2MB is a 60% increase in size. That is massive.

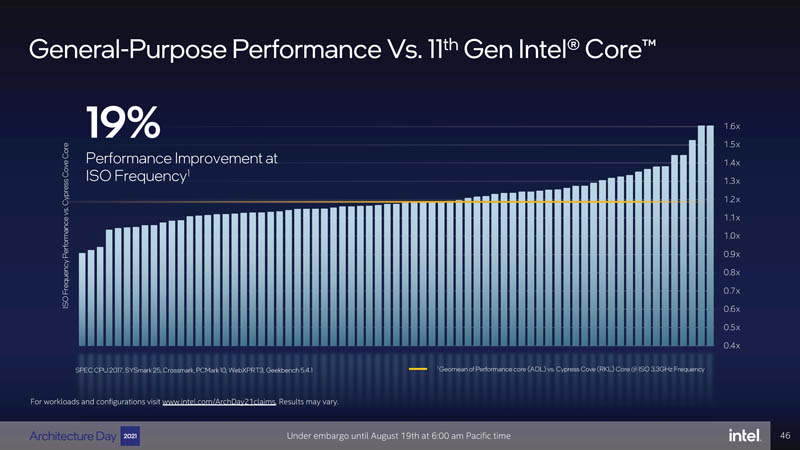
All this combines to give Intel what it says will be a 19% generational improvement on a clock for clock basis in general-purpose workloads.
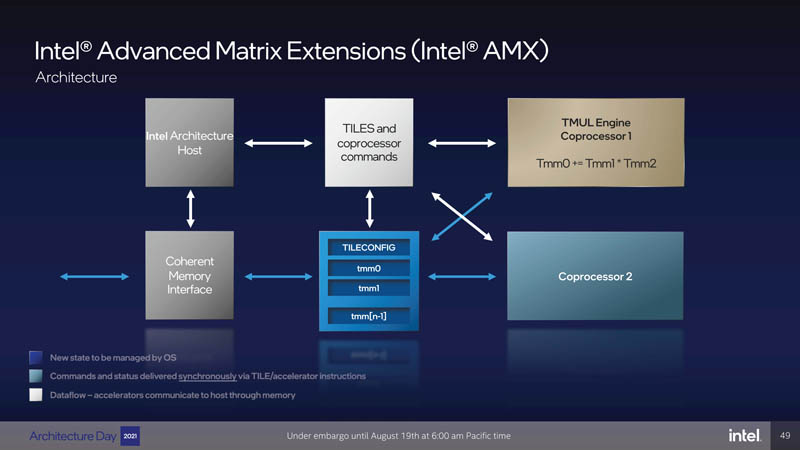
Intel has really focused on acceleration as it fell behind in terms of raw core count. Here, Intel has Advanced Matrix Extensions or Intel AMX that increases performance per clock versus the Intel DL Boost VNNI instructions. We typically see int8 used for inference workloads. Intel’s desire here is simple. If it can boost inference performance in the CPU, then it can make a case that a server will not need a (NVIDIA) GPU to run inferencing portions of server applications. Training is a different workload.

Intel actually focused on the data center Intel AMX implementation and how it works with TILES. Intel is trying to get a new execution model to boost performance here.

Eventually, Intel sees this TILES-based approach as moving beyond just a CPU (let us call this what it is) and is seemingly trying to tie this into a broader solution. At some point, Intel will need to offer AI inference co-processors as well, so they are thinking about that with this approach.
Here is the overall summary slide for the deck, again notice the x86 core being called out.
Intel is doing a lot in this generation to boost IPC which is extremely important for Golden Cove. On the desktop, it is being positioned as the high clock single-thread performance alternative to Gracemont. Gracemont can fit more cores into a smaller die area so Golden Cove needs to have a jump in performance to differentiate the two further.
Final Words
What has us very excited is that Intel is going to have both Golden Cove, this performance core as well as Gracemont coming. What is more, Intel is building a hybrid package approach into a mainstream part by integrating both to get more performance but also lower power execution. This is a new realm for Intel.

We cannot wait to see how Intel brings these Golden Cove cores to market with Alder Lake for the consumer market and Sapphire Rapids for the data center market over the next four quarters.


{kind=link}
Gotta hand it to Intel Marketing, the “19% Performance Improvement” slide looks as impressive as hell, but when I zoom in and look at it I find it means absolutely nothing.
STH coverage of Intel this time out has been mostly a slide show. I think it is beneath you guys. STH in the past has been one of the places a person could find real analysis.
Oh, Intel, please no. You have put link: For workload and configurations visit https://www.intel.com/ArchDay21claims on the slide and the link is account/pw protected. That’s quite a shame.
The chart would show more information if they labeled all the bars, but you’d have to zoom in pretty hard to read them. As it is it is more meaningful than simply a declaration if “19% IPC improvement.” If you go to the link listed in the slide http://www.intel.com/ArchDay21Claims you can go down a rabbit hole of the tests being used. They don’t have Golden Cove results but it looks like there are results from prior Xeon generations andyou can see the workloads being run and the server manufacturers and configurations used.
@Matt,
“As it is it is more meaningful than simply a declaration if “19% IPC improvement.” If you go to the link listed…”
“They don’t have Golden Cove results …”
So the unlabelled slide about 19% better perf has no results for the CPU the slide describes.
That is not more meaningful.
hoohoo, you are basically accusing Intel of fraud. If you don’t believe what they say then it doesn’t matter how much they say, you just won’t believe them, so why are you expressing it as the results are “meaningless” instead of just saying they are bogus? Best to wait for the processor to come out, then. But, isn’t it more likely they did the tests and they just haven’t put the information up yet? After all they released a similar graphic before comparing Sunny Cove to Skylake and I’m willing to bet if there was a discrepancy when the product came out people would have noted it. Before you answer, the information is now up.
” Testing as of May 28, 2021.
Intel® Core™ i9-11900k, 4x16GB 1R DDR4 UDIMM 2DPC 3200 Max Memory Frequency, Samsung 980 Pro 500GB PCIe SSD, WIN 10 20H2 19042.ent.rx64.789, High Performance Power Plan, 1920×1080 display resolution
Alder Lake Desktop S801 , RVP board with 2x16GB 1R DDR5 UDIMM 1DPC, 4400 Max Memory Frequency, Samsung 980 Pro 500GB PCIe SSD, WIN 10 20H2 19042.ent.rx64.508_?update.906, High Performance Power Plan, 1920×1080 display resolution
Based on overall scores and individual subcomponent scores on: SYSmark 25, CrossMark, PCMark 10, SPEC CPU 2017, WebXPRT 3, Geekbench 5.”
So the information on the slide is almost complete. What’s missing is that the Alder Lake processor is using DDR5 while the 11th gen is using DDR4 and that all those extra bars apparently represent the subtests that comprise the listed tests. But I suppose you will say that since Intel didn’t label which bar was which, or Intel hasn’t given the specific system specifications involved, they are still lying about something. Why did Intel choose the specific tests they chose, after all? Is the average weighted based on the number of subtests? Is that appropriate?
Yes, any internal benchmarks must be taken with a grain of salt. That’s true. We must trust the manufacturer if we trust internal benchmarks or performance promises. But this slide isn’t any more “meaningless” than any other slide of internal benchmarks. If Intel promises an IPC uplift of a certain amount and that is not in the same ballpark as reality when the processor comes out then it will reflect badly on the company. What’s “meaningful” is the promise, not the details behind an internal benchmark.
Comments are closed.